 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Differentiable Boolean Operator with Fuzzy Logic
Jul 15, 2024

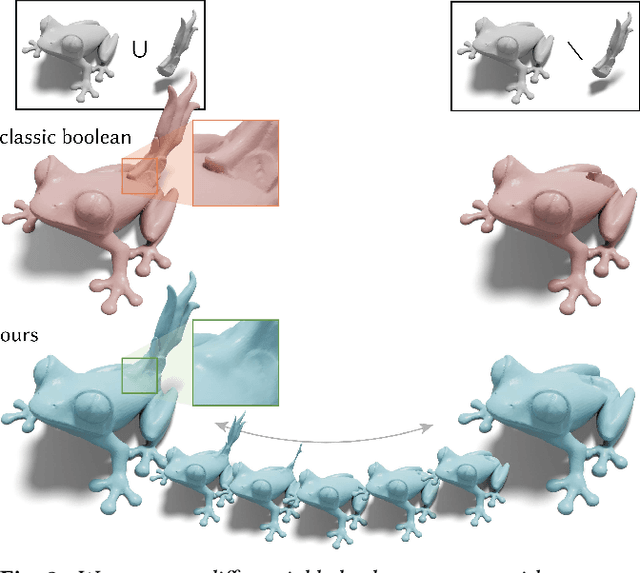

This paper presents a unified differentiable boolean operator for implicit solid shape modeling using Constructive Solid Geometry (CSG). Traditional CSG relies on min, max operators to perform boolean operations on implicit shapes. But because these boolean operators are discontinuous and discrete in the choice of operations, this makes optimization over the CSG representation challenging. Drawing inspiration from fuzzy logic, we present a unified boolean operator that outputs a continuous function and is differentiable with respect to operator types. This enables optimization of both the primitives and the boolean operations employed in CSG with continuous optimization techniques, such as gradient descent. We further demonstrate that such a continuous boolean operator allows modeling of both sharp mechanical objects and smooth organic shapes with the same framework. Our proposed boolean operator opens up new possibilities for future research toward fully continuous CSG optimization.
Diffusion Synthesizer for Efficient Multilingual Speech to Speech Translation
Jun 14, 2024



We introduce DiffuseST, a low-latency, direct speech-to-speech translation system capable of preserving the input speaker's voice zero-shot while translating from multiple source languages into English. We experiment with the synthesizer component of the architecture, comparing a Tacotron-based synthesizer to a novel diffusion-based synthesizer. We find the diffusion-based synthesizer to improve MOS and PESQ audio quality metrics by 23\% each and speaker similarity by 5\% while maintaining comparable BLEU scores. Despite having more than double the parameter count, the diffusion synthesizer has lower latency, allowing the entire model to run more than 5$\times$ faster than real-time.
