 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiological Brain Age Estimation using Sex-Aware Adversarial Variational Autoencoder with Multimodal Neuroimages
Dec 07, 2024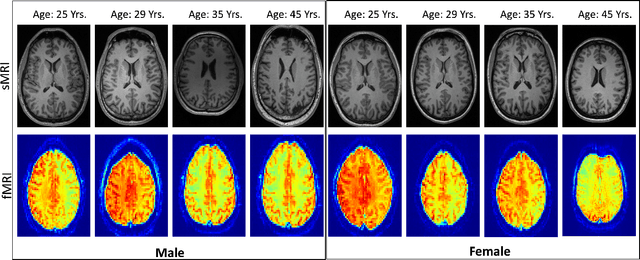
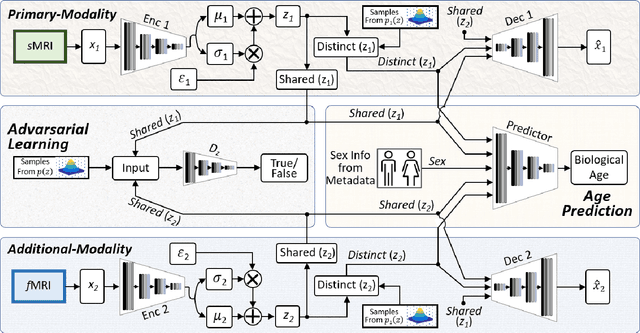
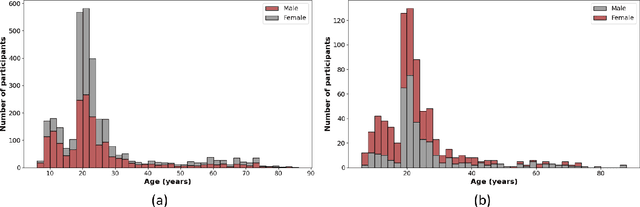
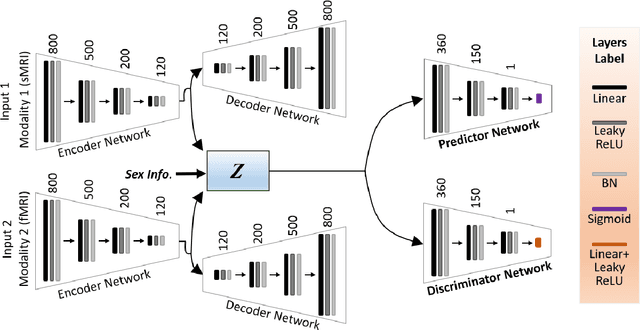
Brain aging involves structural and functional changes and therefore serves as a key biomarker for brain health. Combining structural magnetic resonance imaging (sMRI) and functional magnetic resonance imaging (fMRI) has the potential to improve brain age estimation by leveraging complementary data. However, fMRI data, being noisier than sMRI, complicates multimodal fusion. Traditional fusion methods often introduce more noise than useful information, which can reduce accuracy compared to using sMRI alone. In this paper, we propose a novel multimodal framework for biological brain age estimation, utilizing a sex-aware adversarial variational autoencoder (SA-AVAE). Our framework integrates adversarial and variational learning to effectively disentangle the latent features from both modalities. Specifically, we decompose the latent space into modality-specific codes and shared codes to represent complementary and common information across modalities, respectively. To enhance the disentanglement, we introduce cross-reconstruction and shared-distinct distance ratio loss as regularization terms. Importantly, we incorporate sex information into the learned latent code, enabling the model to capture sex-specific aging patterns for brain age estimation via an integrated regressor module. We evaluate our model using the publicly available OpenBHB dataset, a comprehensive multi-site dataset for brain age estimation. The results from ablation studies and comparisons with state-of-the-art methods demonstrate that our framework outperforms existing approaches and shows significant robustness across various age groups, highlighting its potential for real-time clinical applications in the early detection of neurodegenerative diseases.
