 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREINA: Regularized Entropy Information-Based Loss for Efficient Simultaneous Speech Translation
Aug 07, 2025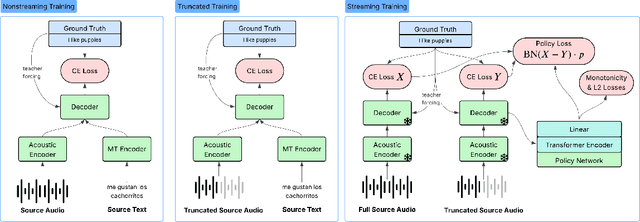
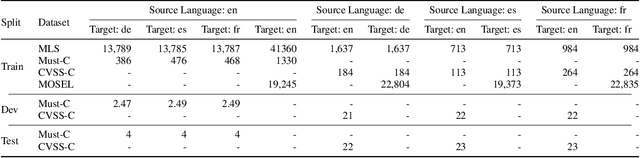
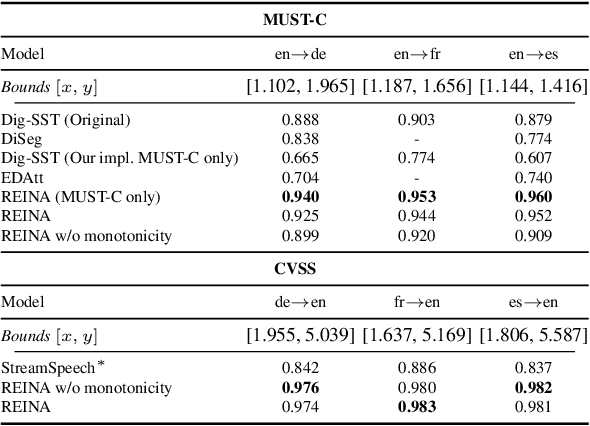
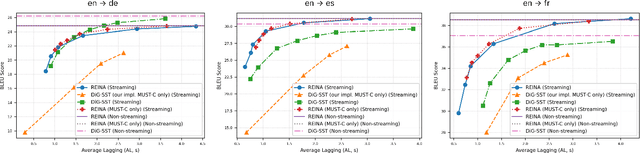
Simultaneous Speech Translation (SimulST) systems stream in audio while simultaneously emitting translated text or speech. Such systems face the significant challenge of balancing translation quality and latency. We introduce a strategy to optimize this tradeoff: wait for more input only if you gain information by doing so. Based on this strategy, we present Regularized Entropy INformation Adaptation (REINA), a novel loss to train an adaptive policy using an existing non-streaming translation model. We derive REINA from information theory principles and show that REINA helps push the reported Pareto frontier of the latency/quality tradeoff over prior works. Utilizing REINA, we train a SimulST model on French, Spanish and German, both from and into English. Training on only open source or synthetically generated data, we achieve state-of-the-art (SOTA) streaming results for models of comparable size. We also introduce a metric for streaming efficiency, quantitatively showing REINA improves the latency/quality trade-off by as much as 21% compared to prior approaches, normalized against non-streaming baseline BLEU scores.
SmoothCache: A Universal Inference Acceleration Technique for Diffusion Transformers
Nov 15, 2024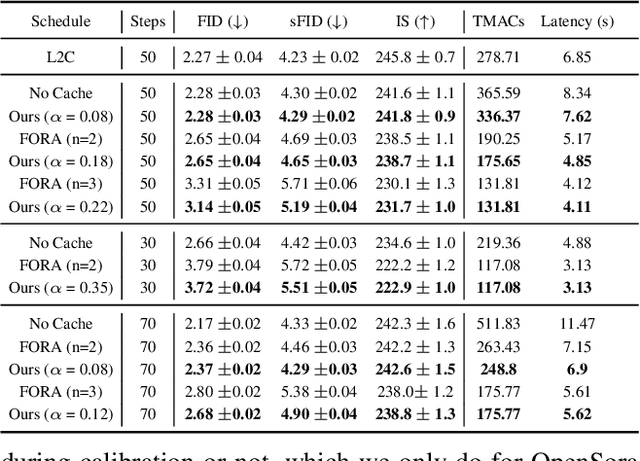
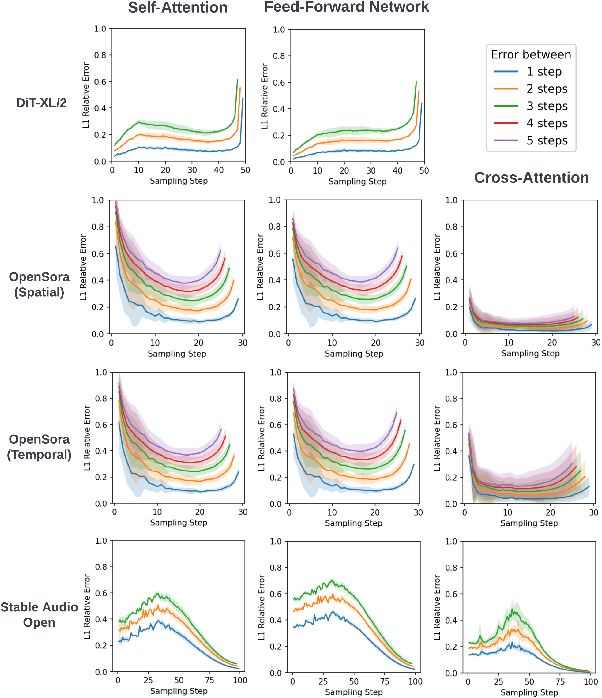

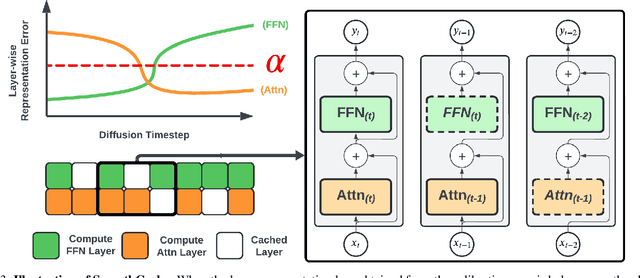
Diffusion Transformers (DiT) have emerged as powerful generative models for various tasks, including image, video, and speech synthesis. However, their inference process remains computationally expensive due to the repeated evaluation of resource-intensive attention and feed-forward modules. To address this, we introduce SmoothCache, a model-agnostic inference acceleration technique for DiT architectures. SmoothCache leverages the observed high similarity between layer outputs across adjacent diffusion timesteps. By analyzing layer-wise representation errors from a small calibration set, SmoothCache adaptively caches and reuses key features during inference. Our experiments demonstrate that SmoothCache achieves 8% to 71% speed up while maintaining or even improving generation quality across diverse modalities. We showcase its effectiveness on DiT-XL for image generation, Open-Sora for text-to-video, and Stable Audio Open for text-to-audio, highlighting its potential to enable real-time applications and broaden the accessibility of powerful DiT models.
