 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating regression errors without ground truth values
Oct 09, 2019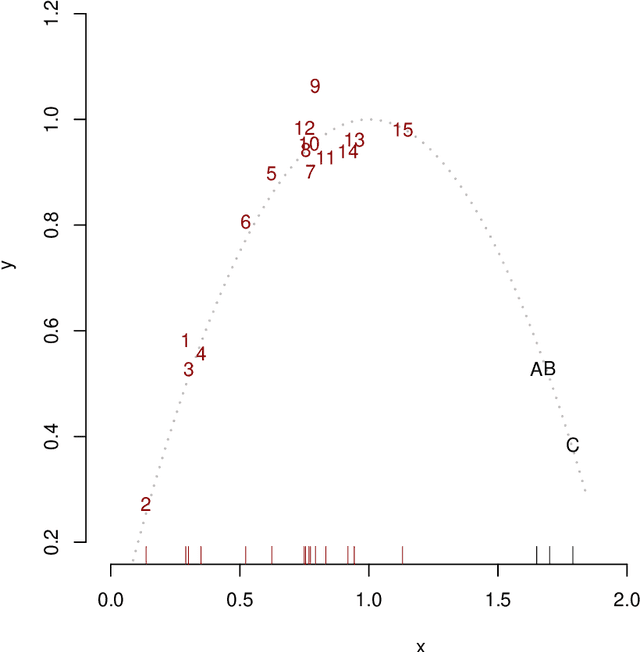
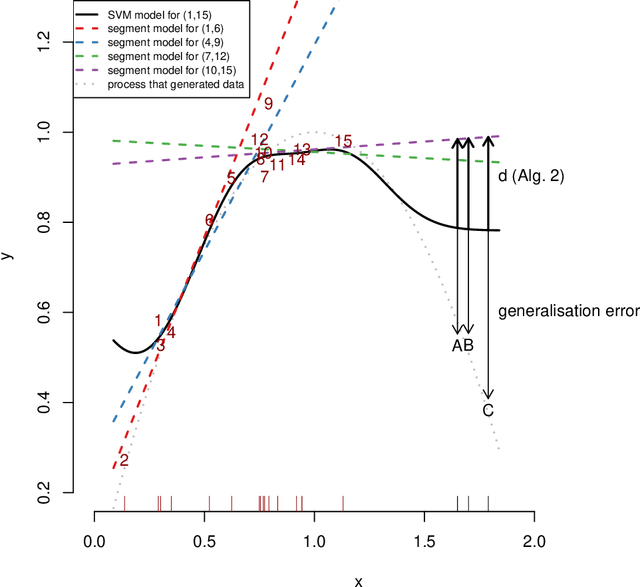
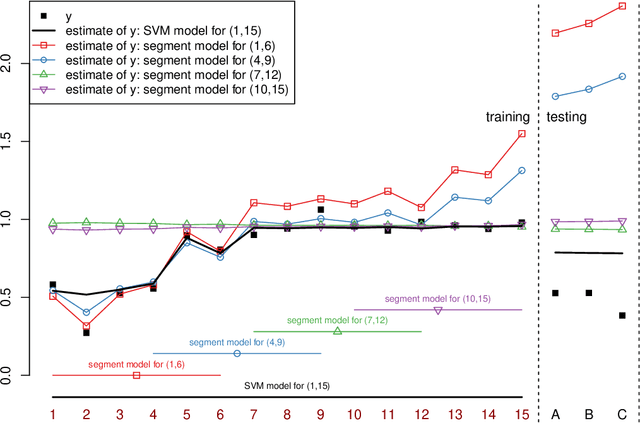
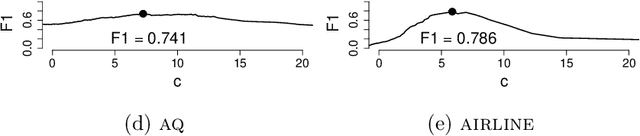
Regression analysis is a standard supervised machine learning method used to model an outcome variable in terms of a set of predictor variables. In most real-world applications we do not know the true value of the outcome variable being predicted outside the training data, i.e., the ground truth is unknown. It is hence not straightforward to directly observe when the estimate from a model potentially is wrong, due to phenomena such as overfitting and concept drift. In this paper we present an efficient framework for estimating the generalization error of regression functions, applicable to any family of regression functions when the ground truth is unknown. We present a theoretical derivation of the framework and empirically evaluate its strengths and limitations. We find that it performs robustly and is useful for detecting concept drift in datasets in several real-world domains.
