 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Ball: Composing Policies for Long-Horizon Basketball Moves
Sep 26, 2025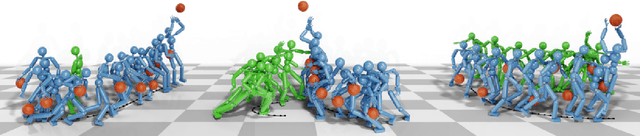

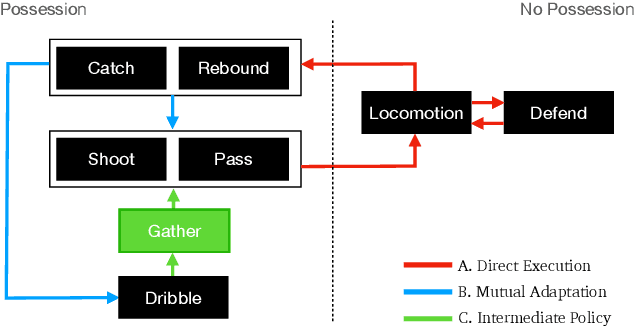

Learning a control policy for a multi-phase, long-horizon task, such as basketball maneuvers, remains challenging for reinforcement learning approaches due to the need for seamless policy composition and transitions between skills. A long-horizon task typically consists of distinct subtasks with well-defined goals, separated by transitional subtasks with unclear goals but critical to the success of the entire task. Existing methods like the mixture of experts and skill chaining struggle with tasks where individual policies do not share significant commonly explored states or lack well-defined initial and terminal states between different phases. In this paper, we introduce a novel policy integration framework to enable the composition of drastically different motor skills in multi-phase long-horizon tasks with ill-defined intermediate states. Based on that, we further introduce a high-level soft router to enable seamless and robust transitions between the subtasks. We evaluate our framework on a set of fundamental basketball skills and challenging transitions. Policies trained by our approach can effectively control the simulated character to interact with the ball and accomplish the long-horizon task specified by real-time user commands, without relying on ball trajectory references.
* ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia 2025). Website: http://pei-xu.github.io/basketball. Video: https://youtu.be/2RBFIjjmR2I. Code: https://github.com/xupei0610/basketball
StyleMotif: Multi-Modal Motion Stylization using Style-Content Cross Fusion
Mar 27, 2025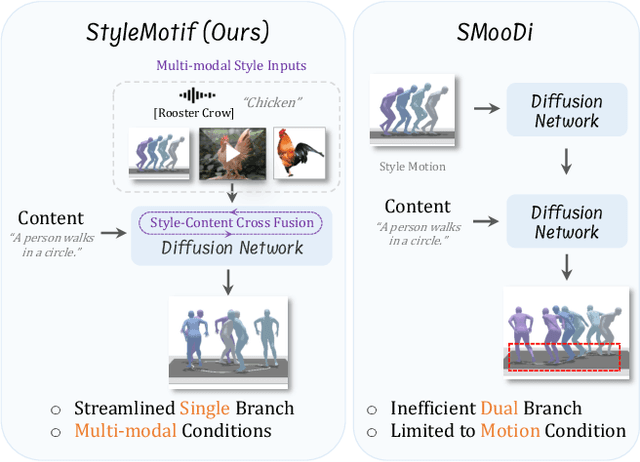
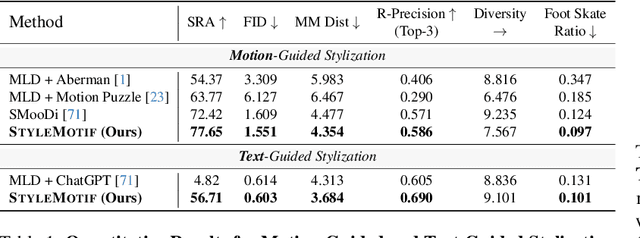
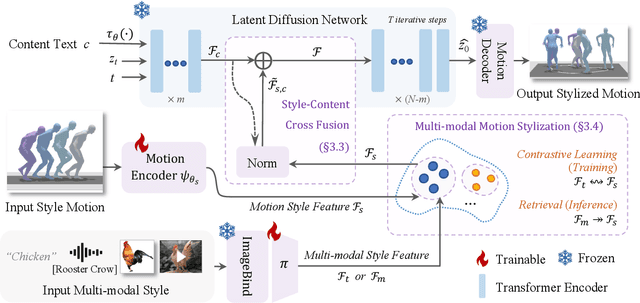
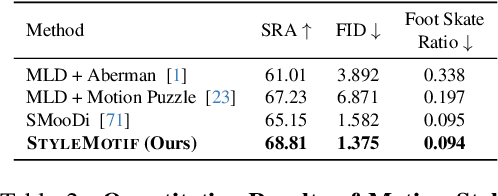
We present StyleMotif, a novel Stylized Motion Latent Diffusion model, generating motion conditioned on both content and style from multiple modalities. Unlike existing approaches that either focus on generating diverse motion content or transferring style from sequences, StyleMotif seamlessly synthesizes motion across a wide range of content while incorporating stylistic cues from multi-modal inputs, including motion, text, image, video, and audio. To achieve this, we introduce a style-content cross fusion mechanism and align a style encoder with a pre-trained multi-modal model, ensuring that the generated motion accurately captures the reference style while preserving realism. Extensive experiments demonstrate that our framework surpasses existing methods in stylized motion generation and exhibits emergent capabilities for multi-modal motion stylization, enabling more nuanced motion synthesis. Source code and pre-trained models will be released upon acceptance. Project Page: https://stylemotif.github.io
