 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoMo: A Large-Scale, Richly Organized Dataset and Semantic Taxonomy for Human Motion Generation
May 25, 2026Success in generative modeling across language, image, and video demonstrates that large, well-curated datasets are the key driver for building capable models. 3D Human motion, however, has lagged behind, constrained by an unsatisfying choice between small, high-fidelity motion capture datasets and large-scale in-the-wild collections dominated by static or low-quality sequences. We introduce RoMo, a rich, large-scale, carefully curated dataset of in-the-wild human motions that resolves these tradeoffs. To ensure quality, we introduce a taxonomy-aware filtering pipeline that aggressively removes static and artifact-prone sequences. Every sequence is annotated with detailed captions and organized by a novel three-level semantic taxonomy. This hierarchical structure enables fine-grained, per-category evaluation, that reveals model strengths and weaknesses obscured by global metrics. We demonstrate that models trained on RoMo achieve state-of-the-art fidelity and diversity while gaining a superior understanding of complex, subtle text prompts. Finally, we release the Motion Toolbox to standardize metrics, data conversion, and visualization, establishing a foundation for reproducible and interpretable motion generation research.
MemEye: A Visual-Centric Evaluation Framework for Multimodal Agent Memory
May 14, 2026Long-term agent memory is increasingly multimodal, yet existing evaluations rarely test whether agents preserve the visual evidence needed for later reasoning. In prior work, many visually grounded questions can be answered using only captions or textual traces, allowing answers to be inferred without preserving the fine-grained visual evidence. Meanwhile, harder cases that require reasoning over changing visual states are largely absent. Therefore, we introduce MemEye, a framework that evaluates memory capabilities from two dimensions: one measures the granularity of decisive visual evidence (from scene-level to pixel-level evidence), and the other measures how retrieved evidence must be used (from single evidence to evolutionary synthesis). Under this framework, we construct a new benchmark across 8 life-scenario tasks, with ablation-driven validation gates for assessing answerability, shortcut resistance, visual necessity, and reasoning structure. By evaluating 13 memory methods across 4 VLM backbones, we show that current architectures still struggle to preserve fine-grained visual details and reason about state changes over time. Our findings show that long-term multimodal memory depends on evidence routing, temporal tracking, and detail extraction.
Large Sign Language Models: Toward 3D American Sign Language Translation
Nov 11, 2025We present Large Sign Language Models (LSLM), a novel framework for translating 3D American Sign Language (ASL) by leveraging Large Language Models (LLMs) as the backbone, which can benefit hearing-impaired individuals' virtual communication. Unlike existing sign language recognition methods that rely on 2D video, our approach directly utilizes 3D sign language data to capture rich spatial, gestural, and depth information in 3D scenes. This enables more accurate and resilient translation, enhancing digital communication accessibility for the hearing-impaired community. Beyond the task of ASL translation, our work explores the integration of complex, embodied multimodal languages into the processing capabilities of LLMs, moving beyond purely text-based inputs to broaden their understanding of human communication. We investigate both direct translation from 3D gesture features to text and an instruction-guided setting where translations can be modulated by external prompts, offering greater flexibility. This work provides a foundational step toward inclusive, multimodal intelligent systems capable of understanding diverse forms of language.
