 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Text-Only Domain Adaptation of RNN-Transducer Prediction Network
Apr 22, 2021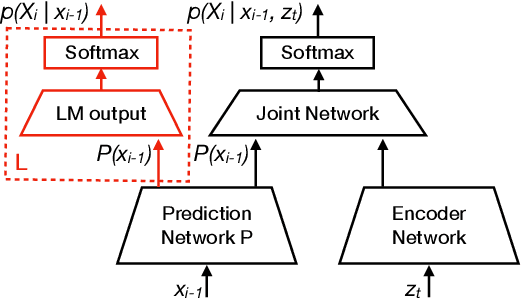

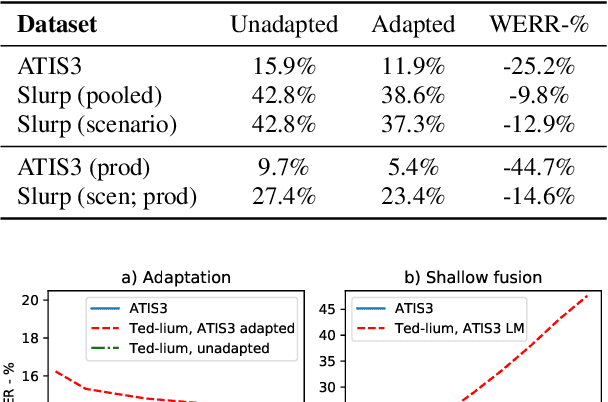
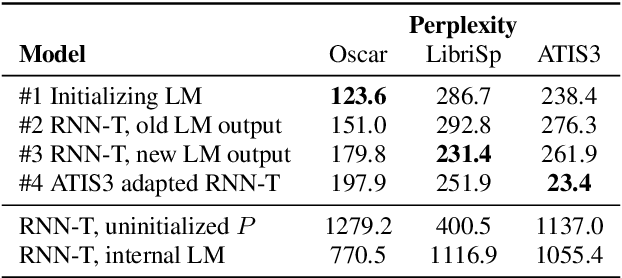
Adaption of end-to-end speech recognition systems to new tasks is known to be challenging. A number of solutions have been proposed which apply external language models with various fusion methods, possibly with a combination of two-pass decoding. Also TTS systems have been used to generate adaptation data for the end-to-end models. In this paper we show that RNN-transducer models can be effectively adapted to new domains using only small amounts of textual data. By taking advantage of model's inherent structure, where the prediction network is interpreted as a language model, we can apply fast adaptation to the model. Adapting the model avoids the need for complicated decoding time fusions and external language models. Using appropriate regularization, the prediction network can be adapted to new domains while still retaining good generalization capabilities. We show with multiple ASR evaluation tasks how this method can provide relative gains of 10-45% in target task WER. We also share insights how RNN-transducer prediction network performs as a language model.
Interpreting Classifiers through Attribute Interactions in Datasets
Jul 24, 2017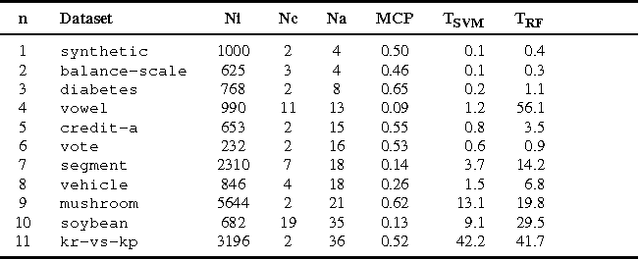
In this work we present the novel ASTRID method for investigating which attribute interactions classifiers exploit when making predictions. Attribute interactions in classification tasks mean that two or more attributes together provide stronger evidence for a particular class label. Knowledge of such interactions makes models more interpretable by revealing associations between attributes. This has applications, e.g., in pharmacovigilance to identify interactions between drugs or in bioinformatics to investigate associations between single nucleotide polymorphisms. We also show how the found attribute partitioning is related to a factorisation of the data generating distribution and empirically demonstrate the utility of the proposed method.