Enhancing Multilingual Voice Toxicity Detection with Speech-Text Alignment
Jun 14, 2024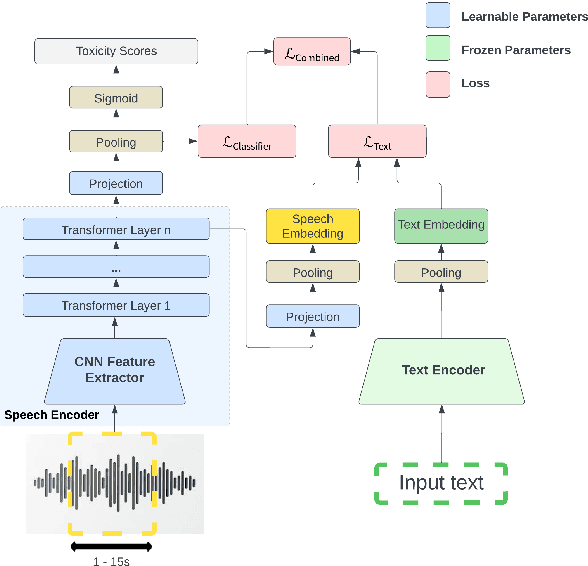
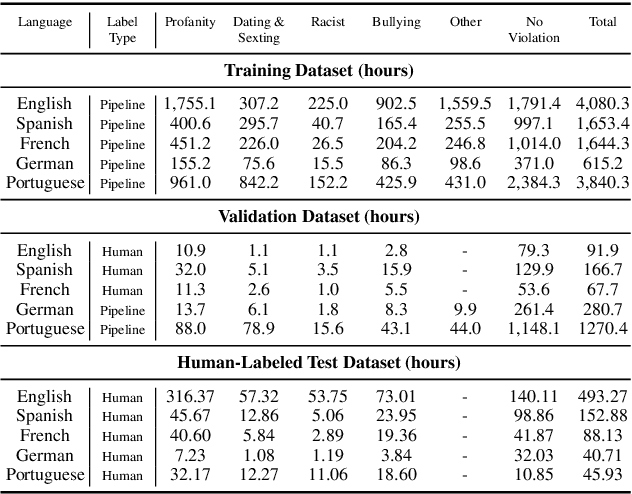
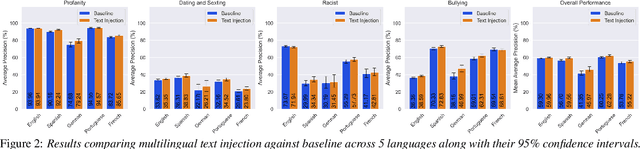
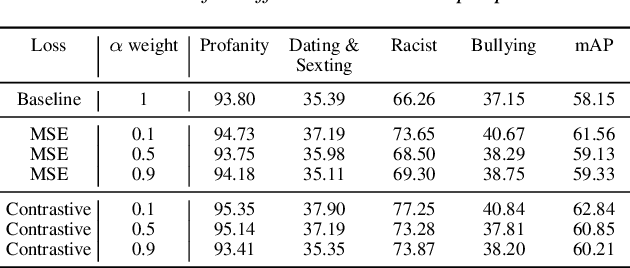
Toxicity classification for voice heavily relies on the semantic content of speech. We propose a novel framework that utilizes cross-modal learning to integrate the semantic embedding of text into a multilabel speech toxicity classifier during training. This enables us to incorporate textual information during training while still requiring only audio during inference. We evaluate this classifier on large-scale datasets with real-world characteristics to validate the effectiveness of this framework. Through ablation studies, we demonstrate that general-purpose semantic text embeddings are rich and aligned with speech for toxicity classification purposes. Conducting experiments across multiple languages at scale, we show improvements in voice toxicity classification across five languages and different toxicity categories.
AdaptNet: Policy Adaptation for Physics-Based Character Control
Oct 09, 2023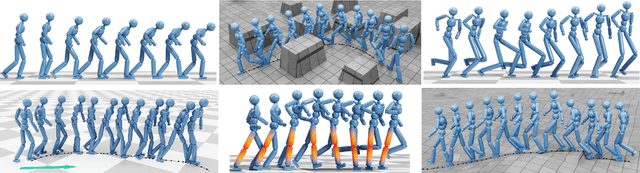
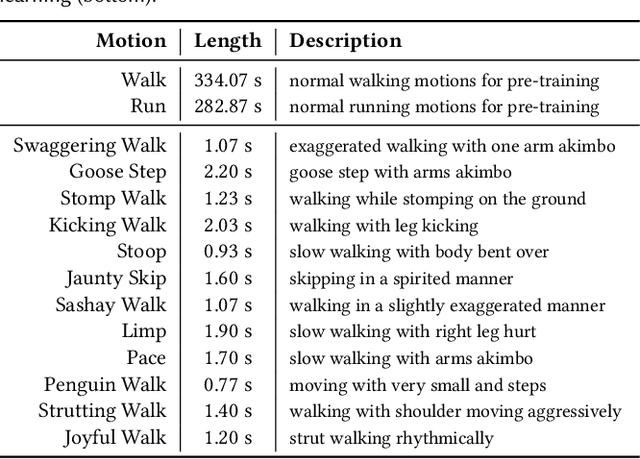
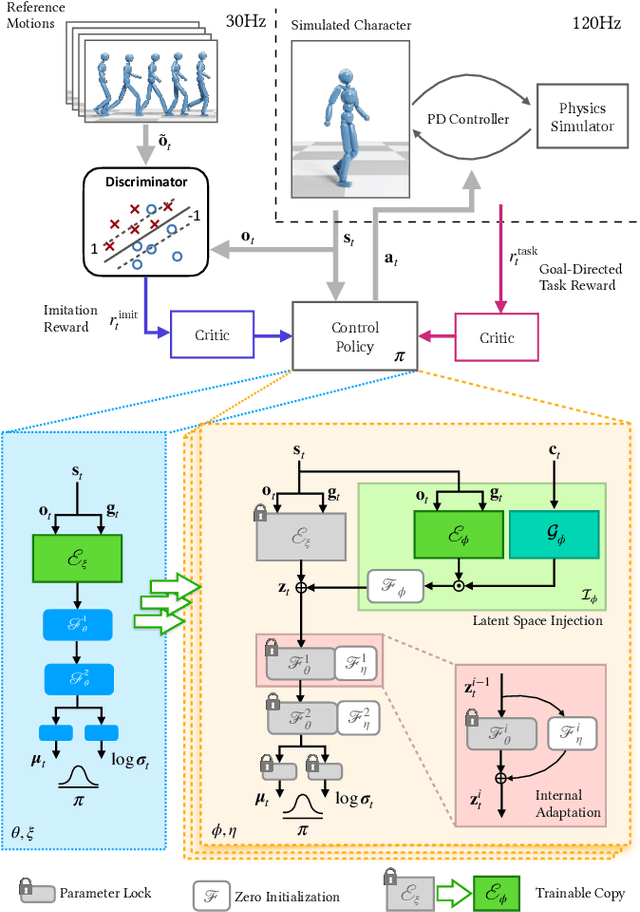
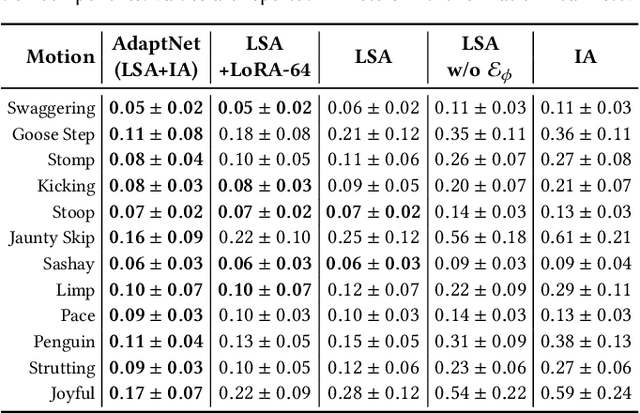
Motivated by humans' ability to adapt skills in the learning of new ones, this paper presents AdaptNet, an approach for modifying the latent space of existing policies to allow new behaviors to be quickly learned from like tasks in comparison to learning from scratch. Building on top of a given reinforcement learning controller, AdaptNet uses a two-tier hierarchy that augments the original state embedding