StyleMotif: Multi-Modal Motion Stylization using Style-Content Cross Fusion
Mar 27, 2025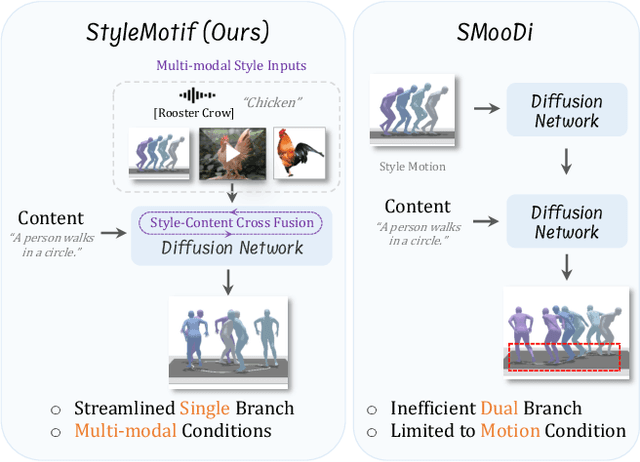
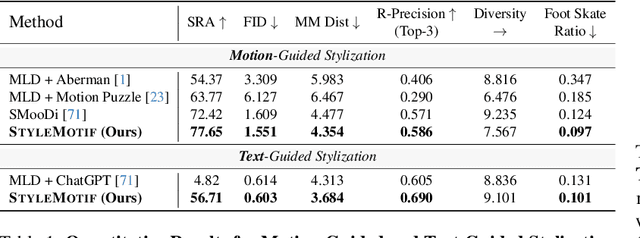
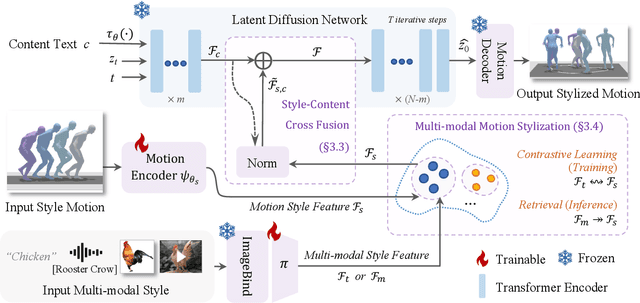
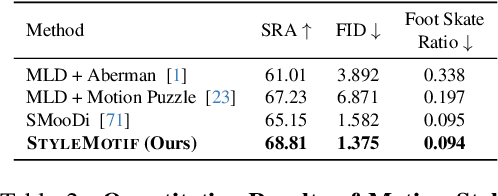
We present StyleMotif, a novel Stylized Motion Latent Diffusion model, generating motion conditioned on both content and style from multiple modalities. Unlike existing approaches that either focus on generating diverse motion content or transferring style from sequences, StyleMotif seamlessly synthesizes motion across a wide range of content while incorporating stylistic cues from multi-modal inputs, including motion, text, image, video, and audio. To achieve this, we introduce a style-content cross fusion mechanism and align a style encoder with a pre-trained multi-modal model, ensuring that the generated motion accurately captures the reference style while preserving realism. Extensive experiments demonstrate that our framework surpasses existing methods in stylized motion generation and exhibits emergent capabilities for multi-modal motion stylization, enabling more nuanced motion synthesis. Source code and pre-trained models will be released upon acceptance. Project Page: https://stylemotif.github.io
ArchSeek: Retrieving Architectural Case Studies Using Vision-Language Models
Mar 24, 2025Efficiently searching for relevant case studies is critical in architectural design, as designers rely on precedent examples to guide or inspire their ongoing projects. However, traditional text-based search tools struggle to capture the inherently visual and complex nature of architectural knowledge, often leading to time-consuming and imprecise exploration. This paper introduces ArchSeek, an innovative case study search system with recommendation capability, tailored for architecture design professionals. Powered by the visual understanding capabilities from vision-language models and cross-modal embeddings, it enables text and image queries with fine-grained control, and interaction-based design case recommendations. It offers architects a more efficient, personalized way to discover design inspirations, with potential applications across other visually driven design fields. The source code is available at https://github.com/danruili/ArchSeek.
