 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilling MIDI Velocity using U-Net Image Colorizer
Aug 11, 2025



Modern music producers commonly use MIDI (Musical Instrument Digital Interface) to store their musical compositions. However, MIDI files created with digital software may lack the expressive characteristics of human performances, essentially leaving the velocity parameter - a control for note loudness - undefined, which defaults to a flat value. The task of filling MIDI velocity is termed MIDI velocity prediction, which uses regression models to enhance music expressiveness by adjusting only this parameter. In this paper, we introduce the U-Net, a widely adopted architecture in image colorization, to this task. By conceptualizing MIDI data as images, we adopt window attention and develop a custom loss function to address the sparsity of MIDI-converted images. Current dataset availability restricts our experiments to piano data. Evaluated on the MAESTRO v3 and SMD datasets, our proposed method for filling MIDI velocity outperforms previous approaches in both quantitative metrics and qualitative listening tests.
Score-Informed BiLSTM Correction for Refining MIDI Velocity in Automatic Piano Transcription
Aug 11, 2025MIDI is a modern standard for storing music, recording how musical notes are played. Many piano performances have corresponding MIDI scores available online. Some of these are created by the original performer, recording on an electric piano alongside the audio, while others are through manual transcription. In recent years, automatic music transcription (AMT) has rapidly advanced, enabling machines to transcribe MIDI from audio. However, these transcriptions often require further correction. Assuming a perfect timing correction, we focus on the loudness correction in terms of MIDI velocity (a parameter in MIDI for loudness control). This task can be approached through score-informed MIDI velocity estimation, which has undergone several developments. While previous approaches introduced specifically built models to re-estimate MIDI velocity, thereby replacing AMT estimates, we propose a BiLSTM correction module to refine AMT-estimated velocity. Although we did not reach state-of-the-art performance, we validated our method on the well-known AMT system, the high-resolution piano transcription (HPT), and achieved significant improvements.
Music Tempo Estimation on Solo Instrumental Performance
Apr 25, 2025Recently, automatic music transcription has made it possible to convert musical audio into accurate MIDI. However, the resulting MIDI lacks music notations such as tempo, which hinders its conversion into sheet music. In this paper, we investigate state-of-the-art tempo estimation techniques and evaluate their performance on solo instrumental music. These include temporal convolutional network (TCN) and recurrent neural network (RNN) models that are pretrained on massive of mixed vocals and instrumental music, as well as TCN models trained specifically with solo instrumental performances. Through evaluations on drum, guitar, and classical piano datasets, our TCN models with the new training scheme achieved the best performance. Our newly trained TCN model increases the Acc1 metric by 38.6% for guitar tempo estimation, compared to the pretrained TCN model with an Acc1 of 61.1%. Although our trained TCN model is twice as accurate as the pretrained TCN model in estimating classical piano tempo, its Acc1 is only 50.9%. To improve the performance of deep learning models, we investigate their combinations with various post-processing methods. These post-processing techniques effectively enhance the performance of deep learning models when they struggle to estimate the tempo of specific instruments.
Pseudo Strong Labels from Frame-Level Predictions for Weakly Supervised Sound Event Detection
Jan 07, 2025Weakly Supervised Sound Event Detection (WSSED), which relies on audio tags without precise onset and offset times, has become prevalent due to the scarcity of strongly labeled data that includes exact temporal boundaries for events. This study introduces Frame-level Pseudo Strong Labeling (FPSL) to overcome the lack of temporal information in WSSED by generating pseudo strong labels from frame-level predictions. This enhances temporal localization during training and addresses the limitations of clip-wise weak supervision. We validate our approach across three benchmark datasets (DCASE2017 Task 4, DCASE2018 Task 4, and UrbanSED) and demonstrate significant improvements in key metrics such as the Polyphonic Sound Detection Scores (PSDS), event-based F1 scores, and intersection-based F1 scores. For example, Convolutional Recurrent Neural Networks (CRNNs) trained with FPSL outperform baseline models by 4.9% in PSDS1 on DCASE2017, 7.6% on DCASE2018, and 1.8% on UrbanSED, confirming the effectiveness of our method in enhancing model performance.