Finding Statistically Significant Attribute Interactions
Mar 16, 2017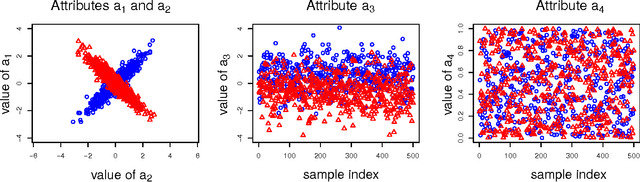
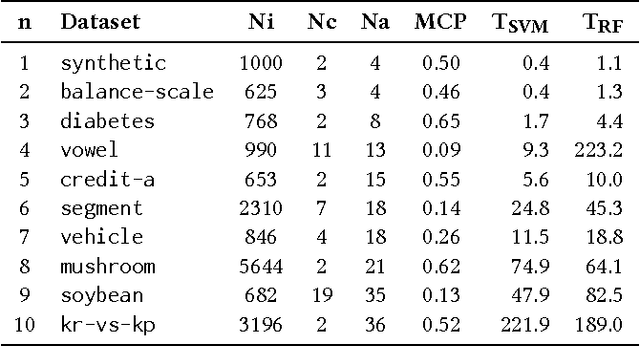
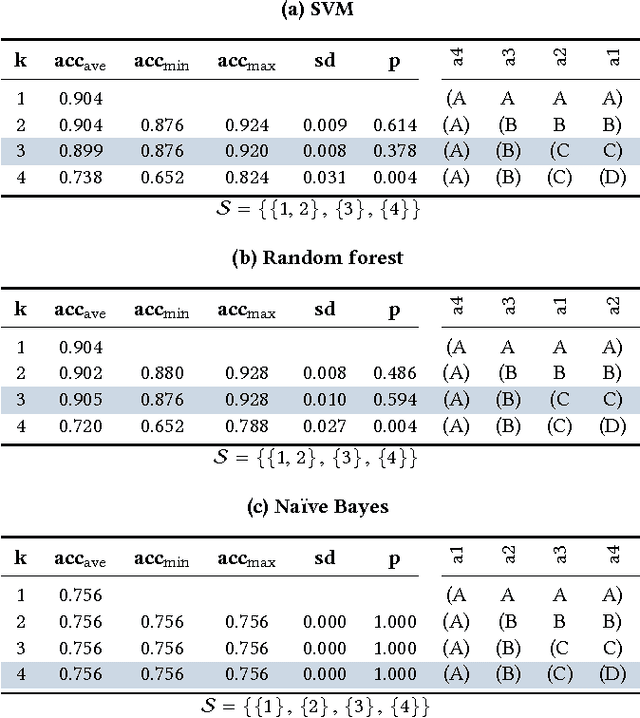
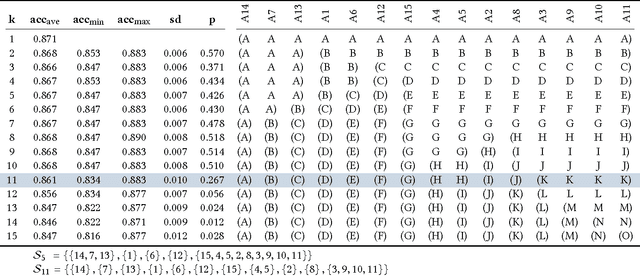
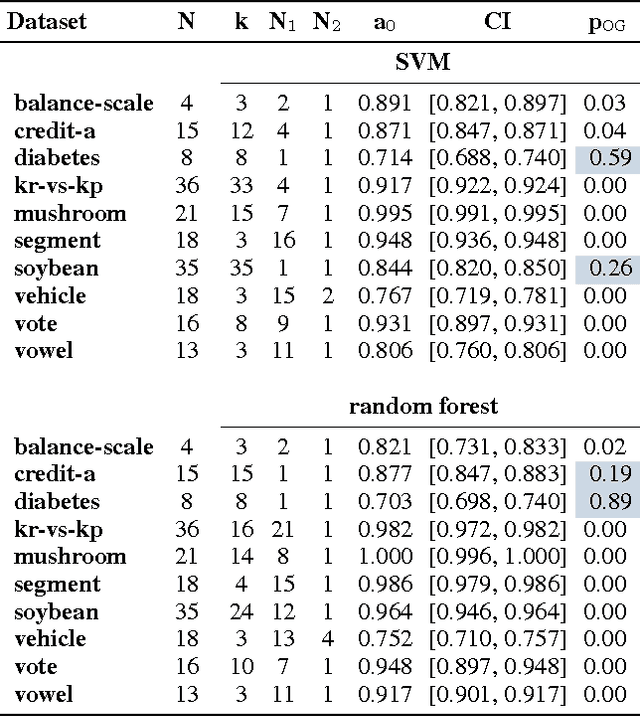
In many data exploration tasks it is meaningful to identify groups of attribute interactions that are specific to a variable of interest. For instance, in a dataset where the attributes are medical markers and the variable of interest (class variable) is binary indicating presence/absence of disease, we would like to know which medical markers interact with respect to the binary class label. These interactions are useful in several practical applications, for example, to gain insight into the structure of the data, in feature selection, and in data anonymisation. We present a novel method, based on statistical significance testing, that can be used to verify if the data set has been created by a given factorised class-conditional joint distribution, where the distribution is parametrised by a partition of its attributes. Furthermore, we provide a method, named ASTRID, for automatically finding a partition of attributes describing the distribution that has generated the data. State-of-the-art classifiers are utilised to capture the interactions present in the data by systematically breaking attribute interactions and observing the effect of this breaking on classifier performance. We empirically demonstrate the utility of the proposed method with examples using real and synthetic data.