Less is More: Improving Motion Diffusion Models with Sparse Keyframes
Mar 18, 2025Recent advances in motion diffusion models have led to remarkable progress in diverse motion generation tasks, including text-to-motion synthesis. However, existing approaches represent motions as dense frame sequences, requiring the model to process redundant or less informative frames. The processing of dense animation frames imposes significant training complexity, especially when learning intricate distributions of large motion datasets even with modern neural architectures. This severely limits the performance of generative motion models for downstream tasks. Inspired by professional animators who mainly focus on sparse keyframes, we propose a novel diffusion framework explicitly designed around sparse and geometrically meaningful keyframes. Our method reduces computation by masking non-keyframes and efficiently interpolating missing frames. We dynamically refine the keyframe mask during inference to prioritize informative frames in later diffusion steps. Extensive experiments show that our approach consistently outperforms state-of-the-art methods in text alignment and motion realism, while also effectively maintaining high performance at significantly fewer diffusion steps. We further validate the robustness of our framework by using it as a generative prior and adapting it to different downstream tasks. Source code and pre-trained models will be released upon acceptance.
Cardiverse: Harnessing LLMs for Novel Card Game Prototyping
Feb 10, 2025The prototyping of computer games, particularly card games, requires extensive human effort in creative ideation and gameplay evaluation. Recent advances in Large Language Models (LLMs) offer opportunities to automate and streamline these processes. However, it remains challenging for LLMs to design novel game mechanics beyond existing databases, generate consistent gameplay environments, and develop scalable gameplay AI for large-scale evaluations. This paper addresses these challenges by introducing a comprehensive automated card game prototyping framework. The approach highlights a graph-based indexing method for generating novel game designs, an LLM-driven system for consistent game code generation validated by gameplay records, and a gameplay AI constructing method that uses an ensemble of LLM-generated action-value functions optimized through self-play. These contributions aim to accelerate card game prototyping, reduce human labor, and lower barriers to entry for game developers.
CASIM: Composite Aware Semantic Injection for Text to Motion Generation
Feb 04, 2025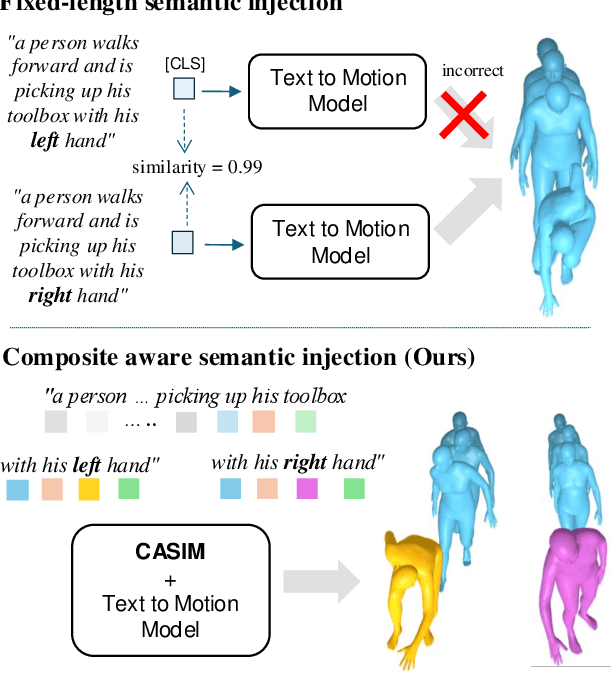

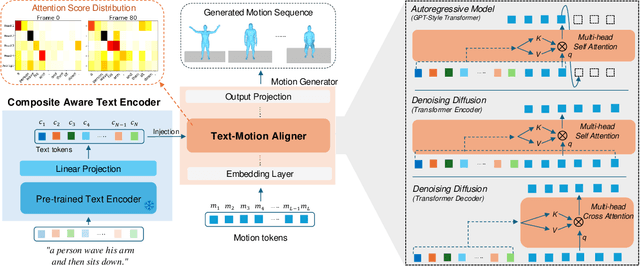
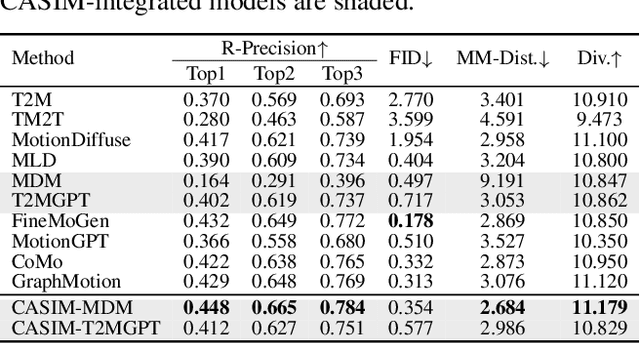
