 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajDiffuse: A Conditional Diffusion Model for Environment-Aware Trajectory Prediction
Oct 14, 2024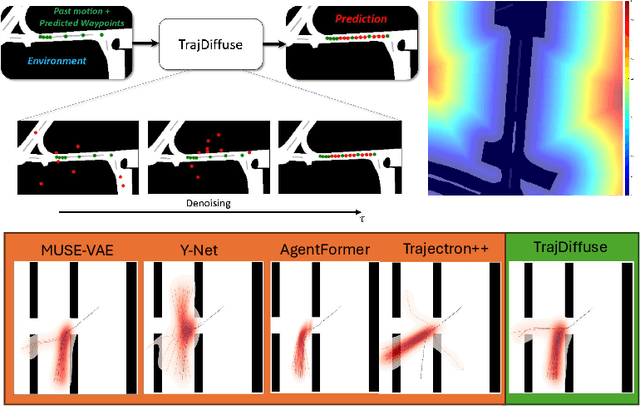



Accurate prediction of human or vehicle trajectories with good diversity that captures their stochastic nature is an essential task for many applications. However, many trajectory prediction models produce unreasonable trajectory samples that focus on improving diversity or accuracy while neglecting other key requirements, such as collision avoidance with the surrounding environment. In this work, we propose TrajDiffuse, a planning-based trajectory prediction method using a novel guided conditional diffusion model. We form the trajectory prediction problem as a denoising impaint task and design a map-based guidance term for the diffusion process. TrajDiffuse is able to generate trajectory predictions that match or exceed the accuracy and diversity of the SOTA, while adhering almost perfectly to environmental constraints. We demonstrate the utility of our model through experiments on the nuScenes and PFSD datasets and provide an extensive benchmark analysis against the SOTA methods.
Learning from Synthetic Human Group Activities
Jul 16, 2023
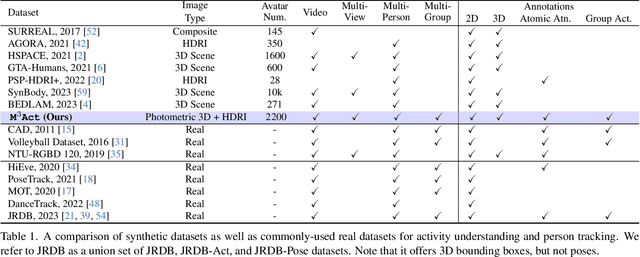
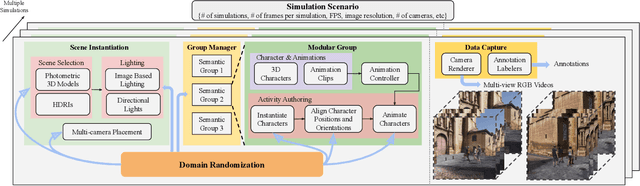
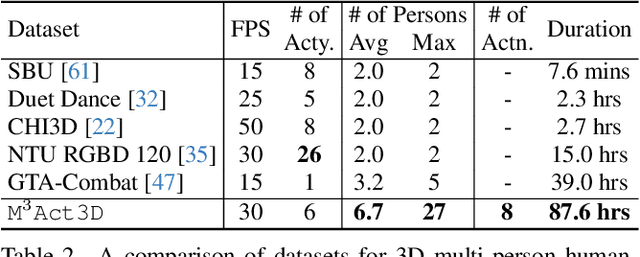
The understanding of complex human interactions and group activities has garnered attention in human-centric computer vision. However, the advancement of the related tasks is hindered due to the difficulty of obtaining large-scale labeled real-world datasets. To mitigate the issue, we propose M3Act, a multi-view multi-group multi-person human atomic action and group activity data generator. Powered by the Unity engine, M3Act contains simulation-ready 3D scenes and human assets, configurable lighting and camera systems, highly parameterized modular group activities, and a large degree of domain randomization during the data generation process. Our data generator is capable of generating large-scale datasets of human activities with multiple viewpoints, modalities (RGB images, 2D poses, 3D motions), and high-quality annotations for individual persons and multi-person groups (2D bounding boxes, instance segmentation masks, individual actions and group activity categories). Using M3Act, we perform synthetic data pre-training for 2D skeleton-based group activity recognition and RGB-based multi-person pose tracking. The results indicate that learning from our synthetic datasets largely improves the model performances on real-world datasets, with the highest gain of 5.59% and 7.32% respectively in group and person recognition accuracy on CAD2, as well as an improvement of 6.63 in MOTP on HiEve. Pre-training with our synthetic data also leads to faster model convergence on downstream tasks (up to 6.8% faster). Moreover, M3Act opens new research problems for 3D group activity generation. We release M3Act3D, an 87.6-hour 3D motion dataset of human activities with larger group sizes and higher complexity of inter-person interactions than previous multi-person datasets. We define multiple metrics and propose a competitive baseline for the novel task.
