 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironment-aware Motion Matching
Oct 26, 2025
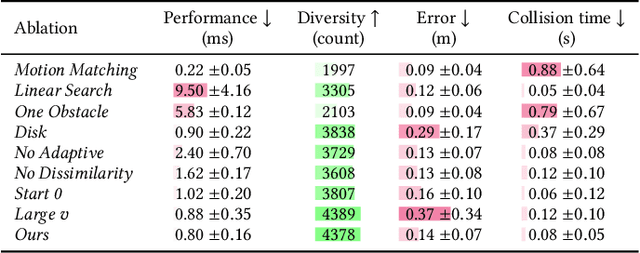
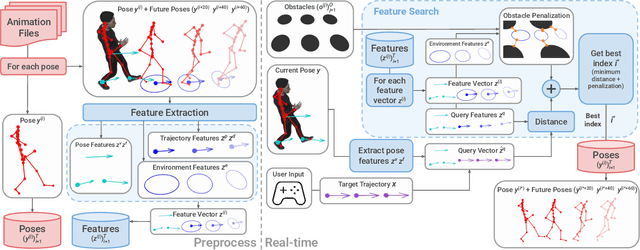
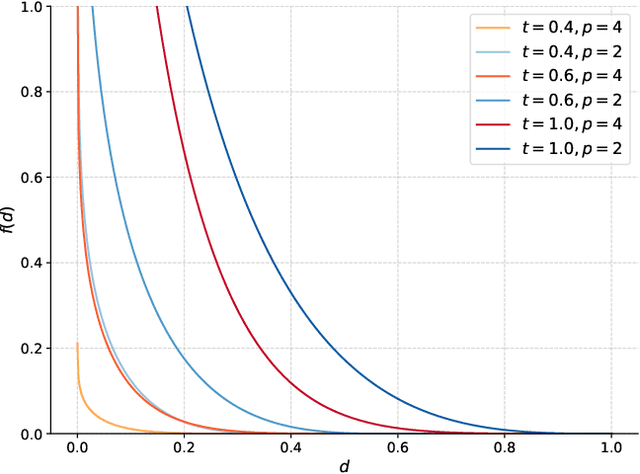
Interactive applications demand believable characters that respond naturally to dynamic environments. Traditional character animation techniques often struggle to handle arbitrary situations, leading to a growing trend of dynamically selecting motion-captured animations based on predefined features. While Motion Matching has proven effective for locomotion by aligning to target trajectories, animating environment interactions and crowd behaviors remains challenging due to the need to consider surrounding elements. Existing approaches often involve manual setup or lack the naturalism of motion capture. Furthermore, in crowd animation, body animation is frequently treated as a separate process from trajectory planning, leading to inconsistencies between body pose and root motion. To address these limitations, we present Environment-aware Motion Matching, a novel real-time system for full-body character animation that dynamically adapts to obstacles and other agents, emphasizing the bidirectional relationship between pose and trajectory. In a preprocessing step, we extract shape, pose, and trajectory features from a motion capture database. At runtime, we perform an efficient search that matches user input and current pose while penalizing collisions with a dynamic environment. Our method allows characters to naturally adjust their pose and trajectory to navigate crowded scenes.
Multi-person Physics-based Pose Estimation for Combat Sports
Apr 11, 2025We propose a novel framework for accurate 3D human pose estimation in combat sports using sparse multi-camera setups. Our method integrates robust multi-view 2D pose tracking via a transformer-based top-down approach, employing epipolar geometry constraints and long-term video object segmentation for consistent identity tracking across views. Initial 3D poses are obtained through weighted triangulation and spline smoothing, followed by kinematic optimization to refine pose accuracy. We further enhance pose realism and robustness by introducing a multi-person physics-based trajectory optimization step, effectively addressing challenges such as rapid motions, occlusions, and close interactions. Experimental results on diverse datasets, including a new benchmark of elite boxing footage, demonstrate state-of-the-art performance. Additionally, we release comprehensive annotated video datasets to advance future research in multi-person pose estimation for combat sports.
Learning to Play Atari in a World of Tokens
Jun 03, 2024



Model-based reinforcement learning agents utilizing transformers have shown improved sample efficiency due to their ability to model extended context, resulting in more accurate world models. However, for complex reasoning and planning tasks, these methods primarily rely on continuous representations. This complicates modeling of discrete properties of the real world such as disjoint object classes between which interpolation is not plausible. In this work, we introduce discrete abstract representations for transformer-based learning (DART), a sample-efficient method utilizing discrete representations for modeling both the world and learning behavior. We incorporate a transformer-decoder for auto-regressive world modeling and a transformer-encoder for learning behavior by attending to task-relevant cues in the discrete representation of the world model. For handling partial observability, we aggregate information from past time steps as memory tokens. DART outperforms previous state-of-the-art methods that do not use look-ahead search on the Atari 100k sample efficiency benchmark with a median human-normalized score of 0.790 and beats humans in 9 out of 26 games. We release our code at https://pranaval.github.io/DART/.