Impact of Noisy Labels on Sound Event Detection: Deletion Errors Are More Detrimental Than Insertion Errors
Aug 27, 2024This study explores the critical but underexamined impact of label noise on Sound Event Detection (SED), which requires both sound identification and precise temporal localization. We categorize label noise into deletion, insertion, substitution, and subjective types and systematically evaluate their effects on SED using synthetic and real-life datasets. Our analysis shows that deletion noise significantly degrades performance, while insertion noise is relatively benign. Moreover, loss functions effective against classification noise do not perform well for SED due to intra-class imbalance between foreground sound events and background sounds. We demonstrate that loss functions designed to address data imbalance in SED can effectively reduce the impact of noisy labels on system performance. For instance, halving the weight of background sounds in a synthetic dataset improved macro-F1 and micro-F1 scores by approximately $9\%$ with minimal Error Rate increase, with consistent results in real-life datasets. This research highlights the nuanced effects of noisy labels on SED systems and provides practical strategies to enhance model robustness, which are pivotal for both constructing new SED datasets and improving model performance, including efficient utilization of soft and crowdsourced labels.
Sparks of Large Audio Models: A Survey and Outlook
Sep 03, 2023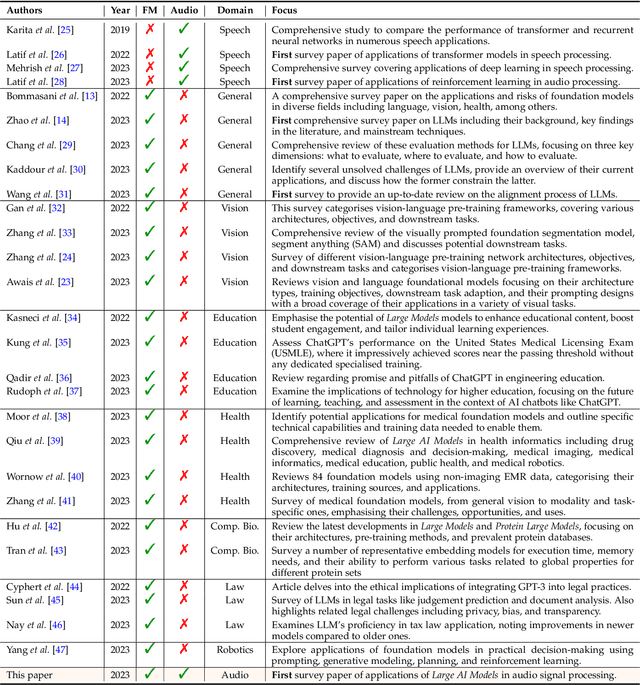
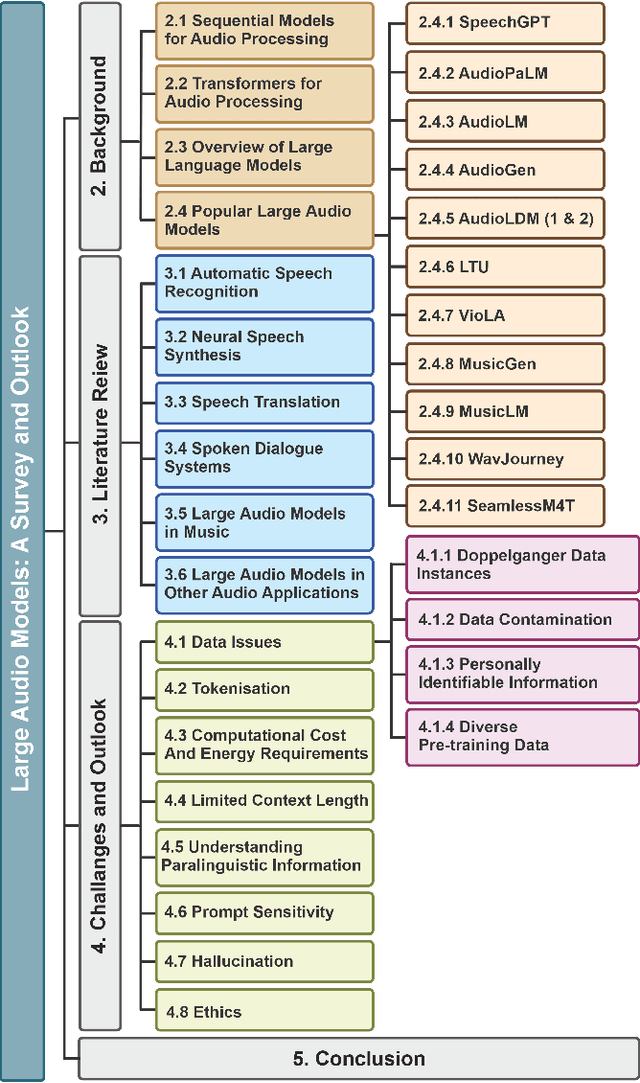
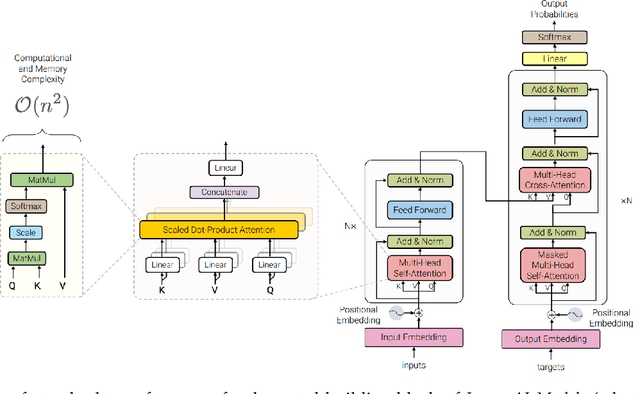
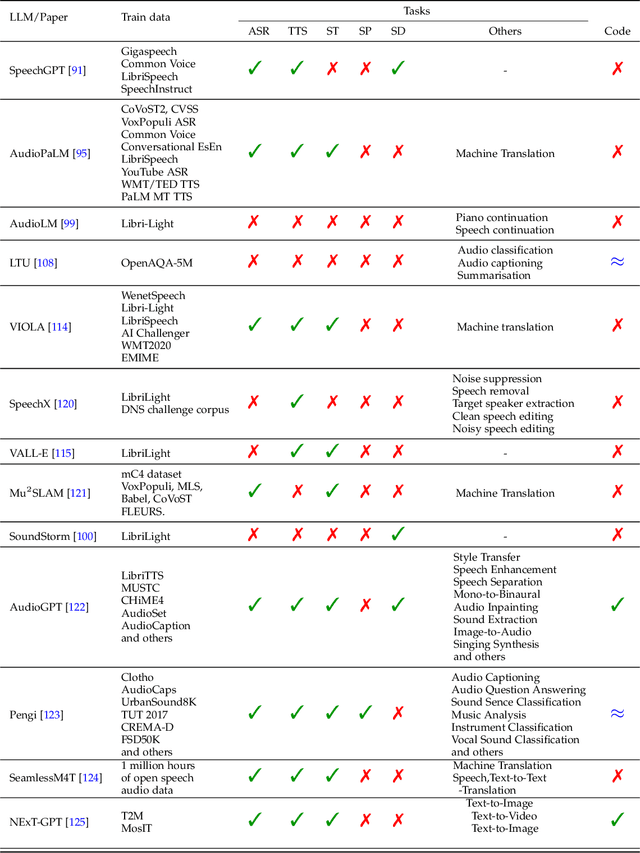