MSI: Maximize Support-Set Information for Few-Shot Segmentation
Dec 09, 2022FSS(Few-shot segmentation)~aims to segment a target class with a small number of labeled images (support Set). To extract information relevant to target class, a dominant approach in best performing FSS baselines removes background features using support mask. We observe that this support mask presents an information bottleneck in several challenging FSS cases e.g., for small targets and/or inaccurate target boundaries. To this end, we present a novel method (MSI), which maximizes the support-set information by exploiting two complementary source of features in generating super correlation maps. We validate the effectiveness of our approach by instantiating it into three recent and strong FSS baselines. Experimental results on several publicly available FSS benchmarks show that our proposed method consistently improves the performance by visible margins and allows faster convergence. Our codes and models will be publicly released.
An Information-Theoretic Approach for Estimating Scenario Generalization in Crowd Motion Prediction
Nov 02, 2022Learning-based approaches to modeling crowd motion have become increasingly successful but require training and evaluation on large datasets, coupled with complex model selection and parameter tuning. To circumvent this tremendously time-consuming process, we propose a novel scoring method, which characterizes generalization of models trained on source crowd scenarios and applied to target crowd scenarios using a training-free, model-agnostic Interaction + Diversity Quantification score, ISDQ. The Interaction component aims to characterize the difficulty of scenario domains, while the diversity of a scenario domain is captured in the Diversity score. Both scores can be computed in a computation tractable manner. Our experimental results validate the efficacy of the proposed method on several simulated and real-world (source,target) generalization tasks, demonstrating its potential to select optimal domain pairs before training and testing a model.
HMFS: Hybrid Masking for Few-Shot Segmentation
Mar 24, 2022
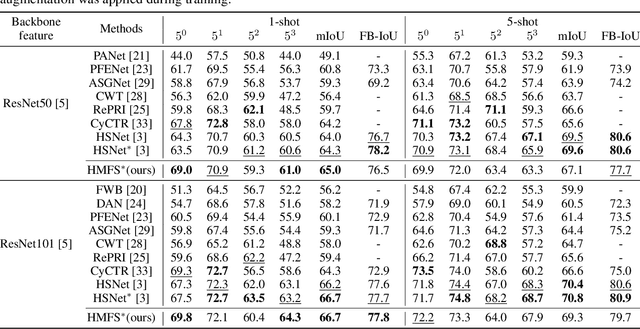
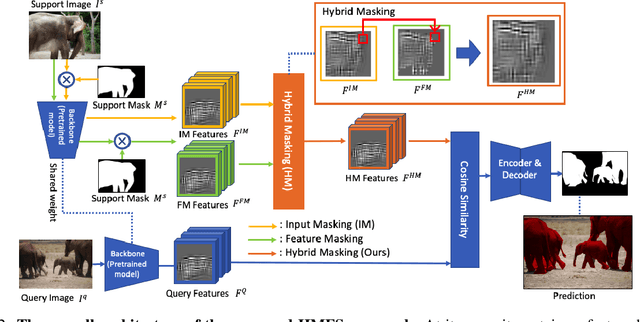
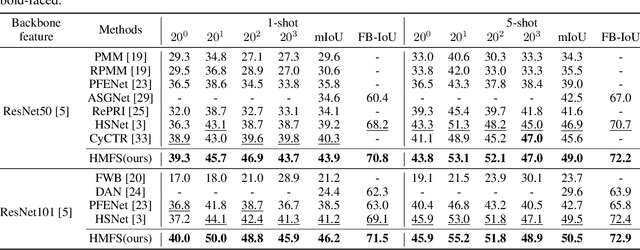
We study few-shot semantic segmentation that aims to segment a target object from a query image when provided with a few annotated support images of the target class. Several recent methods resort to a feature masking (FM) technique, introduced by [1], to discard irrelevant feature activations to facilitate reliable segmentation mask prediction. A fundamental limitation of FM is the inability to preserve the fine-grained spatial details that affect the accuracy of segmentation mask, especially for small target objects. In this paper, we develop a simple, effective, and efficient approach to enhance feature masking (FM). We dub the enhanced FM as hybrid masking (HM). Specifically, we compensate for the loss of fine-grained spatial details in FM technique by investigating and leveraging a complementary basic input masking method [2]. To validate the effectiveness of HM, we instantiate it into a strong baseline [3], and coin the resulting framework as HMFS. Experimental results on three publicly available benchmarks reveal that HMFS outperforms the current state-of-the-art methods by visible margins.