Multivariate Confidence Intervals
Jan 20, 2017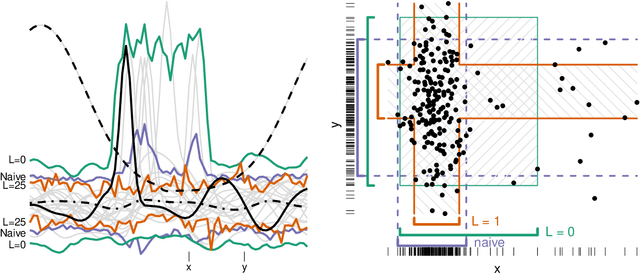
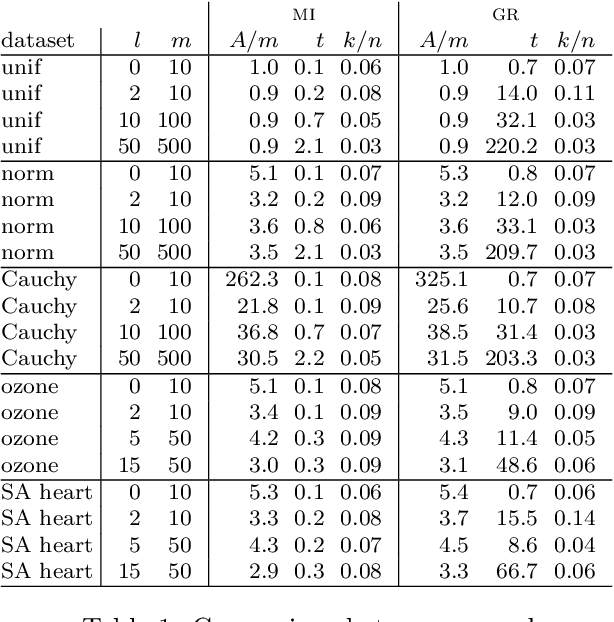
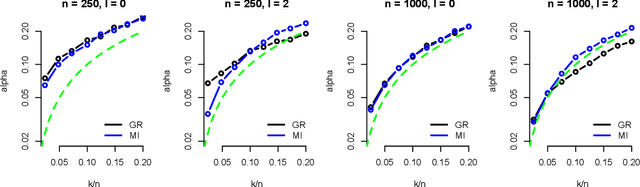
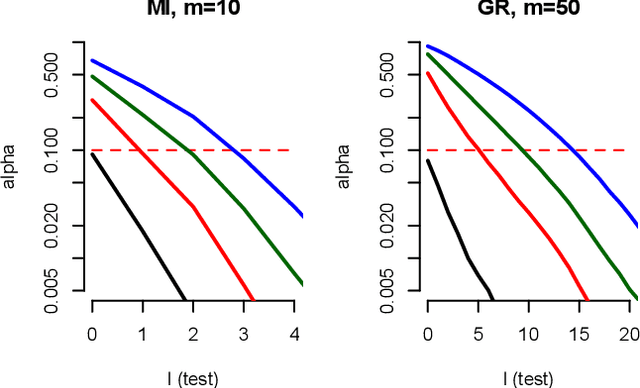
Confidence intervals are a popular way to visualize and analyze data distributions. Unlike p-values, they can convey information both about statistical significance as well as effect size. However, very little work exists on applying confidence intervals to multivariate data. In this paper we define confidence intervals for multivariate data that extend the one-dimensional definition in a natural way. In our definition every variable is associated with its own confidence interval as usual, but a data vector can be outside of a few of these, and still be considered to be within the confidence area. We analyze the problem and show that the resulting confidence areas retain the good qualities of their one-dimensional counterparts: they are informative and easy to interpret. Furthermore, we show that the problem of finding multivariate confidence intervals is hard, but provide efficient approximate algorithms to solve the problem.