Recent advances in generative modeling and tokenization have driven significant progress in text-to-motion generation, leading to enhanced quality and realism in generated motions. However, effectively leveraging textual information for conditional motion generation remains an open challenge. We observe that current approaches, primarily relying on fixed-length text embeddings (e.g., CLIP) for global semantic injection, struggle to capture the composite nature of human motion, resulting in suboptimal motion quality and controllability. To address this limitation, we propose the Composite Aware Semantic Injection Mechanism (CASIM), comprising a composite-aware semantic encoder and a text-motion aligner that learns the dynamic correspondence between text and motion tokens. Notably, CASIM is model and representation-agnostic, readily integrating with both autoregressive and diffusion-based methods. Experiments on HumanML3D and KIT benchmarks demonstrate that CASIM consistently improves motion quality, text-motion alignment, and retrieval scores across state-of-the-art methods. Qualitative analyses further highlight the superiority of our composite-aware approach over fixed-length semantic injection, enabling precise motion control from text prompts and stronger generalization to unseen text inputs.
TrajDiffuse: A Conditional Diffusion Model for Environment-Aware Trajectory Prediction
Oct 14, 2024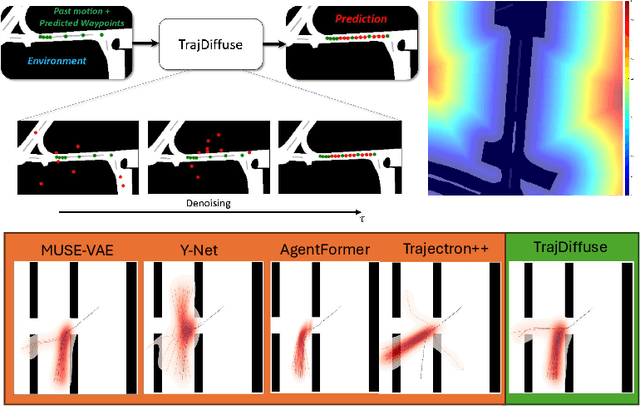



Accurate prediction of human or vehicle trajectories with good diversity that captures their stochastic nature is an essential task for many applications. However, many trajectory prediction models produce unreasonable trajectory samples that focus on improving diversity or accuracy while neglecting other key requirements, such as collision avoidance with the surrounding environment. In this work, we propose TrajDiffuse, a planning-based trajectory prediction method using a novel guided conditional diffusion model. We form the trajectory prediction problem as a denoising impaint task and design a map-based guidance term for the diffusion process. TrajDiffuse is able to generate trajectory predictions that match or exceed the accuracy and diversity of the SOTA, while adhering almost perfectly to environmental constraints. We demonstrate the utility of our model through experiments on the nuScenes and PFSD datasets and provide an extensive benchmark analysis against the SOTA methods.
From Words to Worlds: Transforming One-line Prompt into Immersive Multi-modal Digital Stories with Communicative LLM Agent
Jun 15, 2024



Digital storytelling, essential in entertainment, education, and marketing, faces challenges in production scalability and flexibility. The StoryAgent framework, introduced in this paper, utilizes Large Language Models and generative tools to automate and refine digital storytelling. Employing a top-down story drafting and bottom-up asset generation approach, StoryAgent tackles key issues such as manual intervention, interactive scene orchestration, and narrative consistency. This framework enables efficient production of interactive and consistent narratives across multiple modalities, democratizing content creation and enhancing engagement. Our results demonstrate the framework's capability to produce coherent digital stories without reference videos, marking a significant advancement in automated digital storytelling.