Multi-Task Adversarial Variational Autoencoder for Estimating Biological Brain Age with Multimodal Neuroimaging
Nov 15, 2024



Despite advances in deep learning for estimating brain age from structural MRI data, incorporating functional MRI data is challenging due to its complex structure and the noisy nature of functional connectivity measurements. To address this, we present the Multitask Adversarial Variational Autoencoder, a custom deep learning framework designed to improve brain age predictions through multimodal MRI data integration. This model separates latent variables into generic and unique codes, isolating shared and modality-specific features. By integrating multitask learning with sex classification as an additional task, the model captures sex-specific aging patterns. Evaluated on the OpenBHB dataset, a large multisite brain MRI collection, the model achieves a mean absolute error of 2.77 years, outperforming traditional methods. This success positions M-AVAE as a powerful tool for metaverse-based healthcare applications in brain age estimation.
MESAHA-Net: Multi-Encoders based Self-Adaptive Hard Attention Network with Maximum Intensity Projections for Lung Nodule Segmentation in CT Scan
Apr 04, 2023Accurate lung nodule segmentation is crucial for early-stage lung cancer diagnosis, as it can substantially enhance patient survival rates. Computed tomography (CT) images are widely employed for early diagnosis in lung nodule analysis. However, the heterogeneity of lung nodules, size diversity, and the complexity of the surrounding environment pose challenges for developing robust nodule segmentation methods. In this study, we propose an efficient end-to-end framework, the multi-encoder-based self-adaptive hard attention network (MESAHA-Net), for precise lung nodule segmentation in CT scans. MESAHA-Net comprises three encoding paths, an attention block, and a decoder block, facilitating the integration of three types of inputs: CT slice patches, forward and backward maximum intensity projection (MIP) images, and region of interest (ROI) masks encompassing the nodule. By employing a novel adaptive hard attention mechanism, MESAHA-Net iteratively performs slice-by-slice 2D segmentation of lung nodules, focusing on the nodule region in each slice to generate 3D volumetric segmentation of lung nodules. The proposed framework has been comprehensively evaluated on the LIDC-IDRI dataset, the largest publicly available dataset for lung nodule segmentation. The results demonstrate that our approach is highly robust for various lung nodule types, outperforming previous state-of-the-art techniques in terms of segmentation accuracy and computational complexity, rendering it suitable for real-time clinical implementation.
Generative Emotional AI for Speech Emotion Recognition: The Case for Synthetic Emotional Speech Augmentation
Jan 10, 2023Despite advances in deep learning, current state-of-the-art speech emotion recognition (SER) systems still have poor performance due to a lack of speech emotion datasets. This paper proposes augmenting SER systems with synthetic emotional speech generated by an end-to-end text-to-speech (TTS) system based on an extended Tacotron architecture. The proposed TTS system includes encoders for speaker and emotion embeddings, a sequence-to-sequence text generator for creating Mel-spectrograms, and a WaveRNN to generate audio from the Mel-spectrograms. Extensive experiments show that the quality of the generated emotional speech can significantly improve SER performance on multiple datasets, as demonstrated by a higher mean opinion score (MOS) compared to the baseline. The generated samples were also effective at augmenting SER performance.
MEDS-Net: Self-Distilled Multi-Encoders Network with Bi-Direction Maximum Intensity projections for Lung Nodule Detection
Oct 30, 2022In this study, we propose a lung nodule detection scheme which fully incorporates the clinic workflow of radiologists. Particularly, we exploit Bi-Directional Maximum intensity projection (MIP) images of various thicknesses (i.e., 3, 5 and 10mm) along with a 3D patch of CT scan, consisting of 10 adjacent slices to feed into self-distillation-based Multi-Encoders Network (MEDS-Net). The proposed architecture first condenses 3D patch input to three channels by using a dense block which consists of dense units which effectively examine the nodule presence from 2D axial slices. This condensed information, along with the forward and backward MIP images, is fed to three different encoders to learn the most meaningful representation, which is forwarded into the decoded block at various levels. At the decoder block, we employ a self-distillation mechanism by connecting the distillation block, which contains five lung nodule detectors. It helps to expedite the convergence and improves the learning ability of the proposed architecture. Finally, the proposed scheme reduces the false positives by complementing the main detector with auxiliary detectors. The proposed scheme has been rigorously evaluated on 888 scans of LUNA16 dataset and obtained a CPM score of 93.6\%. The results demonstrate that incorporating of bi-direction MIP images enables MEDS-Net to effectively distinguish nodules from surroundings which help to achieve the sensitivity of 91.5% and 92.8% with false positives rate of 0.25 and 0.5 per scan, respectively.