 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Ball: Composing Policies for Long-Horizon Basketball Moves
Sep 26, 2025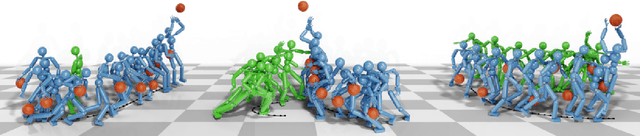

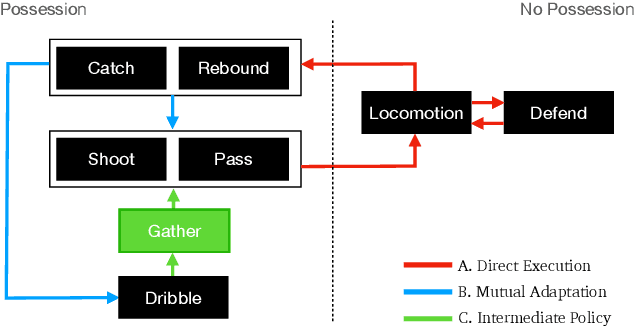

Learning a control policy for a multi-phase, long-horizon task, such as basketball maneuvers, remains challenging for reinforcement learning approaches due to the need for seamless policy composition and transitions between skills. A long-horizon task typically consists of distinct subtasks with well-defined goals, separated by transitional subtasks with unclear goals but critical to the success of the entire task. Existing methods like the mixture of experts and skill chaining struggle with tasks where individual policies do not share significant commonly explored states or lack well-defined initial and terminal states between different phases. In this paper, we introduce a novel policy integration framework to enable the composition of drastically different motor skills in multi-phase long-horizon tasks with ill-defined intermediate states. Based on that, we further introduce a high-level soft router to enable seamless and robust transitions between the subtasks. We evaluate our framework on a set of fundamental basketball skills and challenging transitions. Policies trained by our approach can effectively control the simulated character to interact with the ball and accomplish the long-horizon task specified by real-time user commands, without relying on ball trajectory references.
* ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia 2025). Website: http://pei-xu.github.io/basketball. Video: https://youtu.be/2RBFIjjmR2I. Code: https://github.com/xupei0610/basketball
Gen-C: Populating Virtual Worlds with Generative Crowds
Apr 02, 2025Over the past two decades, researchers have made significant advancements in simulating human crowds, yet these efforts largely focus on low-level tasks like collision avoidance and a narrow range of behaviors such as path following and flocking. However, creating compelling crowd scenes demands more than just functional movement-it requires capturing high-level interactions between agents, their environment, and each other over time. To address this issue, we introduce Gen-C, a generative model to automate the task of authoring high-level crowd behaviors. Gen-C bypasses the labor-intensive and challenging task of collecting and annotating real crowd video data by leveraging a large language model (LLM) to generate a limited set of crowd scenarios, which are subsequently expanded and generalized through simulations to construct time-expanded graphs that model the actions and interactions of virtual agents. Our method employs two Variational Graph Auto-Encoders guided by a condition prior network: one dedicated to learning a latent space for graph structures (agent interactions) and the other for node features (agent actions and navigation). This setup enables the flexible generation of dynamic crowd interactions. The trained model can be conditioned on natural language, empowering users to synthesize novel crowd behaviors from text descriptions. We demonstrate the effectiveness of our approach in two scenarios, a University Campus and a Train Station, showcasing its potential for populating diverse virtual environments with agents exhibiting varied and dynamic behaviors that reflect complex interactions and high-level decision-making patterns.
