 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate-Shared Disentangled Multimodal VAE for Learning of Hybrid Latent Representations
Paper and Code

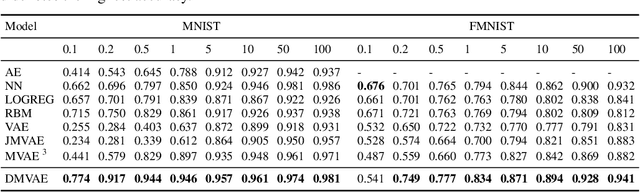

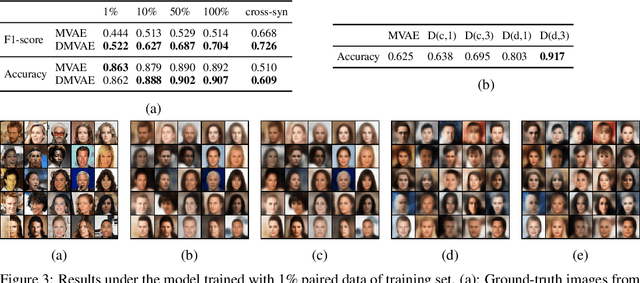
Multi-modal generative models represent an important family of deep models, whose goal is to facilitate representation learning on data with multiple views or modalities. However, current deep multi-modal models focus on the inference of shared representations, while neglecting the important private aspects of data within individual modalities. In this paper, we introduce a disentangled multi-modal variational autoencoder (DMVAE) that utilizes disentangled VAE strategy to separate the private and shared latent spaces of multiple modalities. We specifically consider the instance where the latent factor may be of both continuous and discrete nature, leading to the family of general hybrid DMVAE models. We demonstrate the utility of DMVAE on a semi-supervised learning task, where one of the modalities contains partial data labels, both relevant and irrelevant to the other modality. Our experiments on several benchmarks indicate the importance of the private-shared disentanglement as well as the hybrid latent representation.