 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSE-VAE: Multi-Scale VAE for Environment-Aware Long Term Trajectory Prediction
Jan 18, 2022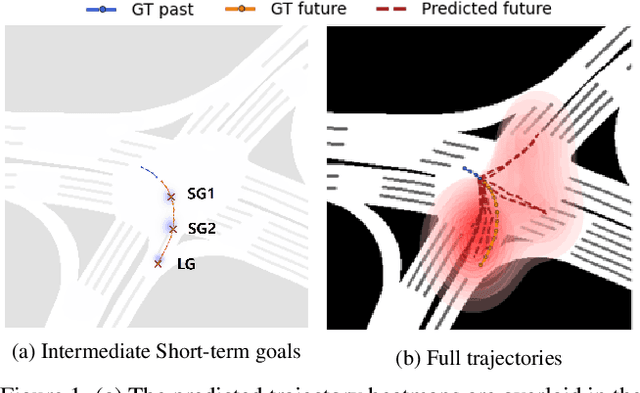
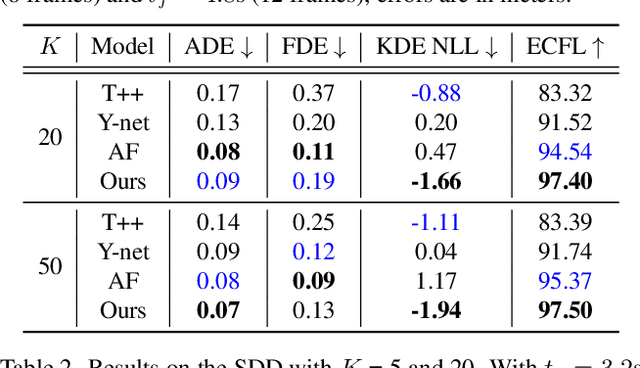
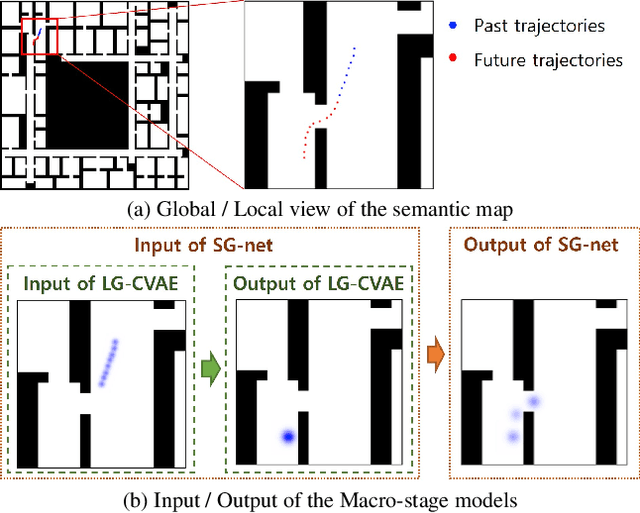
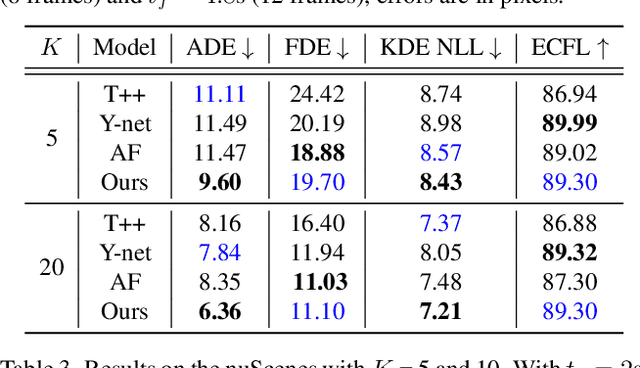
Accurate long-term trajectory prediction in complex scenes, where multiple agents (e.g., pedestrians or vehicles) interact with each other and the environment while attempting to accomplish diverse and often unknown goals, is a challenging stochastic forecasting problem. In this work, we propose MUSE, a new probabilistic modeling framework based on a cascade of Conditional VAEs, which tackles the long-term, uncertain trajectory prediction task using a coarse-to-fine multi-factor forecasting architecture. In its Macro stage, the model learns a joint pixel-space representation of two key factors, the underlying environment and the agent movements, to predict the long and short-term motion goals. Conditioned on them, the Micro stage learns a fine-grained spatio-temporal representation for the prediction of individual agent trajectories. The VAE backbones across the two stages make it possible to naturally account for the joint uncertainty at both levels of granularity. As a result, MUSE offers diverse and simultaneously more accurate predictions compared to the current state-of-the-art. We demonstrate these assertions through a comprehensive set of experiments on nuScenes and SDD benchmarks as well as PFSD, a new synthetic dataset, which challenges the forecasting ability of models on complex agent-environment interaction scenarios.