AdaptNet: Policy Adaptation for Physics-Based Character Control
Oct 09, 2023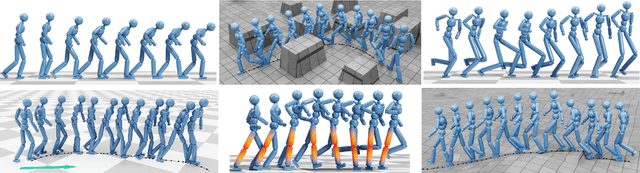
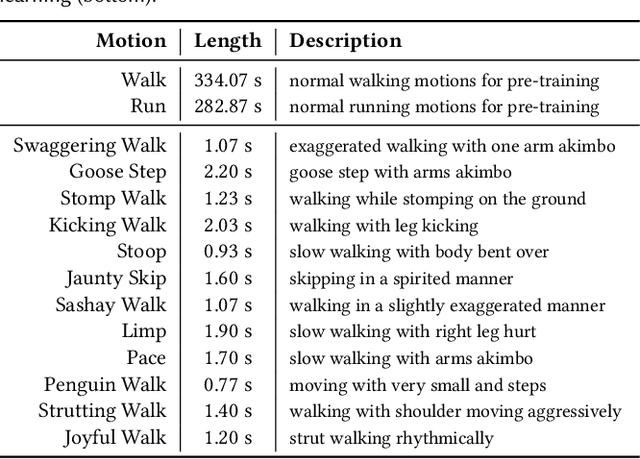
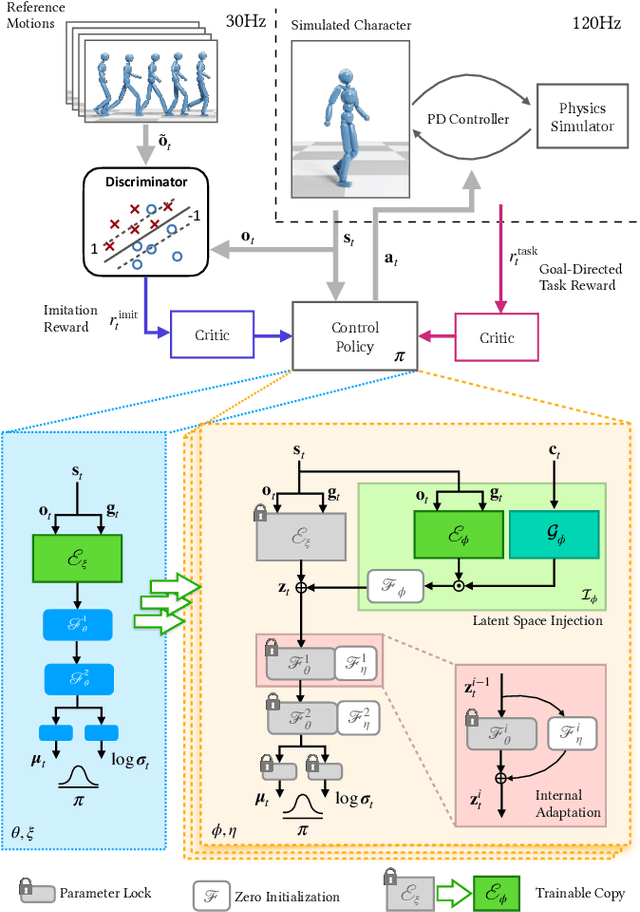
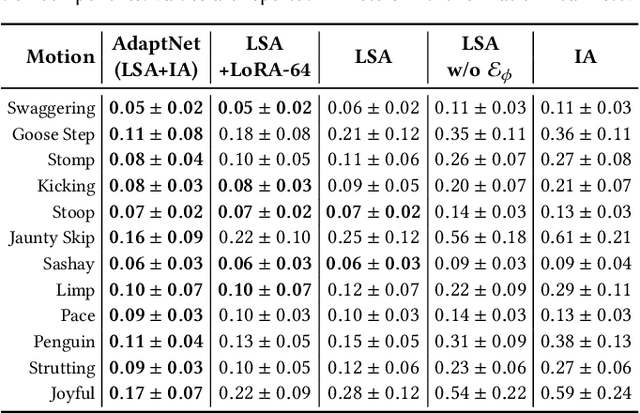
Motivated by humans' ability to adapt skills in the learning of new ones, this paper presents AdaptNet, an approach for modifying the latent space of existing policies to allow new behaviors to be quickly learned from like tasks in comparison to learning from scratch. Building on top of a given reinforcement learning controller, AdaptNet uses a two-tier hierarchy that augments the original state embedding to support modest changes in a behavior and further modifies the policy network layers to make more substantive changes. The technique is shown to be effective for adapting existing physics-based controllers to a wide range of new styles for locomotion, new task targets, changes in character morphology and extensive changes in environment. Furthermore, it exhibits significant increase in learning efficiency, as indicated by greatly reduced training times when compared to training from scratch or using other approaches that modify existing policies. Code is available at https://motion-lab.github.io/AdaptNet.
* SIGGRAPH Asia 2023. Video: https://youtu.be/WxmJSCNFb28. Website: https://motion-lab.github.io/AdaptNet, https://pei-xu.github.io/AdaptNet
Automatic Evaluation of Excavator Operators using Learned Reward Functions
Nov 15, 2022Training novice users to operate an excavator for learning different skills requires the presence of expert teachers. Considering the complexity of the problem, it is comparatively expensive to find skilled experts as the process is time-consuming and requires precise focus. Moreover, since humans tend to be biased, the evaluation process is noisy and will lead to high variance in the final score of different operators with similar skills. In this work, we address these issues and propose a novel strategy for the automatic evaluation of excavator operators. We take into account the internal dynamics of the excavator and the safety criterion at every time step to evaluate the performance. To further validate our approach, we use this score prediction model as a source of reward for a reinforcement learning agent to learn the task of maneuvering an excavator in a simulated environment that closely replicates the real-world dynamics. For a policy learned using these external reward prediction models, our results demonstrate safer solutions following the required dynamic constraints when compared to policy trained with task-based reward functions only, making it one step closer to real-life adoption. For future research, we release our codebase at https://github.com/pranavAL/InvRL_Auto-Evaluate and video results https://drive.google.com/file/d/1jR1otOAu8zrY8mkhUOUZW9jkBOAKK71Z/view?usp=share_link .