This survey paper provides a comprehensive overview of the recent advancements and challenges in applying large language models to the field of audio signal processing. Audio processing, with its diverse signal representations and a wide range of sources--from human voices to musical instruments and environmental sounds--poses challenges distinct from those found in traditional Natural Language Processing scenarios. Nevertheless, \textit{Large Audio Models}, epitomized by transformer-based architectures, have shown marked efficacy in this sphere. By leveraging massive amount of data, these models have demonstrated prowess in a variety of audio tasks, spanning from Automatic Speech Recognition and Text-To-Speech to Music Generation, among others. Notably, recently these Foundational Audio Models, like SeamlessM4T, have started showing abilities to act as universal translators, supporting multiple speech tasks for up to 100 languages without any reliance on separate task-specific systems. This paper presents an in-depth analysis of state-of-the-art methodologies regarding \textit{Foundational Large Audio Models}, their performance benchmarks, and their applicability to real-world scenarios. We also highlight current limitations and provide insights into potential future research directions in the realm of \textit{Large Audio Models} with the intent to spark further discussion, thereby fostering innovation in the next generation of audio-processing systems. Furthermore, to cope with the rapid development in this area, we will consistently update the relevant repository with relevant recent articles and their open-source implementations at https://github.com/EmulationAI/awesome-large-audio-models.