A Unified Differentiable Boolean Operator with Fuzzy Logic
Jul 15, 2024This paper presents a unified differentiable boolean operator for implicit solid shape modeling using Constructive Solid Geometry (CSG). Traditional CSG relies on min, max operators to perform boolean operations on implicit shapes. But because these boolean operators are discontinuous and discrete in the choice of operations, this makes optimization over the CSG representation challenging. Drawing inspiration from fuzzy logic, we present a unified boolean operator that outputs a continuous function and is differentiable with respect to operator types. This enables optimization of both the primitives and the boolean operations employed in CSG with continuous optimization techniques, such as gradient descent. We further demonstrate that such a continuous boolean operator allows modeling of both sharp mechanical objects and smooth organic shapes with the same framework. Our proposed boolean operator opens up new possibilities for future research toward fully continuous CSG optimization.
AdaptNet: Policy Adaptation for Physics-Based Character Control
Oct 09, 2023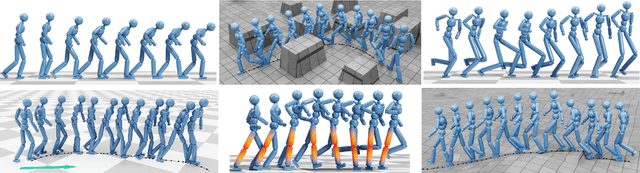
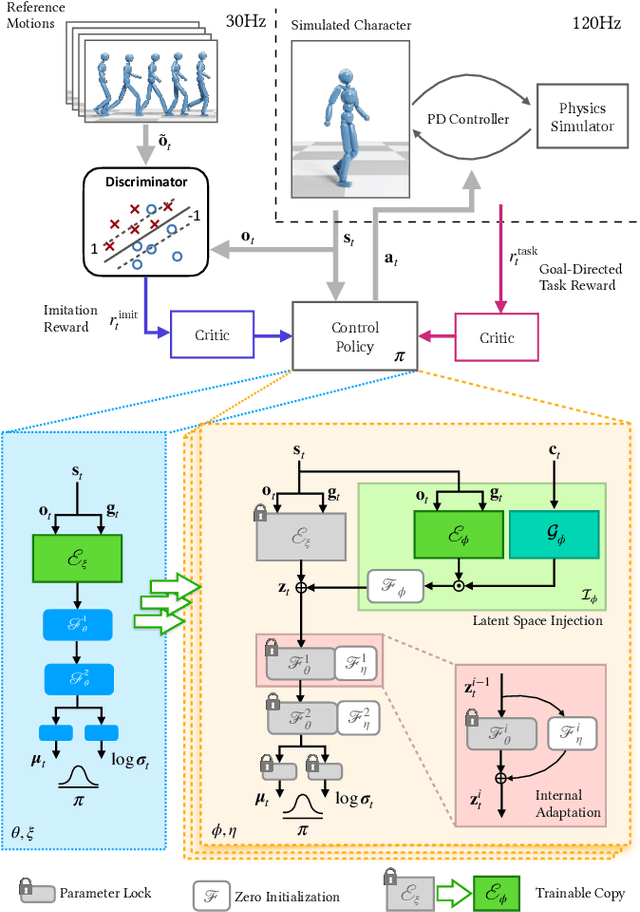
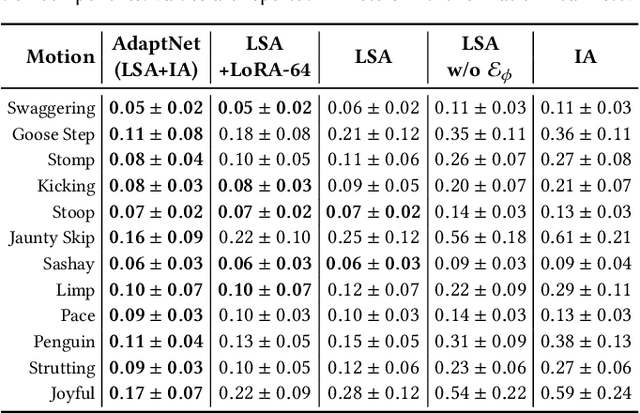
Motivated by humans' ability to adapt skills in the learning of new ones, this paper presents AdaptNet, an approach for modifying the latent space of existing policies to allow new behaviors to be quickly learned from like tasks in comparison to learning from scratch. Building on top of a given reinforcement learning controller, AdaptNet uses a two-tier hierarchy that augments the original state embedding to support modest changes in a behavior and further modifies the policy network layers to make more substantive changes. The technique is shown to be effective for adapting existing physics-based controllers to a wide range of new styles for locomotion, new task targets, changes in character morphology and extensive changes in environment. Furthermore, it exhibits significant increase in learning efficiency, as indicated by greatly reduced training times when compared to training from scratch or using other approaches that modify existing policies. Code is available at https://motion-lab.github.io/AdaptNet.
* SIGGRAPH Asia 2023. Video: https://youtu.be/WxmJSCNFb28. Website: https://motion-lab.github.io/AdaptNet, https://pei-xu.github.io/AdaptNet