Guided Visual Exploration of Relations in Data Sets
May 07, 2019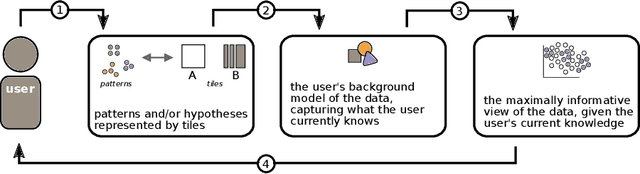

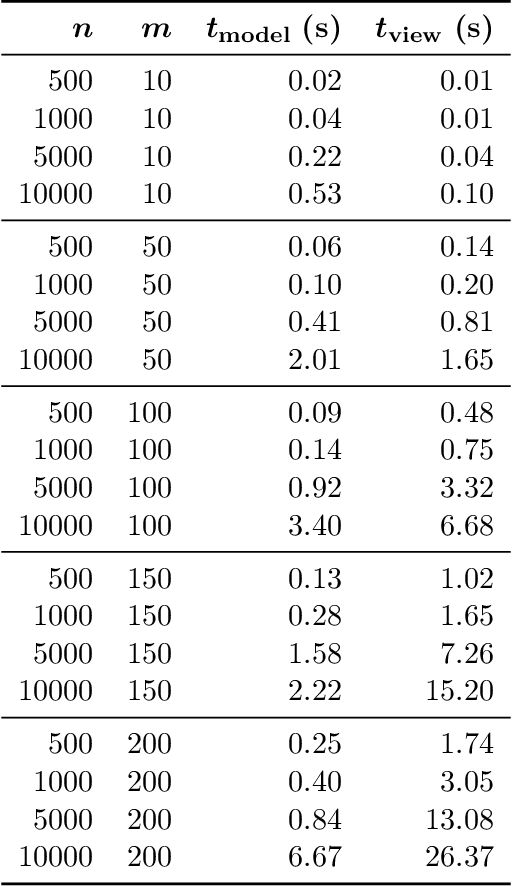
Efficient explorative data analysis systems must take into account both what a user knows and wants to know. This paper proposes a principled framework for interactive visual exploration of relations in data, through views most informative given the user's current knowledge and objectives. The user can input pre-existing knowledge of relations in the data and also formulate specific exploration interests, then taken into account in the exploration. The idea is to steer the exploration process towards the interests of the user, instead of showing uninteresting or already known relations. The user's knowledge is modelled by a distribution over data sets parametrised by subsets of rows and columns of data, called tile constraints. We provide a computationally efficient implementation of this concept based on constrained randomisation. Furthermore, we describe a novel dimensionality reduction method for finding the views most informative to the user, which at the limit of no background knowledge and with generic objectives reduces to PCA. We show that the method is suitable for interactive use and robust to noise, outperforms standard projection pursuit visualisation methods, and gives understandable and useful results in analysis of real-world data. We have released an open-source implementation of the framework.
