 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multilingual Voice Toxicity Detection with Speech-Text Alignment
Jun 14, 2024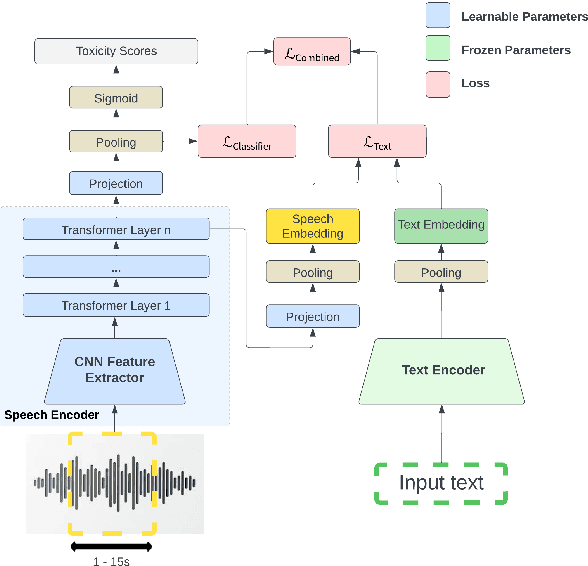
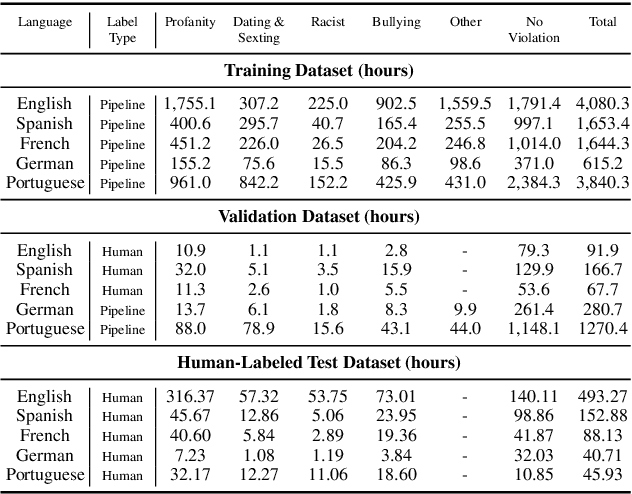
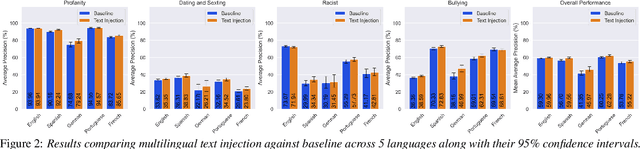
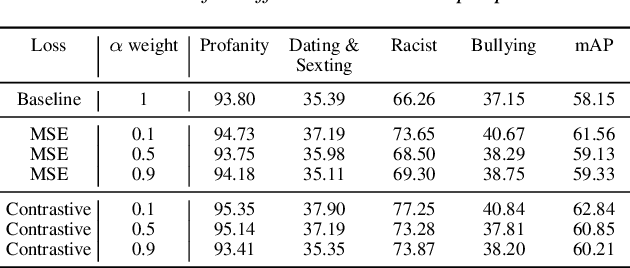
Toxicity classification for voice heavily relies on the semantic content of speech. We propose a novel framework that utilizes cross-modal learning to integrate the semantic embedding of text into a multilabel speech toxicity classifier during training. This enables us to incorporate textual information during training while still requiring only audio during inference. We evaluate this classifier on large-scale datasets with real-world characteristics to validate the effectiveness of this framework. Through ablation studies, we demonstrate that general-purpose semantic text embeddings are rich and aligned with speech for toxicity classification purposes. Conducting experiments across multiple languages at scale, we show improvements in voice toxicity classification across five languages and different toxicity categories.
Fast Text-Only Domain Adaptation of RNN-Transducer Prediction Network
Apr 22, 2021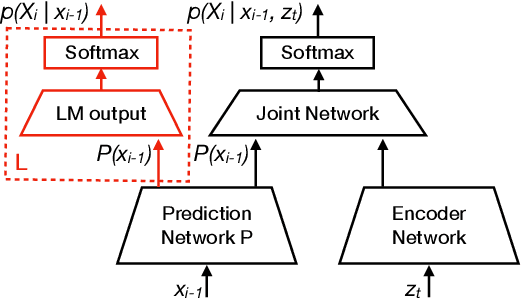