MUSE-VAE: Multi-Scale VAE for Environment-Aware Long Term Trajectory Prediction
Jan 18, 2022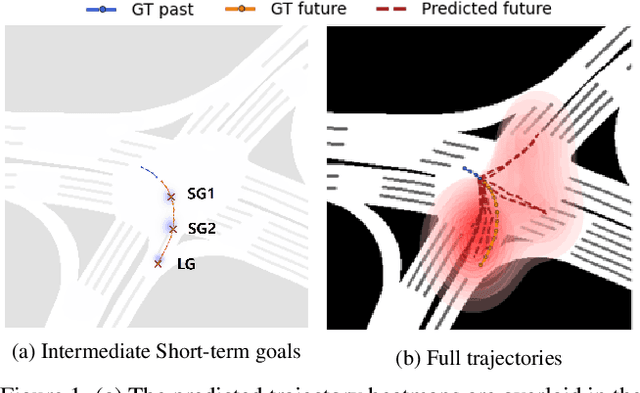
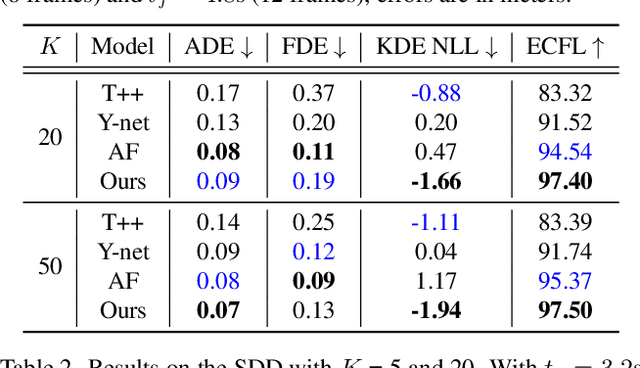
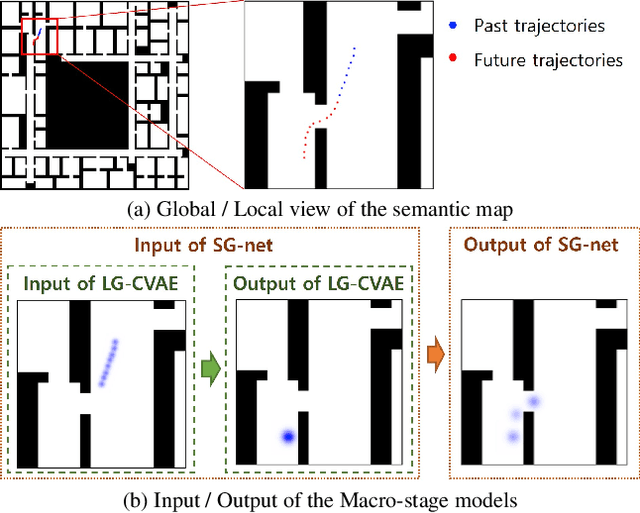
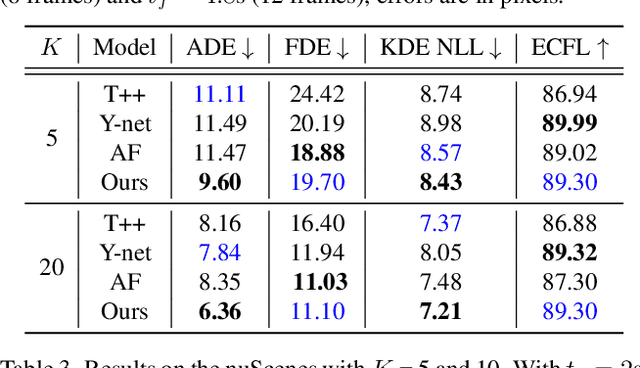
Accurate long-term trajectory prediction in complex scenes, where multiple agents (e.g., pedestrians or vehicles) interact with each other and the environment while attempting to accomplish diverse and often unknown goals, is a challenging stochastic forecasting problem. In this work, we propose MUSE, a new probabilistic modeling framework based on a cascade of Conditional VAEs, which tackles the long-term, uncertain trajectory prediction task using a coarse-to-fine multi-factor forecasting architecture. In its Macro stage, the model learns a joint pixel-space representation of two key factors, the underlying environment and the agent movements, to predict the long and short-term motion goals. Conditioned on them, the Micro stage learns a fine-grained spatio-temporal representation for the prediction of individual agent trajectories. The VAE backbones across the two stages make it possible to naturally account for the joint uncertainty at both levels of granularity. As a result, MUSE offers diverse and simultaneously more accurate predictions compared to the current state-of-the-art. We demonstrate these assertions through a comprehensive set of experiments on nuScenes and SDD benchmarks as well as PFSD, a new synthetic dataset, which challenges the forecasting ability of models on complex agent-environment interaction scenarios.