Learning When to Speak: Latency and Quality Trade-offs for Simultaneous Speech-to-Speech Translation with Offline Models
Jun 01, 2023

Recent work in speech-to-speech translation (S2ST) has focused primarily on offline settings, where the full input utterance is available before any output is given. This, however, is not reasonable in many real-world scenarios. In latency-sensitive applications, rather than waiting for the full utterance, translations should be spoken as soon as the information in the input is present. In this work, we introduce a system for simultaneous S2ST targeting real-world use cases. Our system supports translation from 57 languages to English with tunable parameters for dynamically adjusting the latency of the output -- including four policies for determining when to speak an output sequence. We show that these policies achieve offline-level accuracy with minimal increases in latency over a Greedy (wait-$k$) baseline. We open-source our evaluation code and interactive test script to aid future SimulS2ST research and application development.
Composite Motion Learning with Task Control
May 05, 2023



We present a deep learning method for composite and task-driven motion control for physically simulated characters. In contrast to existing data-driven approaches using reinforcement learning that imitate full-body motions, we learn decoupled motions for specific body parts from multiple reference motions simultaneously and directly by leveraging the use of multiple discriminators in a GAN-like setup. In this process, there is no need of any manual work to produce composite reference motions for learning. Instead, the control policy explores by itself how the composite motions can be combined automatically. We further account for multiple task-specific rewards and train a single, multi-objective control policy. To this end, we propose a novel framework for multi-objective learning that adaptively balances the learning of disparate motions from multiple sources and multiple goal-directed control objectives. In addition, as composite motions are typically augmentations of simpler behaviors, we introduce a sample-efficient method for training composite control policies in an incremental manner, where we reuse a pre-trained policy as the meta policy and train a cooperative policy that adapts the meta one for new composite tasks. We show the applicability of our approach on a variety of challenging multi-objective tasks involving both composite motion imitation and multiple goal-directed control.
* SIGGRAPH 2023. Code: https://github.com/xupei0610/CompositeMotion. Video: https://youtu.be/mcRAxwoTh3E