 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Encoder Transformer-Based Multimodal Learning for Ischemic Stroke Lesion Segmentation Using Diffusion MRI
Dec 23, 2025Accurate segmentation of ischemic stroke lesions from diffusion magnetic resonance imaging (MRI) is essential for clinical decision-making and outcome assessment. Diffusion-Weighted Imaging (DWI) and Apparent Diffusion Coefficient (ADC) scans provide complementary information on acute and sub-acute ischemic changes; however, automated lesion delineation remains challenging due to variability in lesion appearance. In this work, we study ischemic stroke lesion segmentation using multimodal diffusion MRI from the ISLES 2022 dataset. Several state-of-the-art convolutional and transformer-based architectures, including U-Net variants, Swin-UNet, and TransUNet, are benchmarked. Based on performance, a dual-encoder TransUNet architecture is proposed to learn modality-specific representations from DWI and ADC inputs. To incorporate spatial context, adjacent slice information is integrated using a three-slice input configuration. All models are trained under a unified framework and evaluated using the Dice Similarity Coefficient (DSC). Results show that transformer-based models outperform convolutional baselines, and the proposed dual-encoder TransUNet achieves the best performance, reaching a Dice score of 85.4% on the test set. The proposed framework offers a robust solution for automated ischemic stroke lesion segmentation from diffusion MRI.
PENDULUM: A Benchmark for Assessing Sycophancy in Multimodal Large Language Models
Dec 22, 2025Sycophancy, an excessive tendency of AI models to agree with user input at the expense of factual accuracy or in contradiction of visual evidence, poses a critical and underexplored challenge for multimodal large language models (MLLMs). While prior studies have examined this behavior in text-only settings of large language models, existing research on visual or multimodal counterparts remains limited in scope and depth of analysis. To address this gap, we introduce a comprehensive evaluation benchmark, \textit{PENDULUM}, comprising approximately 2,000 human-curated Visual Question Answering pairs specifically designed to elicit sycophantic responses. The benchmark spans six distinct image domains of varying complexity, enabling a systematic investigation of how image type and inherent challenges influence sycophantic tendencies. Through extensive evaluation of state-of-the-art MLLMs. we observe substantial variability in model robustness and a pronounced susceptibility to sycophantic and hallucinatory behavior. Furthermore, we propose novel metrics to quantify sycophancy in visual reasoning, offering deeper insights into its manifestations across different multimodal contexts. Our findings highlight the urgent need for developing sycophancy-resilient architectures and training strategies to enhance factual consistency and reliability in future MLLMs. Our proposed dataset with MLLMs response are available at https://github.com/ashikiut/pendulum/.
Complex Swin Transformer for Accelerating Enhanced SMWI Reconstruction
Dec 21, 2025Susceptibility Map Weighted Imaging (SMWI) is an advanced magnetic resonance imaging technique used to detect nigral hyperintensity in Parkinsons disease. However, full resolution SMWI acquisition is limited by long scan times. Efficient reconstruction methods are therefore required to generate high quality SMWI from reduced k space data while preserving diagnostic relevance. In this work, we propose a complex valued Swin Transformer based network for super resolution reconstruction of multi echo MRI data. The proposed method reconstructs high quality SMWI images from low resolution k space inputs. Experimental results demonstrate that the method achieves a structural similarity index of 0.9116 and a mean squared error of 0.076 when reconstructing SMWI from 256 by 256 k space data, while maintaining critical diagnostic features. This approach enables high quality SMWI reconstruction from reduced k space sampling, leading to shorter scan times without compromising diagnostic detail. The proposed method has the potential to improve the clinical applicability of SMWI for Parkinsons disease and support faster and more efficient neuroimaging workflows.
Anatomy-Guided Representation Learning Using a Transformer-Based Network for Thyroid Nodule Segmentation in Ultrasound Images
Dec 14, 2025Accurate thyroid nodule segmentation in ultrasound images is critical for diagnosis and treatment planning. However, ambiguous boundaries between nodules and surrounding tissues, size variations, and the scarcity of annotated ultrasound data pose significant challenges for automated segmentation. Existing deep learning models struggle to incorporate contextual information from the thyroid gland and generalize effectively across diverse cases. To address these challenges, we propose SSMT-Net, a Semi-Supervised Multi-Task Transformer-based Network that leverages unlabeled data to enhance Transformer-centric encoder feature extraction capability in an initial unsupervised phase. In the supervised phase, the model jointly optimizes nodule segmentation, gland segmentation, and nodule size estimation, integrating both local and global contextual features. Extensive evaluations on the TN3K and DDTI datasets demonstrate that SSMT-Net outperforms state-of-the-art methods, with higher accuracy and robustness, indicating its potential for real-world clinical applications.