Private-Shared Disentangled Multimodal VAE for Learning of Hybrid Latent Representations
Dec 23, 2020
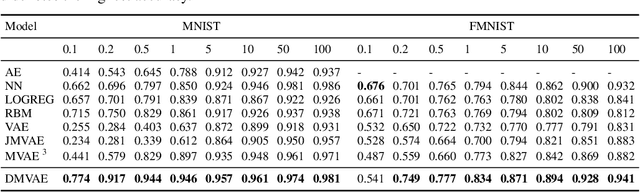

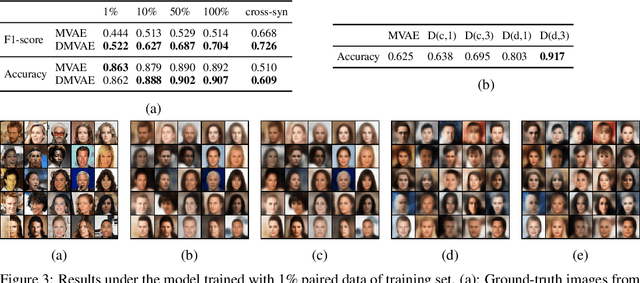
Multi-modal generative models represent an important family of deep models, whose goal is to facilitate representation learning on data with multiple views or modalities. However, current deep multi-modal models focus on the inference of shared representations, while neglecting the important private aspects of data within individual modalities. In this paper, we introduce a disentangled multi-modal variational autoencoder (DMVAE) that utilizes disentangled VAE strategy to separate the private and shared latent spaces of multiple modalities. We specifically consider the instance where the latent factor may be of both continuous and discrete nature, leading to the family of general hybrid DMVAE models. We demonstrate the utility of DMVAE on a semi-supervised learning task, where one of the modalities contains partial data labels, both relevant and irrelevant to the other modality. Our experiments on several benchmarks indicate the importance of the private-shared disentanglement as well as the hybrid latent representation.
Fast and Effective Adaptation of Facial Action Unit Detection Deep Model
Sep 26, 2019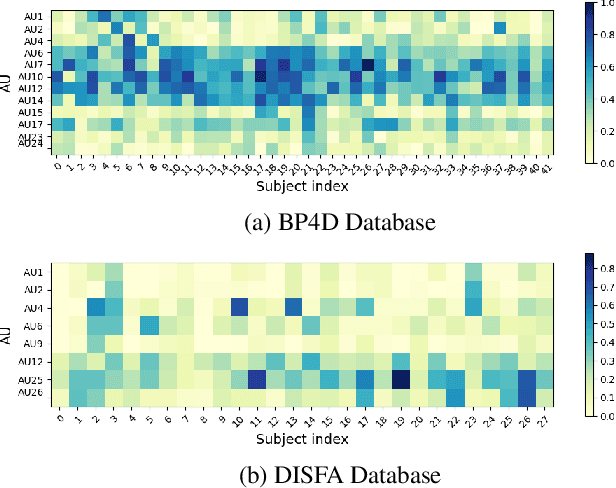

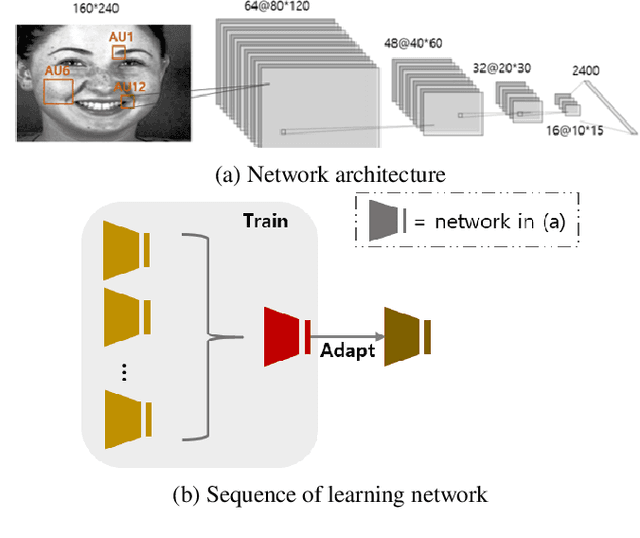
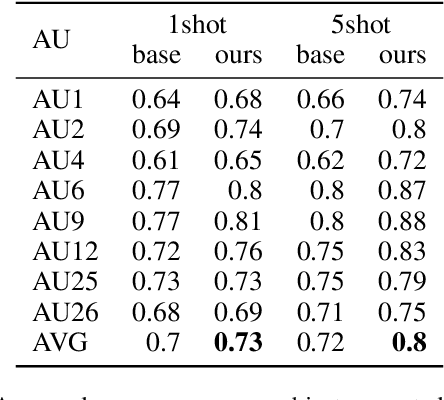
Detecting facial action units (AU) is one of the fundamental steps in automatic recognition of facial expression of emotions and cognitive states. Though there have been a variety of approaches proposed for this task, most of these models are trained only for the specific target AUs, and as such they fail to easily adapt to the task of recognition of new AUs (i.e., those not initially used to train the target models). In this paper, we propose a deep learning approach for facial AU detection that can easily and in a fast manner adapt to a new AU or target subject by leveraging only a few labeled samples from the new task (either an AU or subject). To this end, we propose a modeling approach based on the notion of the model-agnostic meta-learning [C. Finn and Levine, 2017], originally proposed for the general image recognition/detection tasks (e.g., the character recognition from the Omniglot dataset). Specifically, each subject and/or AU is treated as a new learning task and the model learns to adapt based on the knowledge of the previous tasks (the AUs and subjects used to pre-train the target models). Thus, given a new subject or AU, this meta-knowledge (that is shared among training and test tasks) is used to adapt the model to the new task using the notion of deep learning and model-agnostic meta-learning. We show on two benchmark datasets (BP4D and DISFA) for facial AU detection that the proposed approach can be easily adapted to new tasks (AUs/subjects). Using only a few labeled examples from these tasks, the model achieves large improvements over the baselines (i.e., non-adapted models).