Investigating self-supervised learning for lyrics recognition
Sep 28, 2022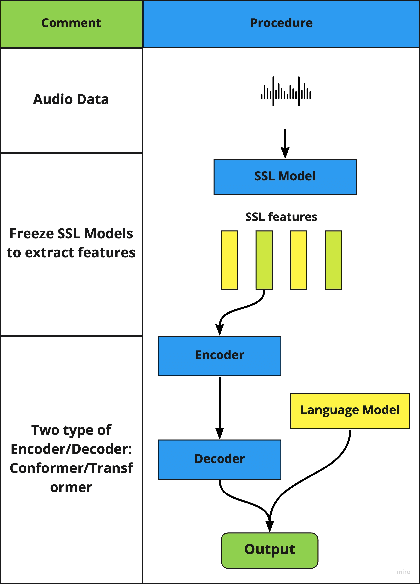
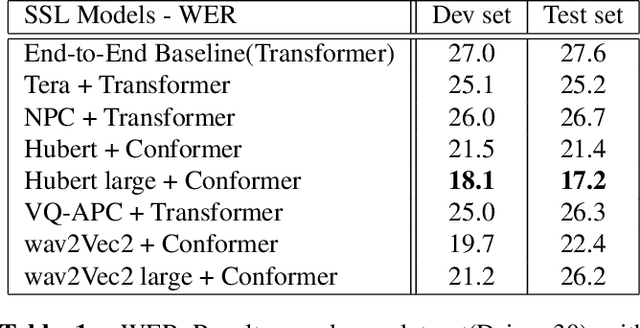
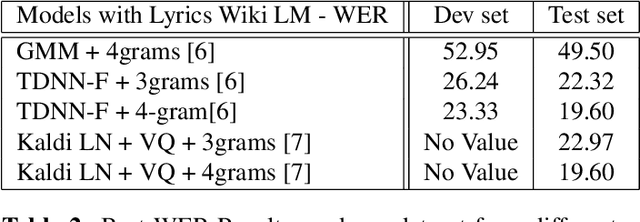
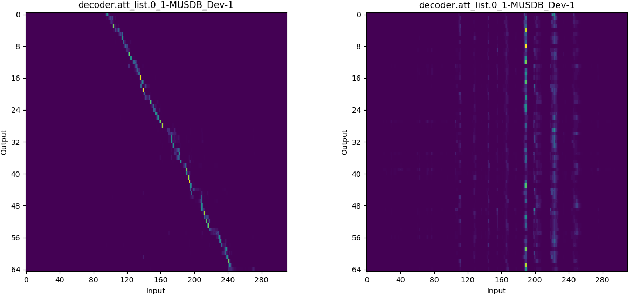
Lyrics recognition is an important task in music processing. Despite the great number of traditional algorithms such as the hybrid HMM-TDNN model achieving good performance, studies on applying end-to-end models and self-supervised learning (SSL) are limited. In this paper, we first establish an end-to-end baseline for lyrics recognition and then explore the performance of SSL models. We evaluate four upstream SSL models based on their training method (masked reconstruction, masked prediction, autoregressive reconstruction, contrastive model). After applying the SSL model, the best performance improved by 5.23% for the dev set and 2.4% for the test set compared with the previous state-of-art baseline system even without a language model trained by a large corpus. Moreover, we study the generalization ability of the SSL features considering that those models were not trained on music datasets.