Deep Crowd-Flow Prediction in Built Environments
Oct 13, 2019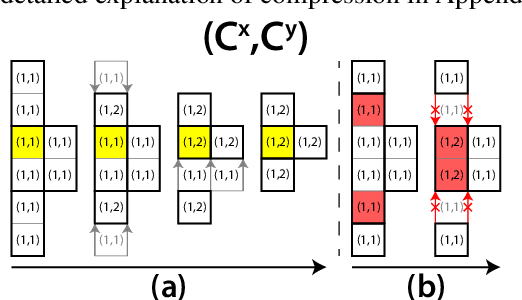
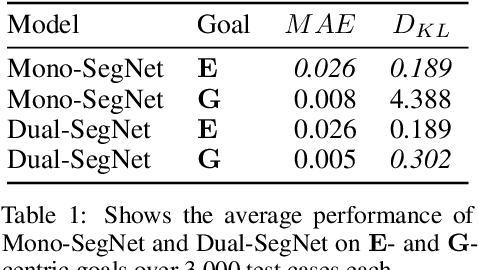
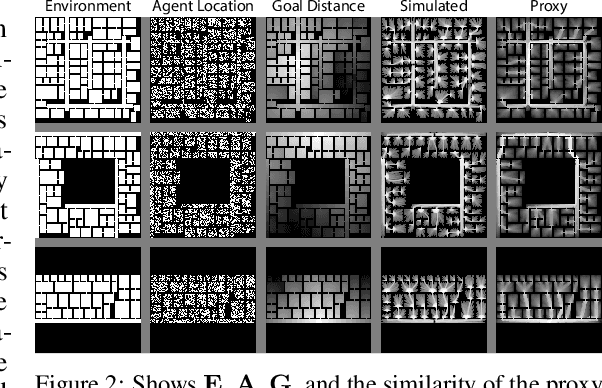
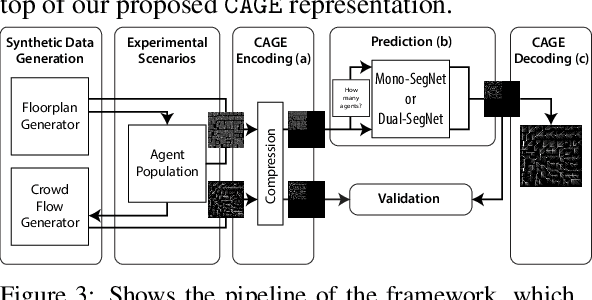
Predicting the behavior of crowds in complex environments is a key requirement in a multitude of application areas, including crowd and disaster management, architectural design, and urban planning. Given a crowd's immediate state, current approaches simulate crowd movement to arrive at a future state. However, most applications require the ability to predict hundreds of possible simulation outcomes (e.g., under different environment and crowd situations) at real-time rates, for which these approaches are prohibitively expensive. In this paper, we propose an approach to instantly predict the long-term flow of crowds in arbitrarily large, realistic environments. Central to our approach is a novel CAGE representation consisting of Capacity, Agent, Goal, and Environment-oriented information, which efficiently encodes and decodes crowd scenarios into compact, fixed-size representations that are environmentally lossless. We present a framework to facilitate the accurate and efficient prediction of crowd flow in never-before-seen crowd scenarios. We conduct a series of experiments to evaluate the efficacy of our approach and showcase positive results.