AdaptNet: Policy Adaptation for Physics-Based Character Control
Oct 09, 2023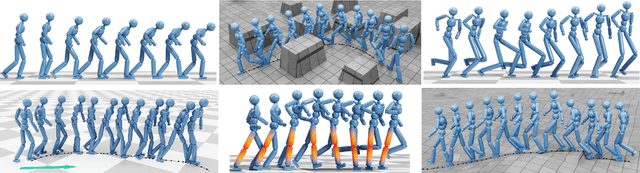
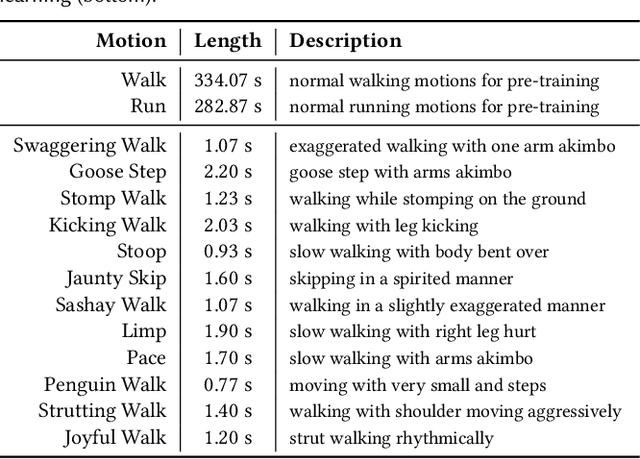
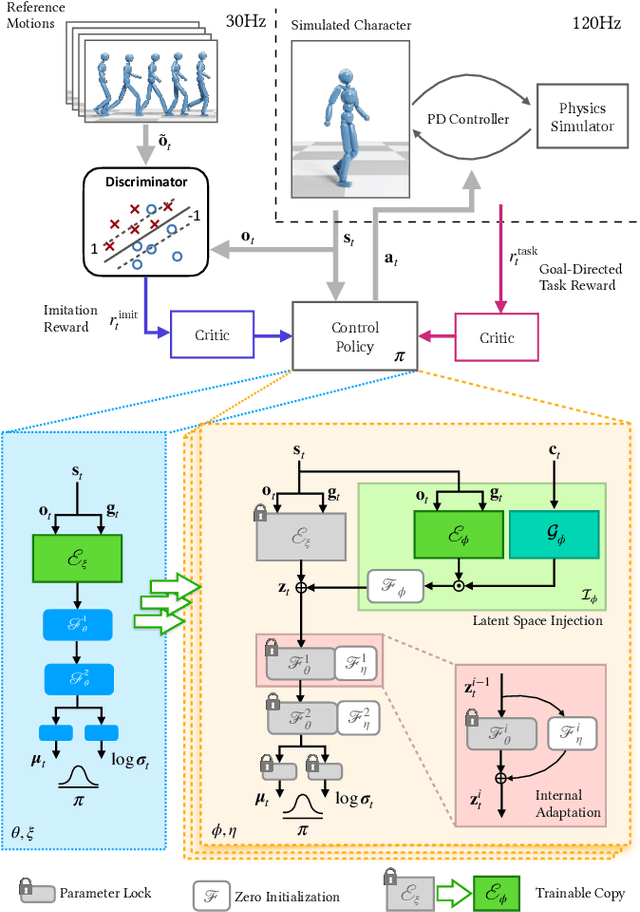
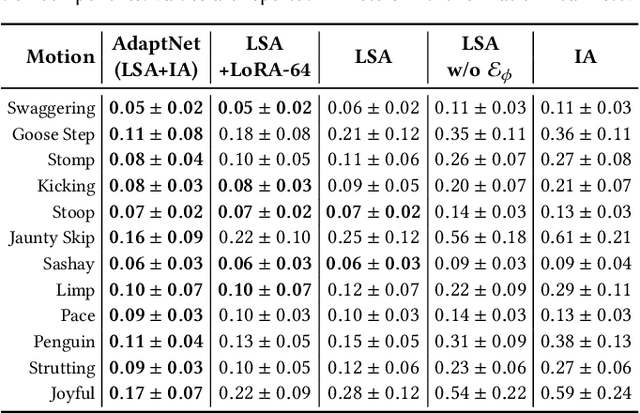
Motivated by humans' ability to adapt skills in the learning of new ones, this paper presents AdaptNet, an approach for modifying the latent space of existing policies to allow new behaviors to be quickly learned from like tasks in comparison to learning from scratch. Building on top of a given reinforcement learning controller, AdaptNet uses a two-tier hierarchy that augments the original state embedding to support modest changes in a behavior and further modifies the policy network layers to make more substantive changes. The technique is shown to be effective for adapting existing physics-based controllers to a wide range of new styles for locomotion, new task targets, changes in character morphology and extensive changes in environment. Furthermore, it exhibits significant increase in learning efficiency, as indicated by greatly reduced training times when compared to training from scratch or using other approaches that modify existing policies. Code is available at https://motion-lab.github.io/AdaptNet.