to support modest changes in a behavior and further modifies the policy network layers to make more substantive changes. The technique is shown to be effective for adapting existing physics-based controllers to a wide range of new styles for locomotion, new task targets, changes in character morphology and extensive changes in environment. Furthermore, it exhibits significant increase in learning efficiency, as indicated by greatly reduced training times when compared to training from scratch or using other approaches that modify existing policies. Code is available at https://motion-lab.github.io/AdaptNet.
* SIGGRAPH Asia 2023. Video: https://youtu.be/WxmJSCNFb28. Website: https://motion-lab.github.io/AdaptNet, https://pei-xu.github.io/AdaptNet
Learning When to Speak: Latency and Quality Trade-offs for Simultaneous Speech-to-Speech Translation with Offline Models
Jun 01, 2023

Recent work in speech-to-speech translation (S2ST) has focused primarily on offline settings, where the full input utterance is available before any output is given. This, however, is not reasonable in many real-world scenarios. In latency-sensitive applications, rather than waiting for the full utterance, translations should be spoken as soon as the information in the input is present. In this work, we introduce a system for simultaneous S2ST targeting real-world use cases. Our system supports translation from 57 languages to English with tunable parameters for dynamically adjusting the latency of the output -- including four policies for determining when to speak an output sequence. We show that these policies achieve offline-level accuracy with minimal increases in latency over a Greedy (wait-$k$) baseline. We open-source our evaluation code and interactive test script to aid future SimulS2ST research and application development.