D-MFVI: Distributed Mean Field Variational Inference using Bregman ADMM
Jul 03, 2015

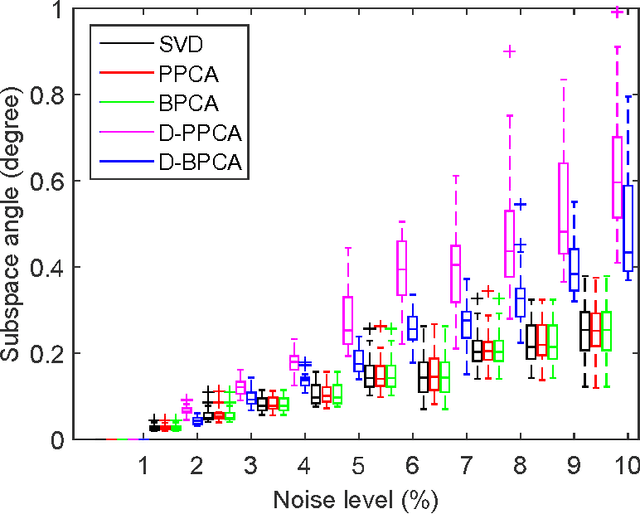

Bayesian models provide a framework for probabilistic modelling of complex datasets. However, many of such models are computationally demanding especially in the presence of large datasets. On the other hand, in sensor network applications, statistical (Bayesian) parameter estimation usually needs distributed algorithms, in which both data and computation are distributed across the nodes of the network. In this paper we propose a general framework for distributed Bayesian learning using Bregman Alternating Direction Method of Multipliers (B-ADMM). We demonstrate the utility of our framework, with Mean Field Variational Bayes (MFVB) as the primitive for distributed Matrix Factorization (MF) and distributed affine structure from motion (SfM).
Fast ADMM Algorithm for Distributed Optimization with Adaptive Penalty
Jun 30, 2015
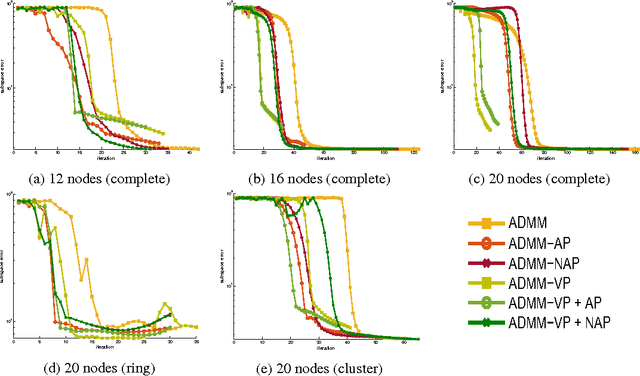
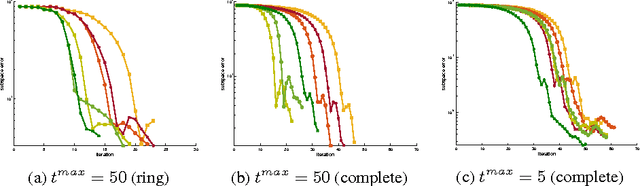
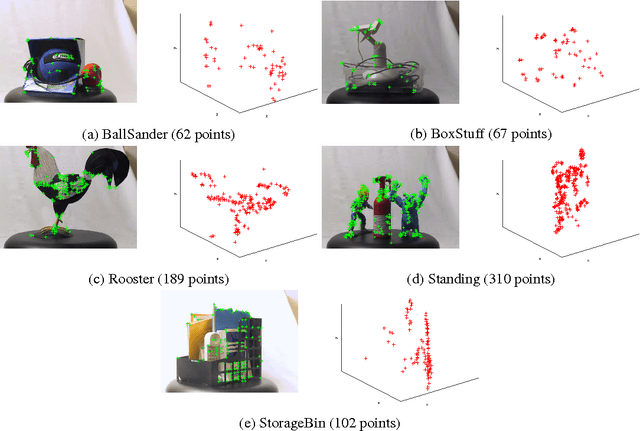
We propose new methods to speed up convergence of the Alternating Direction Method of Multipliers (ADMM), a common optimization tool in the context of large scale and distributed learning. The proposed method accelerates the speed of convergence by automatically deciding the constraint penalty needed for parameter consensus in each iteration. In addition, we also propose an extension of the method that adaptively determines the maximum number of iterations to update the penalty. We show that this approach effectively leads to an adaptive, dynamic network topology underlying the distributed optimization. The utility of the new penalty update schemes is demonstrated on both synthetic and real data, including a computer vision application of distributed structure from motion.