Diffusion Synthesizer for Efficient Multilingual Speech to Speech Translation
Jun 14, 2024



We introduce DiffuseST, a low-latency, direct speech-to-speech translation system capable of preserving the input speaker's voice zero-shot while translating from multiple source languages into English. We experiment with the synthesizer component of the architecture, comparing a Tacotron-based synthesizer to a novel diffusion-based synthesizer. We find the diffusion-based synthesizer to improve MOS and PESQ audio quality metrics by 23\% each and speaker similarity by 5\% while maintaining comparable BLEU scores. Despite having more than double the parameter count, the diffusion synthesizer has lower latency, allowing the entire model to run more than 5$\times$ faster than real-time.
Enhancing Multilingual Voice Toxicity Detection with Speech-Text Alignment
Jun 14, 2024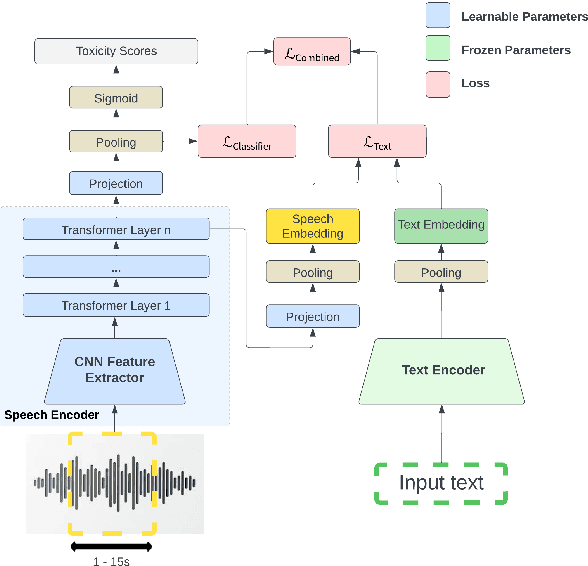
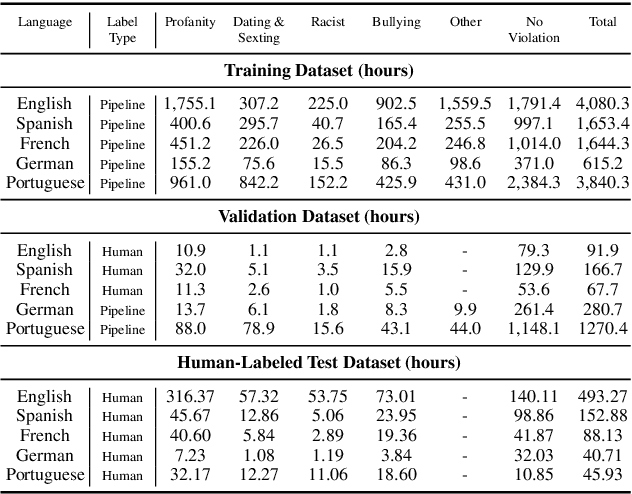
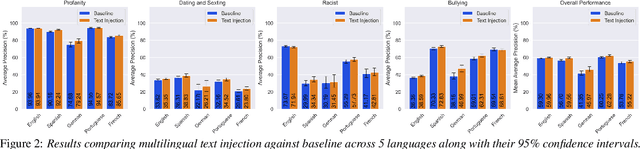
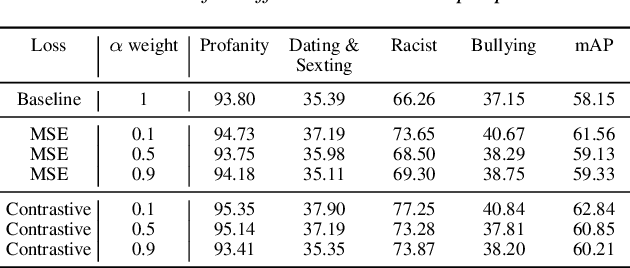
Toxicity classification for voice heavily relies on the semantic content of speech. We propose a novel framework that utilizes cross-modal learning to integrate the semantic embedding of text into a multilabel speech toxicity classifier during training. This enables us to incorporate textual information during training while still requiring only audio during inference. We evaluate this classifier on large-scale datasets with real-world characteristics to validate the effectiveness of this framework. Through ablation studies, we demonstrate that general-purpose semantic text embeddings are rich and aligned with speech for toxicity classification purposes. Conducting experiments across multiple languages at scale, we show improvements in voice toxicity classification across five languages and different toxicity categories.