Variable Bitrate Neural Fields
Jun 15, 2022
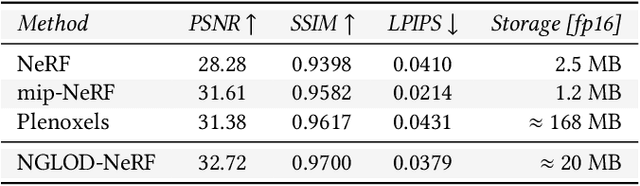

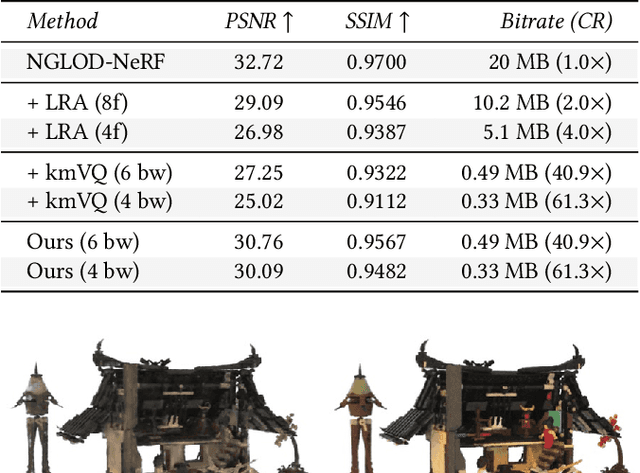
Neural approximations of scalar and vector fields, such as signed distance functions and radiance fields, have emerged as accurate, high-quality representations. State-of-the-art results are obtained by conditioning a neural approximation with a lookup from trainable feature grids that take on part of the learning task and allow for smaller, more efficient neural networks. Unfortunately, these feature grids usually come at the cost of significantly increased memory consumption compared to stand-alone neural network models. We present a dictionary method for compressing such feature grids, reducing their memory consumption by up to 100x and permitting a multiresolution representation which can be useful for out-of-core streaming. We formulate the dictionary optimization as a vector-quantized auto-decoder problem which lets us learn end-to-end discrete neural representations in a space where no direct supervision is available and with dynamic topology and structure. Our source code will be available at https://github.com/nv-tlabs/vqad.
Robust Vision-Based Cheat Detection in Competitive Gaming
Mar 27, 2021



Game publishers and anti-cheat companies have been unsuccessful in blocking cheating in online gaming. We propose a novel, vision-based approach that captures the final state of the frame buffer and detects illicit overlays. To this aim, we train and evaluate a DNN detector on a new dataset, collected using two first-person shooter games and three cheating software. We study the advantages and disadvantages of different DNN architectures operating on a local or global scale. We use output confidence analysis to avoid unreliable detections and inform when network retraining is required. In an ablation study, we show how to use Interval Bound Propagation to build a detector that is also resistant to potential adversarial attacks and study its interaction with confidence analysis. Our results show that robust and effective anti-cheating through machine learning is practically feasible and can be used to guarantee fair play in online gaming.
Neural Geometric Level of Detail: Real-time Rendering with Implicit 3D Shapes
Jan 26, 2021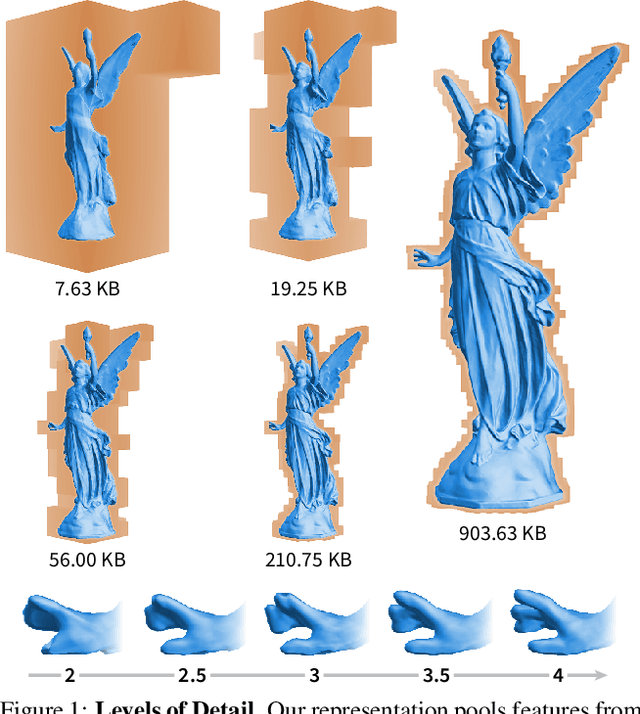
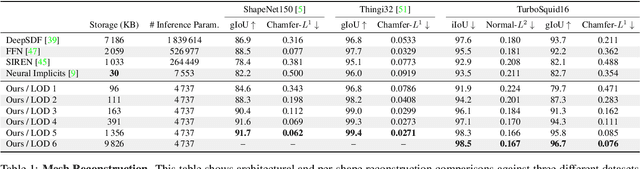

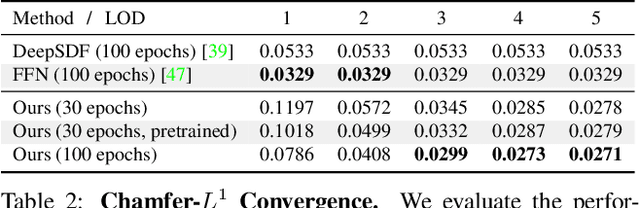
