 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchSeek: Retrieving Architectural Case Studies Using Vision-Language Models
Mar 24, 2025Efficiently searching for relevant case studies is critical in architectural design, as designers rely on precedent examples to guide or inspire their ongoing projects. However, traditional text-based search tools struggle to capture the inherently visual and complex nature of architectural knowledge, often leading to time-consuming and imprecise exploration. This paper introduces ArchSeek, an innovative case study search system with recommendation capability, tailored for architecture design professionals. Powered by the visual understanding capabilities from vision-language models and cross-modal embeddings, it enables text and image queries with fine-grained control, and interaction-based design case recommendations. It offers architects a more efficient, personalized way to discover design inspirations, with potential applications across other visually driven design fields. The source code is available at https://github.com/danruili/ArchSeek.
Cardiverse: Harnessing LLMs for Novel Card Game Prototyping
Feb 10, 2025The prototyping of computer games, particularly card games, requires extensive human effort in creative ideation and gameplay evaluation. Recent advances in Large Language Models (LLMs) offer opportunities to automate and streamline these processes. However, it remains challenging for LLMs to design novel game mechanics beyond existing databases, generate consistent gameplay environments, and develop scalable gameplay AI for large-scale evaluations. This paper addresses these challenges by introducing a comprehensive automated card game prototyping framework. The approach highlights a graph-based indexing method for generating novel game designs, an LLM-driven system for consistent game code generation validated by gameplay records, and a gameplay AI constructing method that uses an ensemble of LLM-generated action-value functions optimized through self-play. These contributions aim to accelerate card game prototyping, reduce human labor, and lower barriers to entry for game developers.
TrajDiffuse: A Conditional Diffusion Model for Environment-Aware Trajectory Prediction
Oct 14, 2024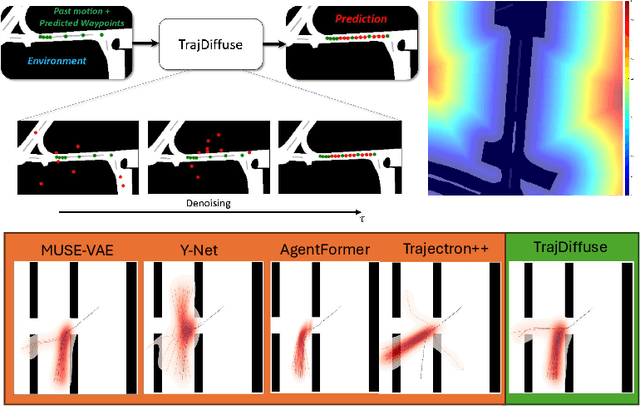



Accurate prediction of human or vehicle trajectories with good diversity that captures their stochastic nature is an essential task for many applications. However, many trajectory prediction models produce unreasonable trajectory samples that focus on improving diversity or accuracy while neglecting other key requirements, such as collision avoidance with the surrounding environment. In this work, we propose TrajDiffuse, a planning-based trajectory prediction method using a novel guided conditional diffusion model. We form the trajectory prediction problem as a denoising impaint task and design a map-based guidance term for the diffusion process. TrajDiffuse is able to generate trajectory predictions that match or exceed the accuracy and diversity of the SOTA, while adhering almost perfectly to environmental constraints. We demonstrate the utility of our model through experiments on the nuScenes and PFSD datasets and provide an extensive benchmark analysis against the SOTA methods.
From Words to Worlds: Transforming One-line Prompt into Immersive Multi-modal Digital Stories with Communicative LLM Agent
Jun 15, 2024



Digital storytelling, essential in entertainment, education, and marketing, faces challenges in production scalability and flexibility. The StoryAgent framework, introduced in this paper, utilizes Large Language Models and generative tools to automate and refine digital storytelling. Employing a top-down story drafting and bottom-up asset generation approach, StoryAgent tackles key issues such as manual intervention, interactive scene orchestration, and narrative consistency. This framework enables efficient production of interactive and consistent narratives across multiple modalities, democratizing content creation and enhancing engagement. Our results demonstrate the framework's capability to produce coherent digital stories without reference videos, marking a significant advancement in automated digital storytelling.
On the Equivalency, Substitutability, and Flexibility of Synthetic Data
Mar 24, 2024We study, from an empirical standpoint, the efficacy of synthetic data in real-world scenarios. Leveraging synthetic data for training perception models has become a key strategy embraced by the community due to its efficiency, scalability, perfect annotations, and low costs. Despite proven advantages, few studies put their stress on how to efficiently generate synthetic datasets to solve real-world problems and to what extent synthetic data can reduce the effort for real-world data collection. To answer the questions, we systematically investigate several interesting properties of synthetic data -- the equivalency of synthetic data to real-world data, the substitutability of synthetic data for real data, and the flexibility of synthetic data generators to close up domain gaps. Leveraging the M3Act synthetic data generator, we conduct experiments on DanceTrack and MOT17. Our results suggest that synthetic data not only enhances model performance but also demonstrates substitutability for real data, with 60% to 80% replacement without performance loss. In addition, our study of the impact of synthetic data distributions on downstream performance reveals the importance of flexible data generators in narrowing domain gaps for improved model adaptability.