Human-guided data exploration using randomisation
May 20, 2018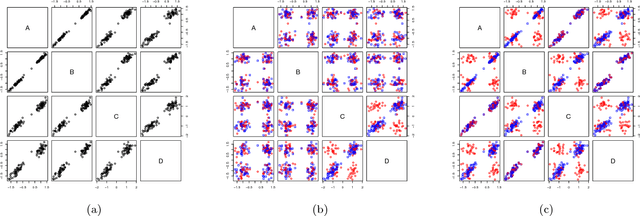

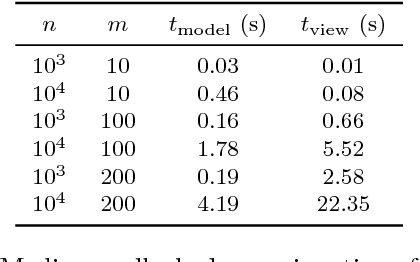
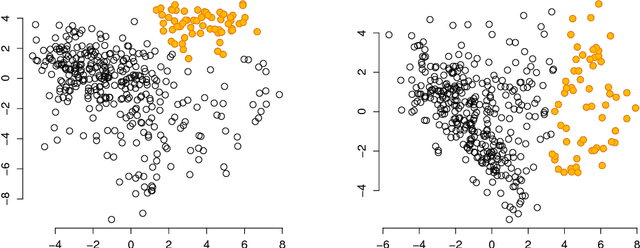
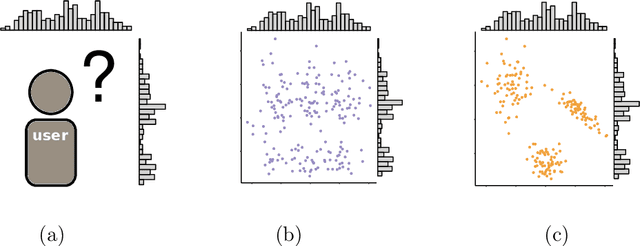
An explorative data analysis system should be aware of what the user already knows and what the user wants to know of the data: otherwise the system cannot provide the user with the most informative and useful views of the data. We propose a principled way to do explorative data analysis, where the user's background knowledge is modeled by a distribution parametrised by subsets of rows and columns in the data, called tiles. The user can also use tiles to describe his or her interests concerning relations in the data. We provide a computationally efficient implementation of this concept based on constrained randomisation. This is used to model both the background knowledge and the user's information request and is a necessary prerequisite for any interactive system. Furthermore, we describe a novel linear projection pursuit method to find and show the views most informative to the user, which at the limit of no background knowledge and with generic objective reduces to PCA. We show that our method is robust under noise and fast enough for interactive use. We also show that the method gives understandable and useful results when analysing real-world data sets. We will release, under an open source license, a software library implementing the idea, including the experiments presented in this paper. We show that our method can outperform standard projection pursuit visualisation methods in exploration tasks. Our framework makes it possible to construct human-guided data exploration systems which are fast, powerful, and give results that are easy to comprehend.
