 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multilingual Voice Toxicity Detection with Speech-Text Alignment
Paper and Code
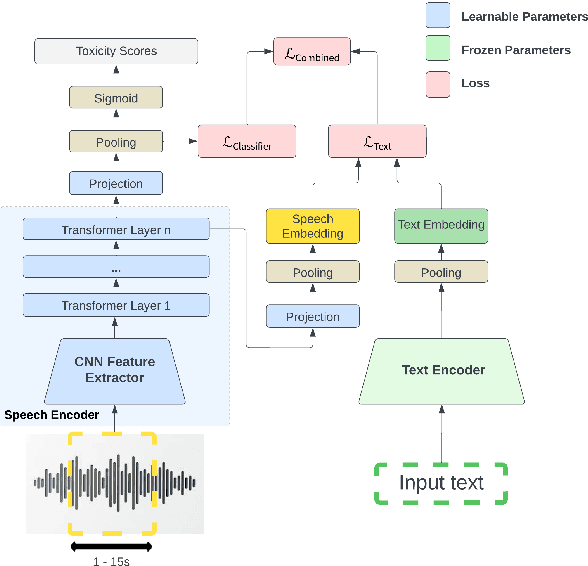
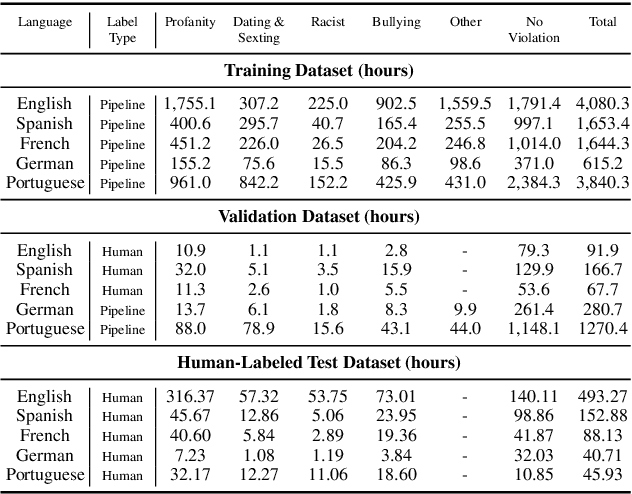
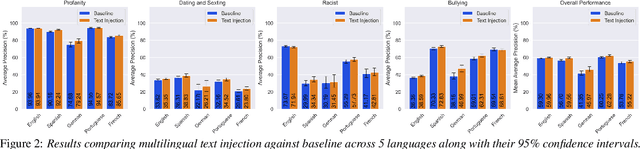
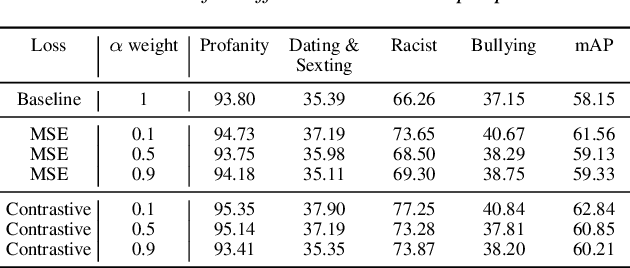
Toxicity classification for voice heavily relies on the semantic content of speech. We propose a novel framework that utilizes cross-modal learning to integrate the semantic embedding of text into a multilabel speech toxicity classifier during training. This enables us to incorporate textual information during training while still requiring only audio during inference. We evaluate this classifier on large-scale datasets with real-world characteristics to validate the effectiveness of this framework. Through ablation studies, we demonstrate that general-purpose semantic text embeddings are rich and aligned with speech for toxicity classification purposes. Conducting experiments across multiple languages at scale, we show improvements in voice toxicity classification across five languages and different toxicity categories.