 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleMotif: Multi-Modal Motion Stylization using Style-Content Cross Fusion
Mar 27, 2025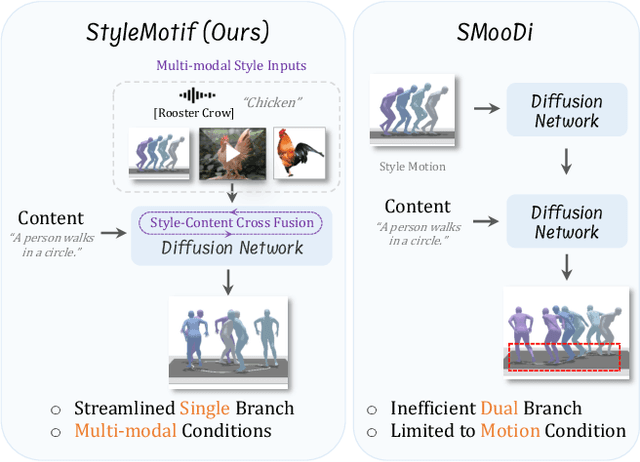
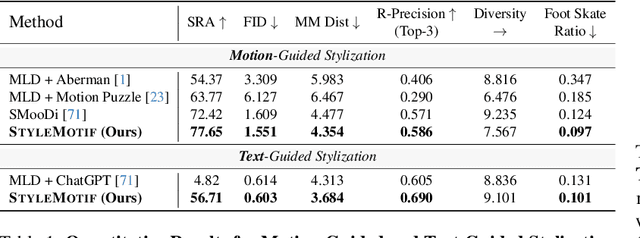
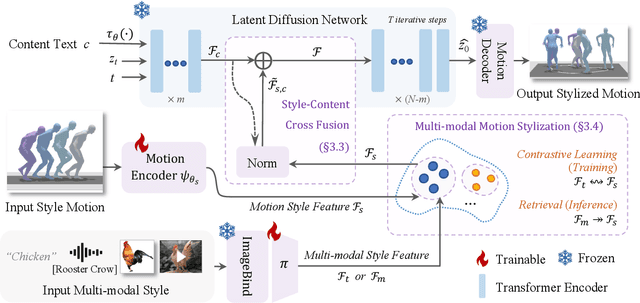
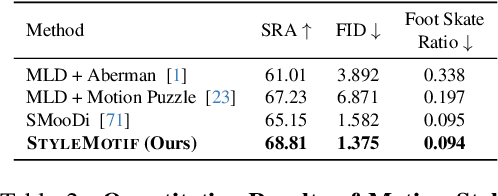
We present StyleMotif, a novel Stylized Motion Latent Diffusion model, generating motion conditioned on both content and style from multiple modalities. Unlike existing approaches that either focus on generating diverse motion content or transferring style from sequences, StyleMotif seamlessly synthesizes motion across a wide range of content while incorporating stylistic cues from multi-modal inputs, including motion, text, image, video, and audio. To achieve this, we introduce a style-content cross fusion mechanism and align a style encoder with a pre-trained multi-modal model, ensuring that the generated motion accurately captures the reference style while preserving realism. Extensive experiments demonstrate that our framework surpasses existing methods in stylized motion generation and exhibits emergent capabilities for multi-modal motion stylization, enabling more nuanced motion synthesis. Source code and pre-trained models will be released upon acceptance. Project Page: https://stylemotif.github.io
Less is More: Improving Motion Diffusion Models with Sparse Keyframes
Mar 18, 2025Recent advances in motion diffusion models have led to remarkable progress in diverse motion generation tasks, including text-to-motion synthesis. However, existing approaches represent motions as dense frame sequences, requiring the model to process redundant or less informative frames. The processing of dense animation frames imposes significant training complexity, especially when learning intricate distributions of large motion datasets even with modern neural architectures. This severely limits the performance of generative motion models for downstream tasks. Inspired by professional animators who mainly focus on sparse keyframes, we propose a novel diffusion framework explicitly designed around sparse and geometrically meaningful keyframes. Our method reduces computation by masking non-keyframes and efficiently interpolating missing frames. We dynamically refine the keyframe mask during inference to prioritize informative frames in later diffusion steps. Extensive experiments show that our approach consistently outperforms state-of-the-art methods in text alignment and motion realism, while also effectively maintaining high performance at significantly fewer diffusion steps. We further validate the robustness of our framework by using it as a generative prior and adapting it to different downstream tasks. Source code and pre-trained models will be released upon acceptance.