 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating self-supervised learning for lyrics recognition
Paper and Code
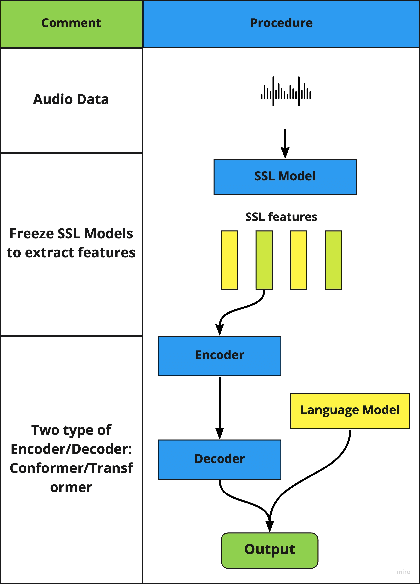
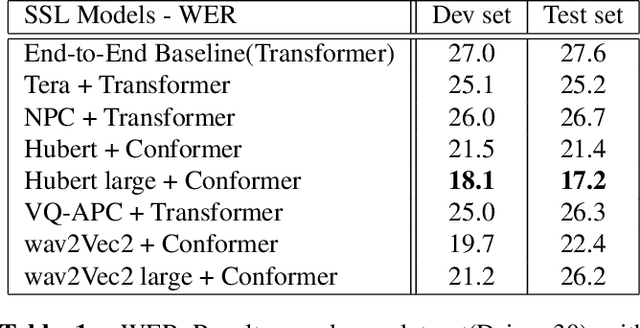
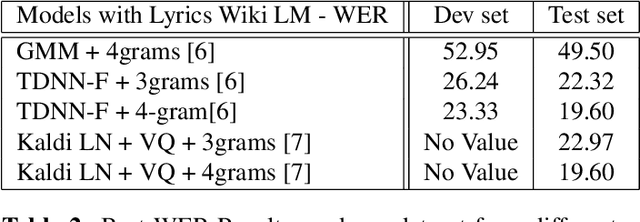
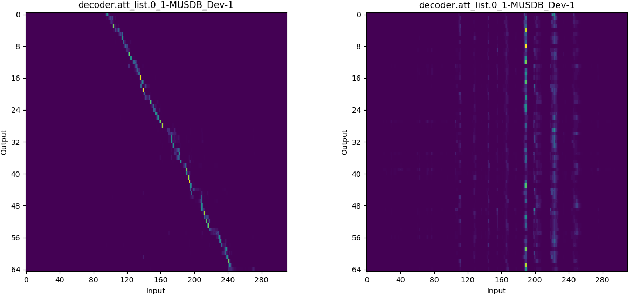
Lyrics recognition is an important task in music processing. Despite the great number of traditional algorithms such as the hybrid HMM-TDNN model achieving good performance, studies on applying end-to-end models and self-supervised learning (SSL) are limited. In this paper, we first establish an end-to-end baseline for lyrics recognition and then explore the performance of SSL models. We evaluate four upstream SSL models based on their training method (masked reconstruction, masked prediction, autoregressive reconstruction, contrastive model). After applying the SSL model, the best performance improved by 5.23% for the dev set and 2.4% for the test set compared with the previous state-of-art baseline system even without a language model trained by a large corpus. Moreover, we study the generalization ability of the SSL features considering that those models were not trained on music datasets.