* SIGGRAPH Asia 2023. Video: https://youtu.be/WxmJSCNFb28. Website: https://motion-lab.github.io/AdaptNet, https://pei-xu.github.io/AdaptNet
A Study in Zucker: Insights on Human-Robot Interactions
Jul 17, 2023



In recent years there has been a large focus on how robots can operate in human populated environments. In this paper, we focus on interactions between humans and small indoor robots and introduce a new human-robot interaction (HRI) dataset. The analysis of the recorded experiments shows that anticipatory and non-reactive robot controllers impose similar constraints to humans' safety and efficiency. Additionally, we found that current state-of-the-art models for human trajectory prediction can adequately extend to indoor HRI settings. Finally, we show that humans respond differently in shared and homogeneous environments when collisions are imminent, since interacting with small differential drives can only cause a finite level of social discomfort as compared to human-human interactions. The dataset used in this analysis is available at: https://github.com/AlexanderDavid/ZuckerDataset.
Composite Motion Learning with Task Control
May 05, 2023



We present a deep learning method for composite and task-driven motion control for physically simulated characters. In contrast to existing data-driven approaches using reinforcement learning that imitate full-body motions, we learn decoupled motions for specific body parts from multiple reference motions simultaneously and directly by leveraging the use of multiple discriminators in a GAN-like setup. In this process, there is no need of any manual work to produce composite reference motions for learning. Instead, the control policy explores by itself how the composite motions can be combined automatically. We further account for multiple task-specific rewards and train a single, multi-objective control policy. To this end, we propose a novel framework for multi-objective learning that adaptively balances the learning of disparate motions from multiple sources and multiple goal-directed control objectives. In addition, as composite motions are typically augmentations of simpler behaviors, we introduce a sample-efficient method for training composite control policies in an incremental manner, where we reuse a pre-trained policy as the meta policy and train a cooperative policy that adapts the meta one for new composite tasks. We show the applicability of our approach on a variety of challenging multi-objective tasks involving both composite motion imitation and multiple goal-directed control.
* SIGGRAPH 2023. Code: https://github.com/xupei0610/CompositeMotion. Video: https://youtu.be/mcRAxwoTh3E
Context-Aware Timewise VAEs for Real-Time Vehicle Trajectory Prediction
Feb 21, 2023



Real-time, accurate prediction of human steering behaviors has wide applications, from developing intelligent traffic systems to deploying autonomous driving systems in both real and simulated worlds. In this paper, we present ContextVAE, a context-aware approach for multi-modal vehicle trajectory prediction. Built upon the backbone architecture of a timewise variational autoencoder, ContextVAE employs a dual attention mechanism for observation encoding that accounts for the environmental context information and the dynamic agents' states in a unified way. By utilizing features extracted from semantic maps during agent state encoding, our approach takes into account both the social features exhibited by agents on the scene and the physical environment constraints to generate map-compliant and socially-aware trajectories. We perform extensive testing on the nuScenes prediction challenge, Lyft Level 5 dataset and Waymo Open Motion Dataset to show the effectiveness of our approach and its state-of-the-art performance. In all tested datasets, ContextVAE models are fast to train and provide high-quality multi-modal predictions in real-time.
