 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-Informed BiLSTM Correction for Refining MIDI Velocity in Automatic Piano Transcription
Aug 11, 2025MIDI is a modern standard for storing music, recording how musical notes are played. Many piano performances have corresponding MIDI scores available online. Some of these are created by the original performer, recording on an electric piano alongside the audio, while others are through manual transcription. In recent years, automatic music transcription (AMT) has rapidly advanced, enabling machines to transcribe MIDI from audio. However, these transcriptions often require further correction. Assuming a perfect timing correction, we focus on the loudness correction in terms of MIDI velocity (a parameter in MIDI for loudness control). This task can be approached through score-informed MIDI velocity estimation, which has undergone several developments. While previous approaches introduced specifically built models to re-estimate MIDI velocity, thereby replacing AMT estimates, we propose a BiLSTM correction module to refine AMT-estimated velocity. Although we did not reach state-of-the-art performance, we validated our method on the well-known AMT system, the high-resolution piano transcription (HPT), and achieved significant improvements.
Filling MIDI Velocity using U-Net Image Colorizer
Aug 11, 2025



Modern music producers commonly use MIDI (Musical Instrument Digital Interface) to store their musical compositions. However, MIDI files created with digital software may lack the expressive characteristics of human performances, essentially leaving the velocity parameter - a control for note loudness - undefined, which defaults to a flat value. The task of filling MIDI velocity is termed MIDI velocity prediction, which uses regression models to enhance music expressiveness by adjusting only this parameter. In this paper, we introduce the U-Net, a widely adopted architecture in image colorization, to this task. By conceptualizing MIDI data as images, we adopt window attention and develop a custom loss function to address the sparsity of MIDI-converted images. Current dataset availability restricts our experiments to piano data. Evaluated on the MAESTRO v3 and SMD datasets, our proposed method for filling MIDI velocity outperforms previous approaches in both quantitative metrics and qualitative listening tests.
Music Tempo Estimation on Solo Instrumental Performance
Apr 25, 2025Recently, automatic music transcription has made it possible to convert musical audio into accurate MIDI. However, the resulting MIDI lacks music notations such as tempo, which hinders its conversion into sheet music. In this paper, we investigate state-of-the-art tempo estimation techniques and evaluate their performance on solo instrumental music. These include temporal convolutional network (TCN) and recurrent neural network (RNN) models that are pretrained on massive of mixed vocals and instrumental music, as well as TCN models trained specifically with solo instrumental performances. Through evaluations on drum, guitar, and classical piano datasets, our TCN models with the new training scheme achieved the best performance. Our newly trained TCN model increases the Acc1 metric by 38.6% for guitar tempo estimation, compared to the pretrained TCN model with an Acc1 of 61.1%. Although our trained TCN model is twice as accurate as the pretrained TCN model in estimating classical piano tempo, its Acc1 is only 50.9%. To improve the performance of deep learning models, we investigate their combinations with various post-processing methods. These post-processing techniques effectively enhance the performance of deep learning models when they struggle to estimate the tempo of specific instruments.
Investigating self-supervised learning for lyrics recognition
Sep 28, 2022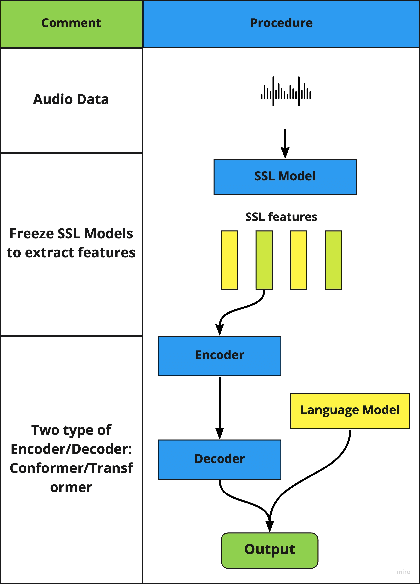
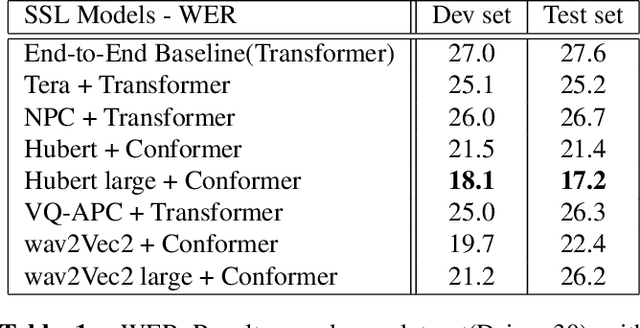
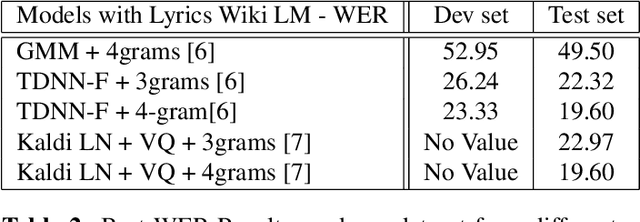
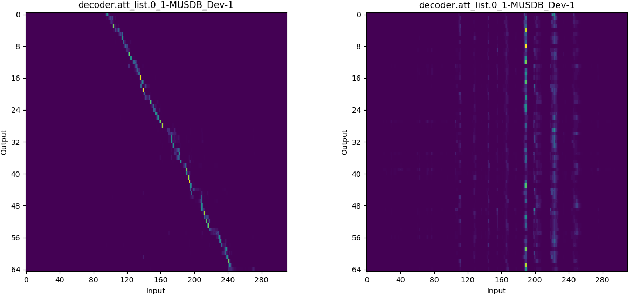
Lyrics recognition is an important task in music processing. Despite the great number of traditional algorithms such as the hybrid HMM-TDNN model achieving good performance, studies on applying end-to-end models and self-supervised learning (SSL) are limited. In this paper, we first establish an end-to-end baseline for lyrics recognition and then explore the performance of SSL models. We evaluate four upstream SSL models based on their training method (masked reconstruction, masked prediction, autoregressive reconstruction, contrastive model). After applying the SSL model, the best performance improved by 5.23% for the dev set and 2.4% for the test set compared with the previous state-of-art baseline system even without a language model trained by a large corpus. Moreover, we study the generalization ability of the SSL features considering that those models were not trained on music datasets.