MSRNet: A Multi-Scale Recursive Network for Camouflaged Object Detection
Nov 16, 2025
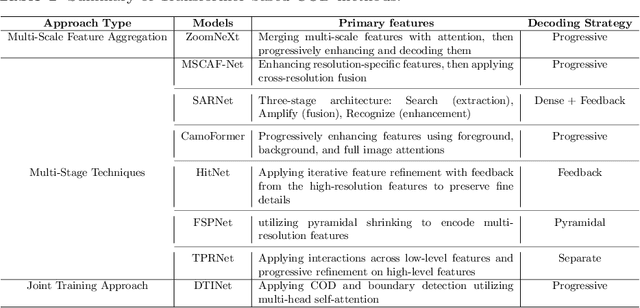
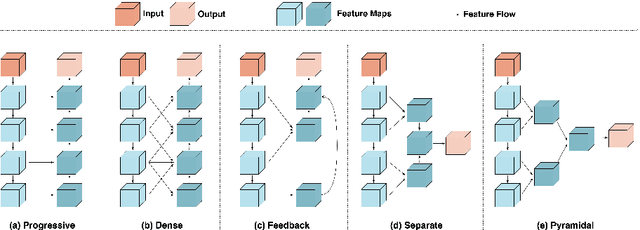
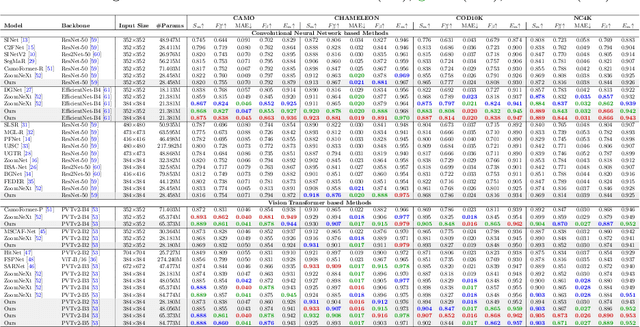
Camouflaged object detection is an emerging and challenging computer vision task that requires identifying and segmenting objects that blend seamlessly into their environments due to high similarity in color, texture, and size. This task is further complicated by low-light conditions, partial occlusion, small object size, intricate background patterns, and multiple objects. While many sophisticated methods have been proposed for this task, current methods still struggle to precisely detect camouflaged objects in complex scenarios, especially with small and multiple objects, indicating room for improvement. We propose a Multi-Scale Recursive Network that extracts multi-scale features via a Pyramid Vision Transformer backbone and combines them via specialized Attention-Based Scale Integration Units, enabling selective feature merging. For more precise object detection, our decoder recursively refines features by incorporating Multi-Granularity Fusion Units. A novel recursive-feedback decoding strategy is developed to enhance global context understanding, helping the model overcome the challenges in this task. By jointly leveraging multi-scale learning and recursive feature optimization, our proposed method achieves performance gains, successfully detecting small and multiple camouflaged objects. Our model achieves state-of-the-art results on two benchmark datasets for camouflaged object detection and ranks second on the remaining two. Our codes, model weights, and results are available at \href{https://github.com/linaagh98/MSRNet}{https://github.com/linaagh98/MSRNet}.
Multilingual Hate Speech Detection in Social Media Using Translation-Based Approaches with Large Language Models
Jun 09, 2025



Social media platforms are critical spaces for public discourse, shaping opinions and community dynamics, yet their widespread use has amplified harmful content, particularly hate speech, threatening online safety and inclusivity. While hate speech detection has been extensively studied in languages like English and Spanish, Urdu remains underexplored, especially using translation-based approaches. To address this gap, we introduce a trilingual dataset of 10,193 tweets in English (3,834 samples), Urdu (3,197 samples), and Spanish (3,162 samples), collected via keyword filtering, with a balanced distribution of 4,849 Hateful and 5,344 Not-Hateful labels. Our methodology leverages attention layers as a precursor to transformer-based models and large language models (LLMs), enhancing feature extraction for multilingual hate speech detection. For non-transformer models, we use TF-IDF for feature extraction. The dataset is benchmarked using state-of-the-art models, including GPT-3.5 Turbo and Qwen 2.5 72B, alongside traditional machine learning models like SVM and other transformers (e.g., BERT, RoBERTa). Three annotators, following rigorous guidelines, ensured high dataset quality, achieving a Fleiss' Kappa of 0.821. Our approach, integrating attention layers with GPT-3.5 Turbo and Qwen 2.5 72B, achieves strong performance, with macro F1 scores of 0.87 for English (GPT-3.5 Turbo), 0.85 for Spanish (GPT-3.5 Turbo), 0.81 for Urdu (Qwen 2.5 72B), and 0.88 for the joint multilingual model (Qwen 2.5 72B). These results reflect improvements of 8.75% in English (over SVM baseline 0.80), 8.97% in Spanish (over SVM baseline 0.78), 5.19% in Urdu (over SVM baseline 0.77), and 7.32% in the joint multilingual model (over SVM baseline 0.82). Our framework offers a robust solution for multilingual hate speech detection, fostering safer digital communities worldwide.