SocialVAE: Human Trajectory Prediction using Timewise Latents
Mar 29, 2022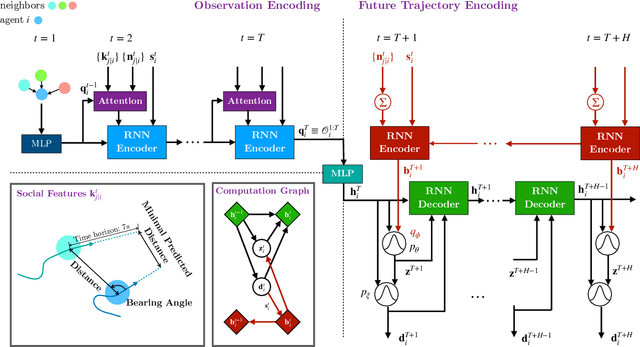
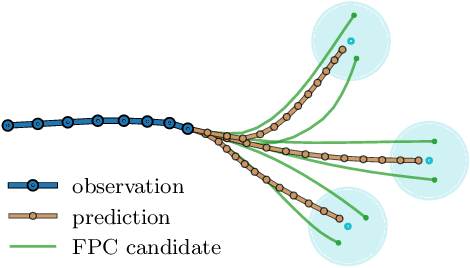
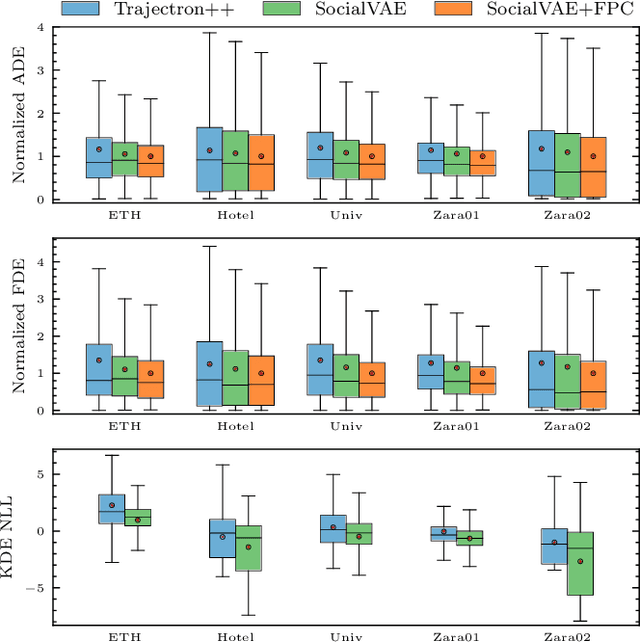
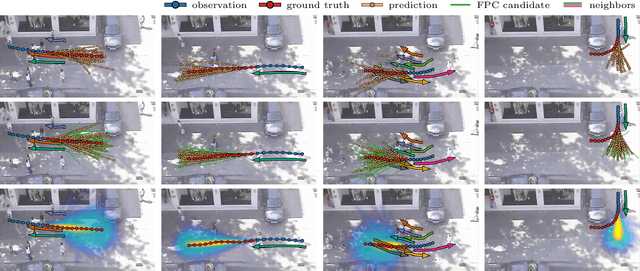
Predicting pedestrian movement is critical for human behavior analysis and also for safe and efficient human-agent interactions. However, despite significant advancements, it is still challenging for existing approaches to capture the uncertainty and multimodality of human navigation decision making. In this paper, we propose SocialVAE, a novel approach for human trajectory prediction. The core of SocialVAE is a timewise variational autoencoder architecture that exploits stochastic recurrent neural networks to perform prediction, combined with a social attention mechanism and backward posterior approximation to allow for better extraction of pedestrian navigation strategies. We show that SocialVAE improves current state-of-the-art performance on several pedestrian trajectory prediction benchmarks, including the ETH/UCY benchmark, the Stanford Drone Dataset and SportVU NBA movement dataset. Code is available at: https://github.com/xupei0610/SocialVAE.