Human-Guided Data Exploration
Apr 09, 2018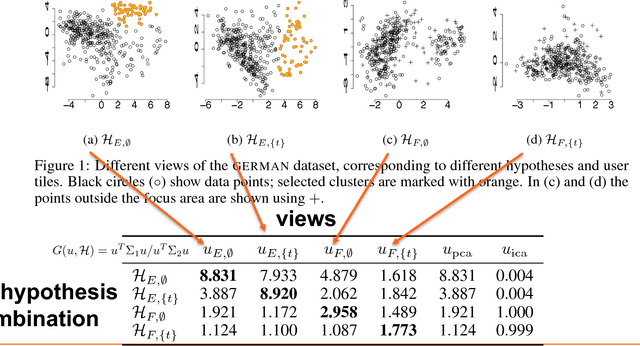
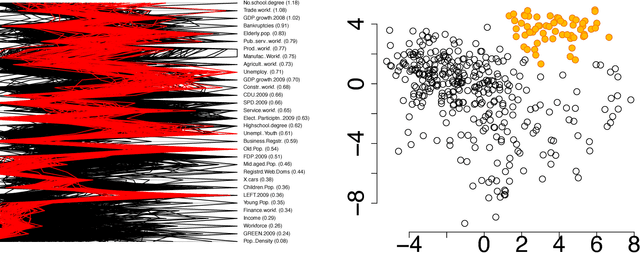
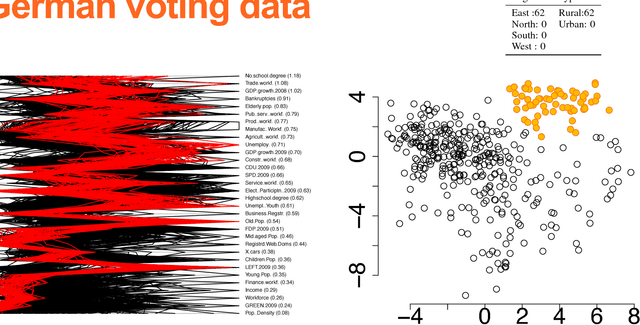
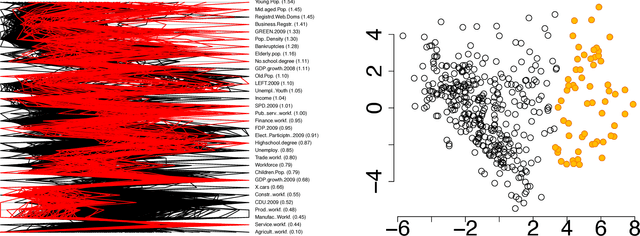
The outcome of the explorative data analysis (EDA) phase is vital for successful data analysis. EDA is more effective when the user interacts with the system used to carry out the exploration. In the recently proposed paradigm of iterative data mining the user controls the exploration by inputting knowledge in the form of patterns observed during the process. The system then shows the user views of the data that are maximally informative given the user's current knowledge. Although this scheme is good at showing surprising views of the data to the user, there is a clear shortcoming: the user cannot steer the process. In many real cases we want to focus on investigating specific questions concerning the data. This paper presents the Human Guided Data Exploration framework, generalising previous research. This framework allows the user to incorporate existing knowledge into the exploration process, focus on exploring a subset of the data, and compare different complex hypotheses concerning relations in the data. The framework utilises a computationally efficient constrained randomisation scheme. To showcase the framework, we developed a free open-source tool, using which the empirical evaluation on real-world datasets was carried out. Our evaluation shows that the ability to focus on particular subsets and being able to compare hypotheses are important additions to the interactive iterative data mining process.
Interactive Visual Data Exploration with Subjective Feedback: An Information-Theoretic Approach
Oct 23, 2017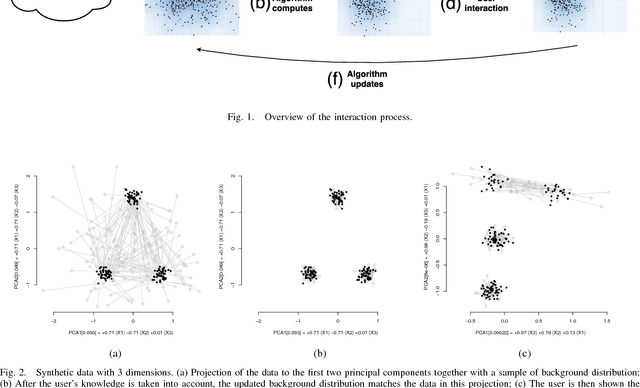