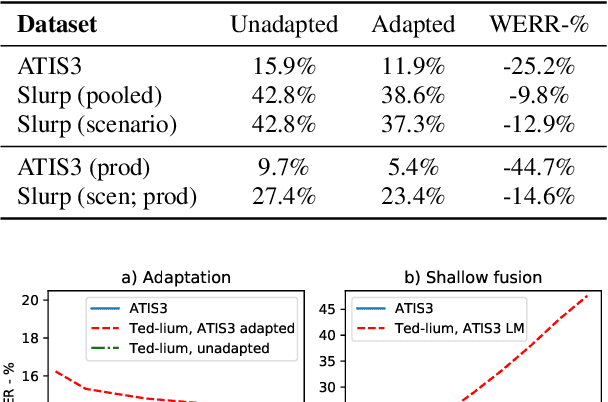
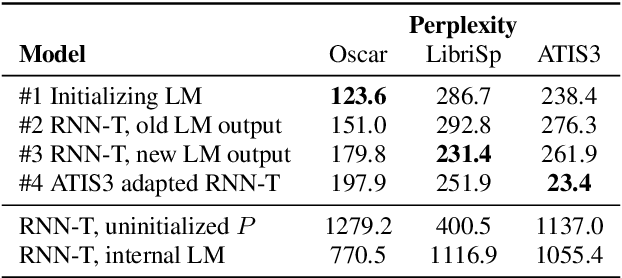
Adaption of end-to-end speech recognition systems to new tasks is known to be challenging. A number of solutions have been proposed which apply external language models with various fusion methods, possibly with a combination of two-pass decoding. Also TTS systems have been used to generate adaptation data for the end-to-end models. In this paper we show that RNN-transducer models can be effectively adapted to new domains using only small amounts of textual data. By taking advantage of model's inherent structure, where the prediction network is interpreted as a language model, we can apply fast adaptation to the model. Adapting the model avoids the need for complicated decoding time fusions and external language models. Using appropriate regularization, the prediction network can be adapted to new domains while still retaining good generalization capabilities. We show with multiple ASR evaluation tasks how this method can provide relative gains of 10-45% in target task WER. We also share insights how RNN-transducer prediction network performs as a language model.
Decomposable Families of Itemsets
Jun 16, 2020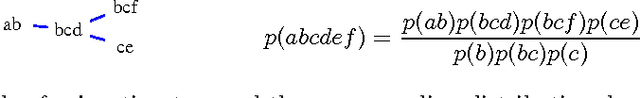


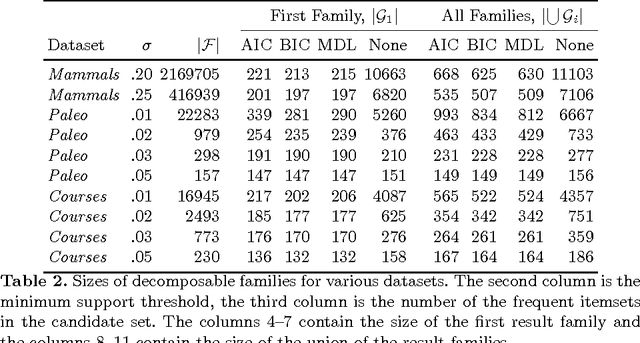
The problem of selecting a small, yet high quality subset of patterns from a larger collection of itemsets has recently attracted lot of research. Here we discuss an approach to this problem using the notion of decomposable families of itemsets. Such itemset families define a probabilistic model for the data from which the original collection of itemsets has been derived from. Furthermore, they induce a special tree structure, called a junction tree, familiar from the theory of Markov Random Fields. The method has several advantages. The junction trees provide an intuitive representation of the mining results. From the computational point of view, the model provides leverage for problems that could be intractable using the entire collection of itemsets. We provide an efficient algorithm to build decomposable itemset families, and give an application example with frequency bound querying using the model. Empirical results show that our algorithm yields high quality results.
A Character-Word Compositional Neural Language Model for Finnish
Dec 10, 2016
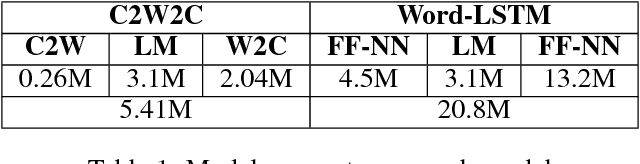


Inspired by recent research, we explore ways to model the highly morphological Finnish language at the level of characters while maintaining the performance of word-level models. We propose a new Character-to-Word-to-Character (C2W2C) compositional language model that uses characters as input and output while still internally processing word level embeddings. Our preliminary experiments, using the Finnish Europarl V7 corpus, indicate that C2W2C can respond well to the challenges of morphologically rich languages such as high out of vocabulary rates, the prediction of novel words, and growing vocabulary size. Notably, the model is able to correctly score inflectional forms that are not present in the training data and sample grammatically and semantically correct Finnish sentences character by character.