A GAN-Like Approach for Physics-Based Imitation Learning and Interactive Character Control
May 21, 2021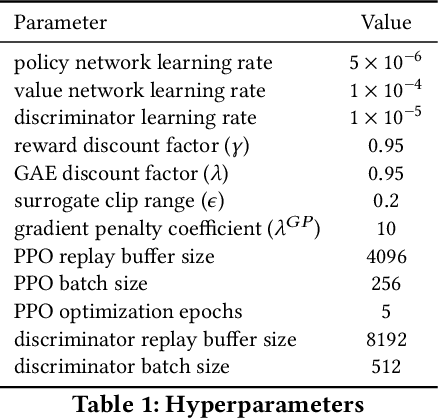

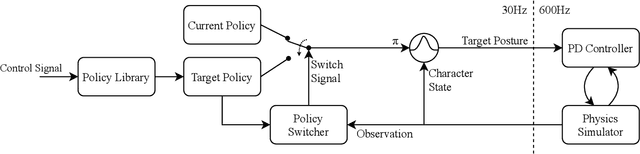
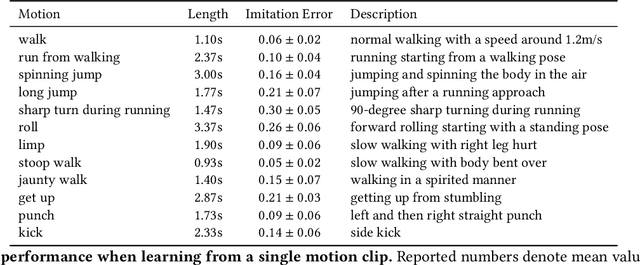
We present a simple and intuitive approach for interactive control of physically simulated characters. Our work builds upon generative adversarial networks (GAN) and reinforcement learning, and introduces an imitation learning framework where an ensemble of classifiers and an imitation policy are trained in tandem given pre-processed reference clips. The classifiers are trained to discriminate the reference motion from the motion generated by the imitation policy, while the policy is rewarded for fooling the discriminators. Using our GAN-based approach, multiple motor control policies can be trained separately to imitate different behaviors. In runtime, our system can respond to external control signal provided by the user and interactively switch between different policies. Compared to existing methods, our proposed approach has the following attractive properties: 1) achieves state-of-the-art imitation performance without manually designing and fine tuning a reward function; 2) directly controls the character without having to track any target reference pose explicitly or implicitly through a phase state; and 3) supports interactive policy switching without requiring any motion generation or motion matching mechanism. We highlight the applicability of our approach in a range of imitation and interactive control tasks, while also demonstrating its ability to withstand external perturbations as well as to recover balance. Overall, our approach generates high-fidelity motion, has low runtime cost, and can be easily integrated into interactive applications and games.
Human-Inspired Multi-Agent Navigation using Knowledge Distillation
Mar 20, 2021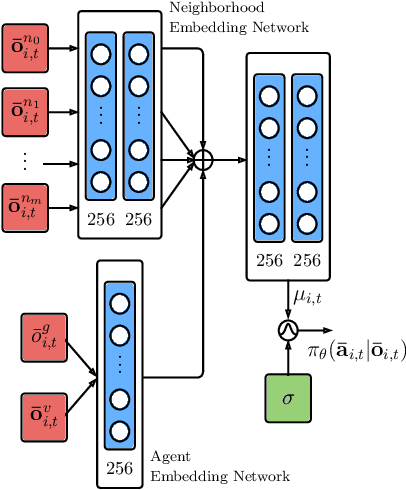
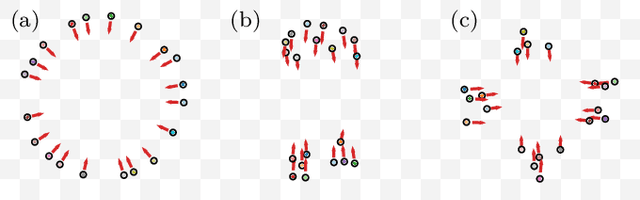
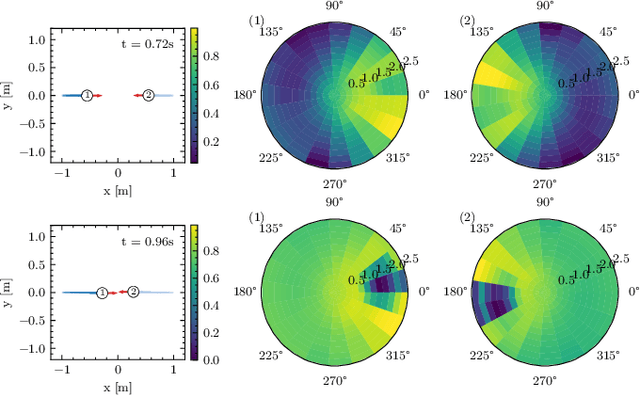
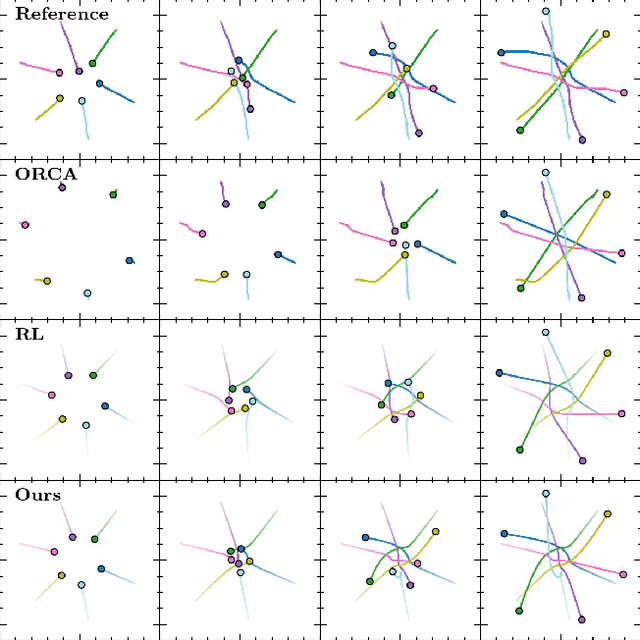