Neural signed distance functions (SDFs) are emerging as an effective representation for 3D shapes. State-of-the-art methods typically encode the SDF with a large, fixed-size neural network to approximate complex shapes with implicit surfaces. Rendering with these large networks is, however, computationally expensive since it requires many forward passes through the network for every pixel, making these representations impractical for real-time graphics. We introduce an efficient neural representation that, for the first time, enables real-time rendering of high-fidelity neural SDFs, while achieving state-of-the-art geometry reconstruction quality. We represent implicit surfaces using an octree-based feature volume which adaptively fits shapes with multiple discrete levels of detail (LODs), and enables continuous LOD with SDF interpolation. We further develop an efficient algorithm to directly render our novel neural SDF representation in real-time by querying only the necessary LODs with sparse octree traversal. We show that our representation is 2-3 orders of magnitude more efficient in terms of rendering speed compared to previous works. Furthermore, it produces state-of-the-art reconstruction quality for complex shapes under both 3D geometric and 2D image-space metrics.
Learning Deformable Tetrahedral Meshes for 3D Reconstruction
Nov 03, 2020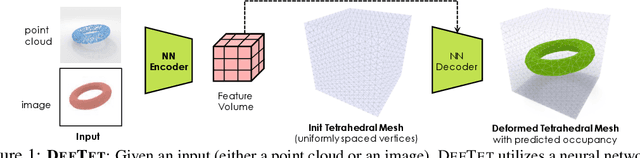
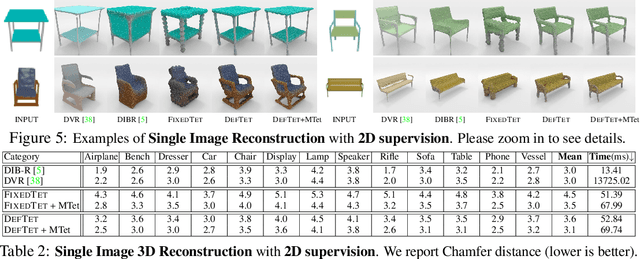
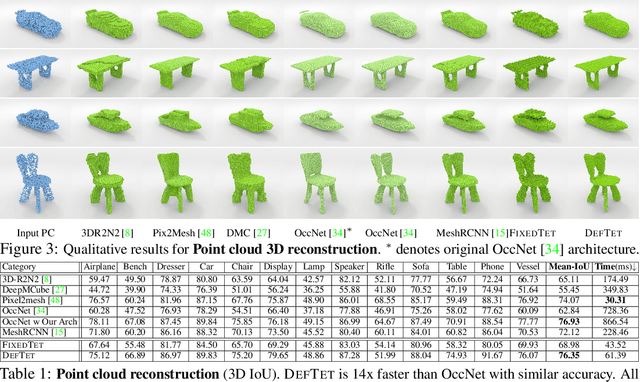

3D shape representations that accommodate learning-based 3D reconstruction are an open problem in machine learning and computer graphics. Previous work on neural 3D reconstruction demonstrated benefits, but also limitations, of point cloud, voxel, surface mesh, and implicit function representations. We introduce Deformable Tetrahedral Meshes (DefTet) as a particular parameterization that utilizes volumetric tetrahedral meshes for the reconstruction problem. Unlike existing volumetric approaches, DefTet optimizes for both vertex placement and occupancy, and is differentiable with respect to standard 3D reconstruction loss functions. It is thus simultaneously high-precision, volumetric, and amenable to learning-based neural architectures. We show that it can represent arbitrary, complex topology, is both memory and computationally efficient, and can produce high-fidelity reconstructions with a significantly smaller grid size than alternative volumetric approaches. The predicted surfaces are also inherently defined as tetrahedral meshes, thus do not require post-processing. We demonstrate that DefTet matches or exceeds both the quality of the previous best approaches and the performance of the fastest ones. Our approach obtains high-quality tetrahedral meshes computed directly from noisy point clouds, and is the first to showcase high-quality 3D tet-mesh results using only a single image as input.