Semi-supervised Kernel Metric Learning Using Relative Comparisons
Dec 03, 2016



We consider the problem of metric learning subject to a set of constraints on relative-distance comparisons between the data items. Such constraints are meant to reflect side-information that is not expressed directly in the feature vectors of the data items. The relative-distance constraints used in this work are particularly effective in expressing structures at finer level of detail than must-link (ML) and cannot-link (CL) constraints, which are most commonly used for semi-supervised clustering. Relative-distance constraints are thus useful in settings where providing an ML or a CL constraint is difficult because the granularity of the true clustering is unknown. Our main contribution is an efficient algorithm for learning a kernel matrix using the log determinant divergence --- a variant of the Bregman divergence --- subject to a set of relative-distance constraints. The learned kernel matrix can then be employed by many different kernel methods in a wide range of applications. In our experimental evaluations, we consider a semi-supervised clustering setting and show empirically that kernels found by our algorithm yield clusterings of higher quality than existing approaches that either use ML/CL constraints or a different means to implement the supervision using relative comparisons.
Web search queries can predict stock market volumes
Jun 04, 2012
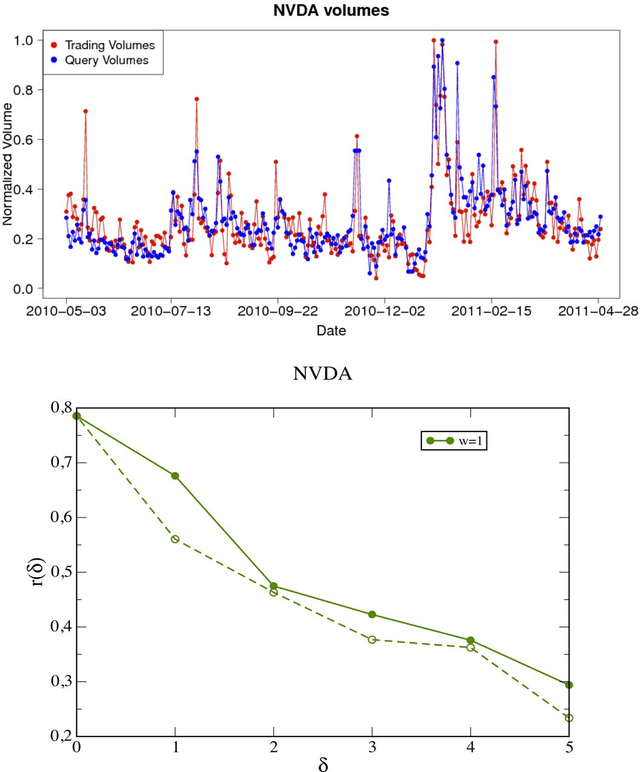

We live in a computerized and networked society where many of our actions leave a digital trace and affect other people's actions. This has lead to the emergence of a new data-driven research field: mathematical methods of computer science, statistical physics and sociometry provide insights on a wide range of disciplines ranging from social science to human mobility. A recent important discovery is that query volumes (i.e., the number of requests submitted by users to search engines on the www) can be used to track and, in some cases, to anticipate the dynamics of social phenomena. Successful exemples include unemployment levels, car and home sales, and epidemics spreading. Few recent works applied this approach to stock prices and market sentiment. However, it remains unclear if trends in financial markets can be anticipated by the collective wisdom of on-line users on the web. Here we show that trading volumes of stocks traded in NASDAQ-100 are correlated with the volumes of queries related to the same stocks. In particular, query volumes anticipate in many cases peaks of trading by one day or more. Our analysis is carried out on a unique dataset of queries, submitted to an important web search engine, which enable us to investigate also the user behavior. We show that the query volume dynamics emerges from the collective but seemingly uncoordinated activity of many users. These findings contribute to the debate on the identification of early warnings of financial systemic risk, based on the activity of users of the www.