Despite significant advancements in the field of multi-agent navigation, agents still lack the sophistication and intelligence that humans exhibit in multi-agent settings. In this paper, we propose a framework for learning a human-like general collision avoidance policy for agent-agent interactions in fully decentralized, multi-agent environments. Our approach uses knowledge distillation with reinforcement learning to shape the reward function based on expert policies extracted from human trajectory demonstrations through behavior cloning. We show that agents trained with our approach can take human-like trajectories in collision avoidance and goal-directed steering tasks not provided by the demonstrations, outperforming the experts as well as learning-based agents trained without knowledge distillation.
Particle-Based Adaptive Discretization for Continuous Control using Deep Reinforcement Learning
Mar 16, 2020

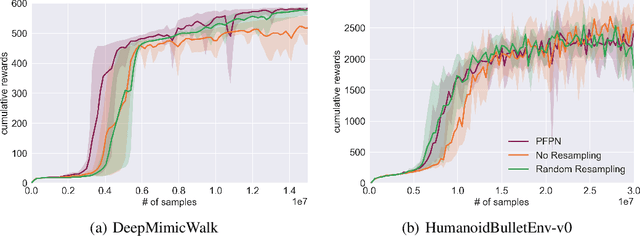
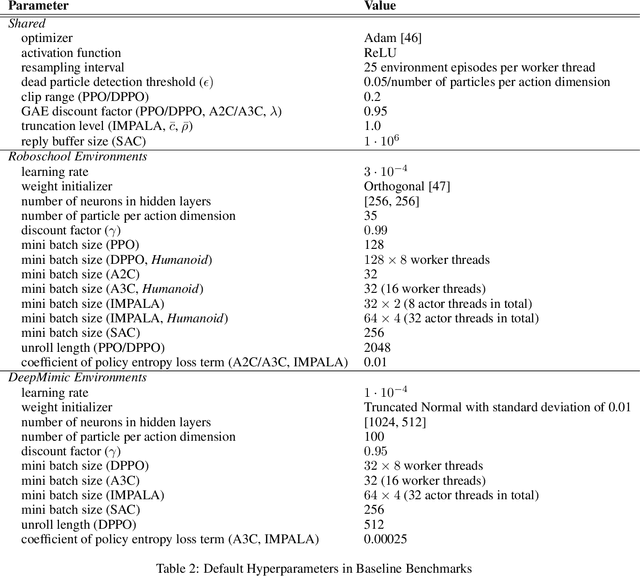
Learning controls in high-dimensional continuous action spaces, such as controlling the movements of highly articulated agents and robots, has long been a standing challenge to model-free deep reinforcement learning (DRL). In this paper we propose a general, yet simple, framework for improving the action exploration of policy gradient DRL algorithms. Our approach adapts ideas from the particle filtering literature to dynamically discretize the continuous action space and track policies represented as a mixture of Gaussians. We demonstrate the applicability of our approach on state-of-the-art DRL baselines in challenging high-dimensional motor tasks involving articulated agents. We show that our adaptive particle-based discretization leads to improved final performance and speed of convergence as compared to uniform discretization schemes and to corresponding implementations in continuous action spaces, highlighting the importance of exploration. In addition, the resulting policies are more stable, exhibiting less variance across different training trials.