Automated Sex Classification of Children's Voices and Changes in Differentiating Factors with Age
Sep 27, 2022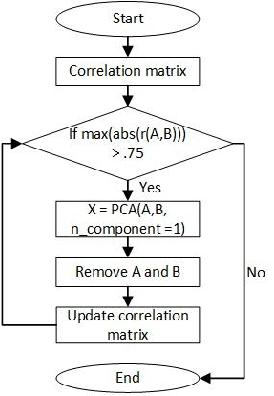
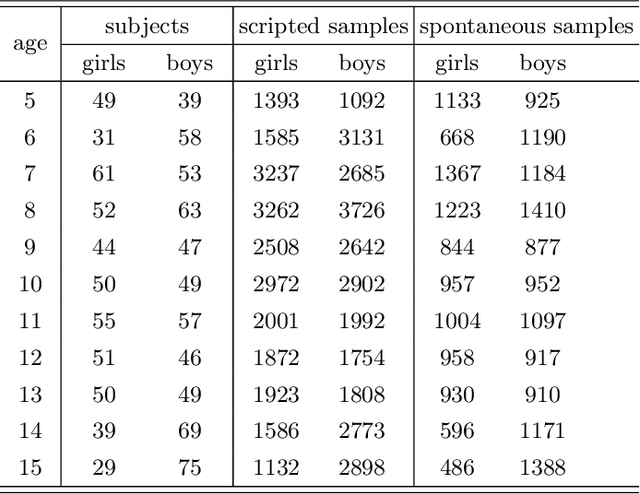
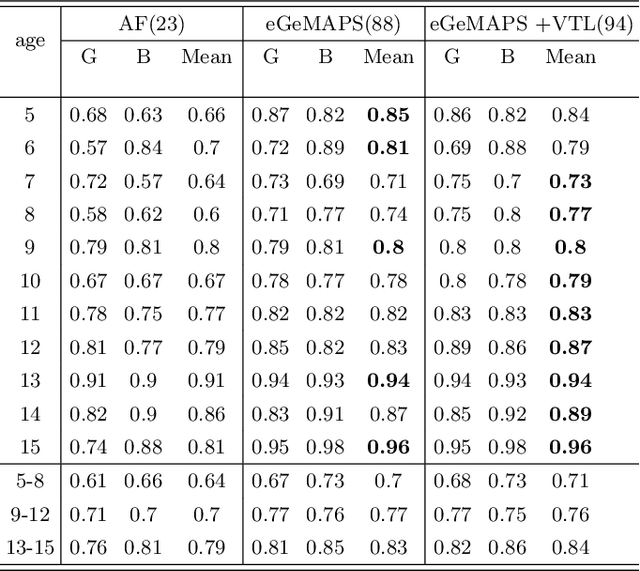
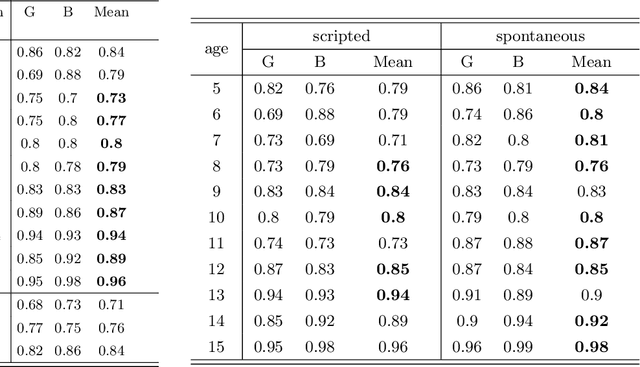
Sex classification of children's voices allows for an investigation of the development of secondary sex characteristics which has been a key interest in the field of speech analysis. This research investigated a broad range of acoustic features from scripted and spontaneous speech and applied a hierarchical clustering-based machine learning model to distinguish the sex of children aged between 5 and 15 years. We proposed an optimal feature set and our modelling achieved an average F1 score (the harmonic mean of the precision and recall) of 0.84 across all ages. Our results suggest that the sex classification is generally more accurate when a model is developed for each year group rather than for children in 4-year age bands, with classification accuracy being better for older age groups. We found that spontaneous speech could provide more helpful cues in sex classification than scripted speech, especially for children younger than 7 years. For younger age groups, a broad range of acoustic factors contributed evenly to sex classification, while for older age groups, F0-related acoustic factors were found to be the most critical predictors generally. Other important acoustic factors for older age groups include vocal tract length estimators, spectral flux, loudness and unvoiced features.