InspectionV3: Enhancing Tobacco Quality Assessment with Deep Convolutional Neural Networks for Automated Workshop Management
May 22, 2025The problems that tobacco workshops encounter include poor curing, inconsistencies in supplies, irregular scheduling, and a lack of oversight, all of which drive up expenses and worse quality. Large quantities make manual examination costly, sluggish, and unreliable. Deep convolutional neural networks have recently made strides in capabilities that transcend those of conventional methods. To effectively enhance them, nevertheless, extensive customization is needed to account for subtle variations in tobacco grade. This study introduces InspectionV3, an integrated solution for automated flue-cured tobacco grading that makes use of a customized deep convolutional neural network architecture. A scope that covers color, maturity, and curing subtleties is established via a labelled dataset consisting of 21,113 images spanning 20 quality classes. Expert annotators performed preprocessing on the tobacco leaf images, including cleaning, labelling, and augmentation. Multi-layer CNN factors use batch normalization to describe domain properties like as permeability and moisture spots, and so account for the subtleties of the workshop. Its expertise lies in converting visual patterns into useful information for enhancing workflow. Fast notifications are made possible by real-time, on-the-spot grading that matches human expertise. Images-powered analytics dashboards facilitate the tracking of yield projections, inventories, bottlenecks, and the optimization of data-driven choices. More labelled images are assimilated after further retraining, improving representational capacities and enabling adaptations for seasonal variability. Metrics demonstrate 97% accuracy, 95% precision and recall, 96% F1-score and AUC, 95% specificity; validating real-world viability.
Millimeter-Wave ISAC Testbed Using Programmable Digital Coding Dynamic Metasurface Antenna: Practical Design and Implementation
Feb 19, 2025Dynamic Metasurface Antennas (DMAs) are transforming reconfigurable antenna technology by enabling energy-efficient, cost-effective beamforming through programmable meta-elements, eliminating the need for traditional phase shifters and delay lines. This breakthrough technology is emerging to revolutionize beamforming for next-generation wireless communication and sensing networks. In this paper, we present the design and real-world implementation of a DMA-assisted wireless communication platform operating in the license-free 60 GHz millimeter-wave (mmWave) band. Our system employs high-speed binary-coded sequences generated via a field-programmable gate array (FPGA), enabling real-time beam steering for spatial multiplexing and independent data transmission. A proof-of-concept experiment successfully demonstrates high-definition quadrature phase-shift keying (QPSK) modulated video transmission at 62 GHz. Furthermore, leveraging the DMA's multi-beam capability, we simultaneously transmit video to two spatially separated receivers, achieving accurate demodulation. We envision the proposed mmWave testbed as a platform for enabling the seamless integration of sensing and communication by allowing video transmission to be replaced with sensing data or utilizing an auxiliary wireless channel to transmit sensing information to multiple receivers. This synergy paves the way for advancing integrated sensing and communication (ISAC) in beyond-5G and 6G networks. Additionally, our testbed demonstrates potential for real-world use cases, including mmWave backhaul links and massive multiple-input multiple-output (MIMO) mmWave base stations.
Cardiverse: Harnessing LLMs for Novel Card Game Prototyping
Feb 10, 2025The prototyping of computer games, particularly card games, requires extensive human effort in creative ideation and gameplay evaluation. Recent advances in Large Language Models (LLMs) offer opportunities to automate and streamline these processes. However, it remains challenging for LLMs to design novel game mechanics beyond existing databases, generate consistent gameplay environments, and develop scalable gameplay AI for large-scale evaluations. This paper addresses these challenges by introducing a comprehensive automated card game prototyping framework. The approach highlights a graph-based indexing method for generating novel game designs, an LLM-driven system for consistent game code generation validated by gameplay records, and a gameplay AI constructing method that uses an ensemble of LLM-generated action-value functions optimized through self-play. These contributions aim to accelerate card game prototyping, reduce human labor, and lower barriers to entry for game developers.
USEFUSE: Utile Stride for Enhanced Performance in Fused Layer Architecture of Deep Neural Networks
Dec 18, 2024



Convolutional Neural Networks (CNNs) are crucial in various applications, but their deployment on resource-constrained edge devices poses challenges. This study presents the Sum-of-Products (SOP) units for convolution, which utilize low-latency left-to-right bit-serial arithmetic to minimize response time and enhance overall performance. The study proposes a methodology for fusing multiple convolution layers to reduce off-chip memory communication and increase overall performance. An effective mechanism detects and skips inefficient convolutions after ReLU layers, minimizing power consumption without compromising accuracy. Furthermore, efficient tile movement guarantees uniform access to the fusion pyramid. An analysis demonstrates the utile stride strategy improves operational intensity. Two designs cater to varied demands: one focuses on minimal response time for mission-critical applications, and another focuses on resource-constrained devices with comparable latency. This approach notably reduced redundant computations, improving the efficiency of CNN deployment on edge devices.