Spatio-Temporal Graph Representation Learning for Fraudster Group Detection
Jan 07, 2022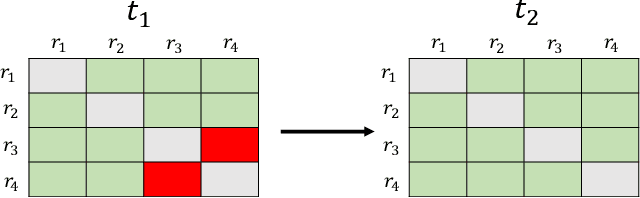

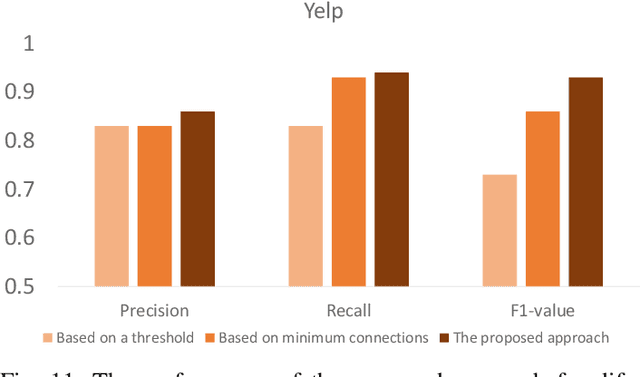
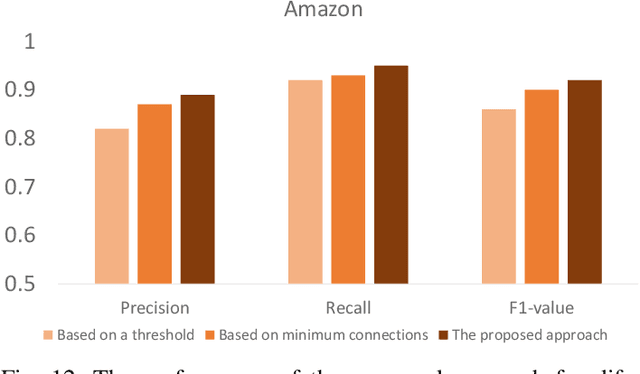
Motivated by potential financial gain, companies may hire fraudster groups to write fake reviews to either demote competitors or promote their own businesses. Such groups are considerably more successful in misleading customers, as people are more likely to be influenced by the opinion of a large group. To detect such groups, a common model is to represent fraudster groups' static networks, consequently overlooking the longitudinal behavior of a reviewer thus the dynamics of co-review relations among reviewers in a group. Hence, these approaches are incapable of excluding outlier reviewers, which are fraudsters intentionally camouflaging themselves in a group and genuine reviewers happen to co-review in fraudster groups. To address this issue, in this work, we propose to first capitalize on the effectiveness of the HIN-RNN in both reviewers' representation learning while capturing the collaboration between reviewers, we first utilize the HIN-RNN to model the co-review relations of reviewers in a group in a fixed time window of 28 days. We refer to this as spatial relation learning representation to signify the generalisability of this work to other networked scenarios. Then we use an RNN on the spatial relations to predict the spatio-temporal relations of reviewers in the group. In the third step, a Graph Convolution Network (GCN) refines the reviewers' vector representations using these predicted relations. These refined representations are then used to remove outlier reviewers. The average of the remaining reviewers' representation is then fed to a simple fully connected layer to predict if the group is a fraudster group or not. Exhaustive experiments of the proposed approach showed a 5% (4%), 12% (5%), 12% (5%) improvement over three of the most recent approaches on precision, recall, and F1-value over the Yelp (Amazon) dataset, respectively.
Social Fraud Detection Review: Methods, Challenges and Analysis
Nov 10, 2021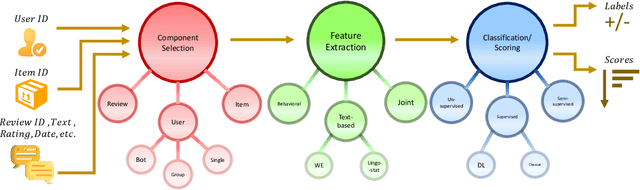
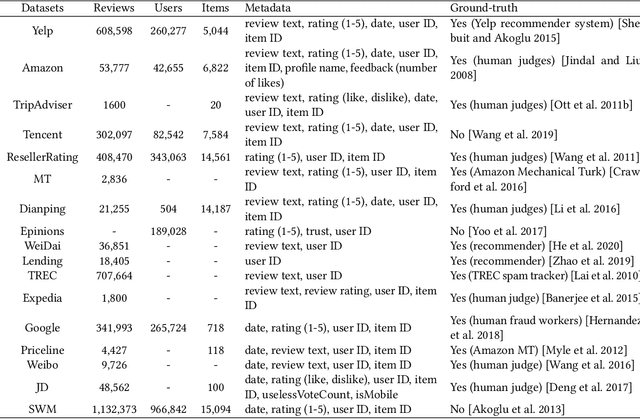
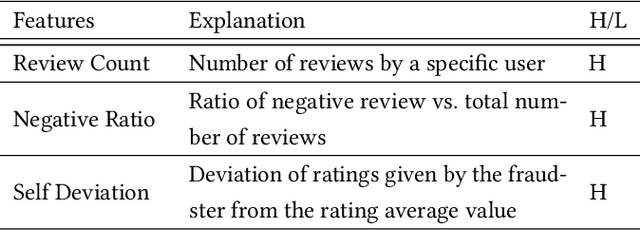
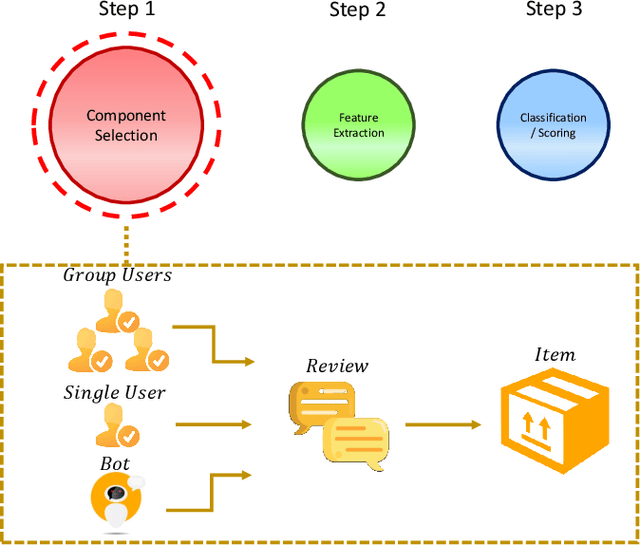
Social reviews have dominated the web and become a plausible source of product information. People and businesses use such information for decision-making. Businesses also make use of social information to spread fake information using a single user, groups of users, or a bot trained to generate fraudulent content. Many studies proposed approaches based on user behaviors and review text to address the challenges of fraud detection. To provide an exhaustive literature review, social fraud detection is reviewed using a framework that considers three key components: the review itself, the user who carries out the review, and the item being reviewed. As features are extracted for the component representation, a feature-wise review is provided based on behavioral, text-based features and their combination. With this framework, a comprehensive overview of approaches is presented including supervised, semi-supervised, and unsupervised learning. The supervised approaches for fraud detection are introduced and categorized into two sub-categories; classical, and deep learning. The lack of labeled datasets is explained and potential solutions are suggested. To help new researchers in the area develop a better understanding, a topic analysis and an overview of future directions is provided in each step of the proposed systematic framework.