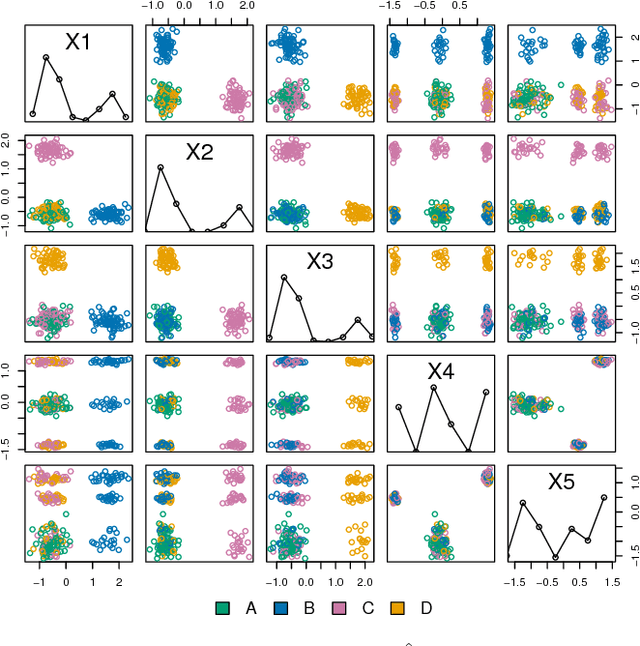
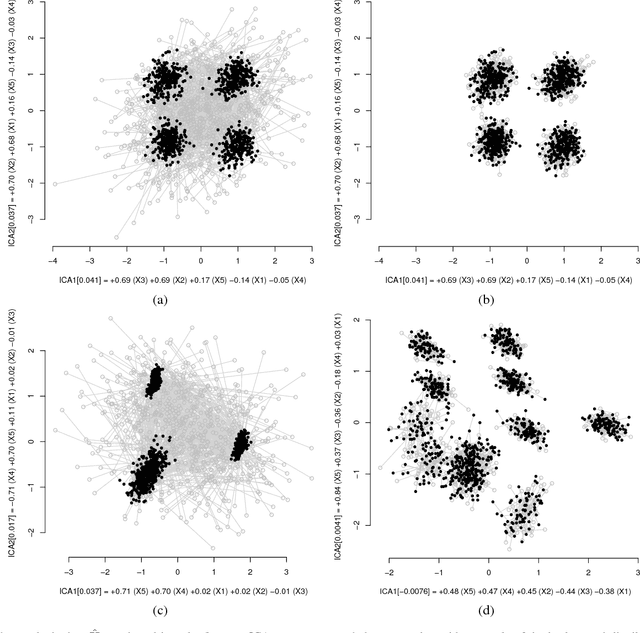
Visual exploration of high-dimensional real-valued datasets is a fundamental task in exploratory data analysis (EDA). Existing methods use predefined criteria to choose the representation of data. There is a lack of methods that (i) elicit from the user what she has learned from the data and (ii) show patterns that she does not know yet. We construct a theoretical model where identified patterns can be input as knowledge to the system. The knowledge syntax here is intuitive, such as "this set of points forms a cluster", and requires no knowledge of maths. This background knowledge is used to find a Maximum Entropy distribution of the data, after which the system provides the user data projections in which the data and the Maximum Entropy distribution differ the most, hence showing the user aspects of the data that are maximally informative given the user's current knowledge. We provide an open source EDA system with tailored interactive visualizations to demonstrate these concepts. We study the performance of the system and present use cases on both synthetic and real data. We find that the model and the prototype system allow the user to learn information efficiently from various data sources and the system works sufficiently fast in practice. We conclude that the information theoretic approach to exploratory data analysis where patterns observed by a user are formalized as constraints provides a principled, intuitive, and efficient basis for constructing an EDA system.
Subjectively Interesting Subgroup Discovery on Real-valued Targets
Oct 12, 2017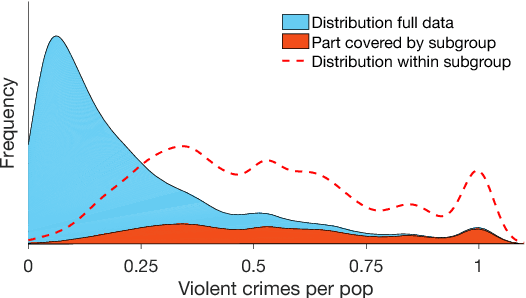
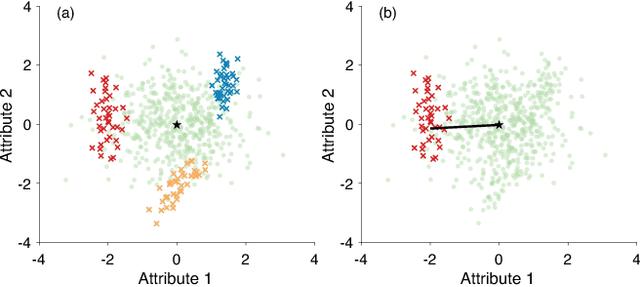
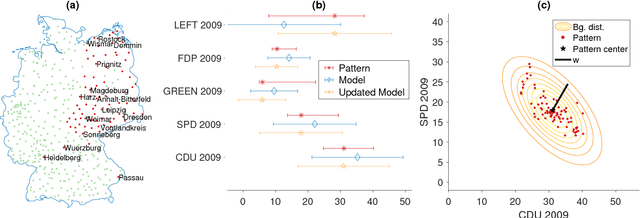
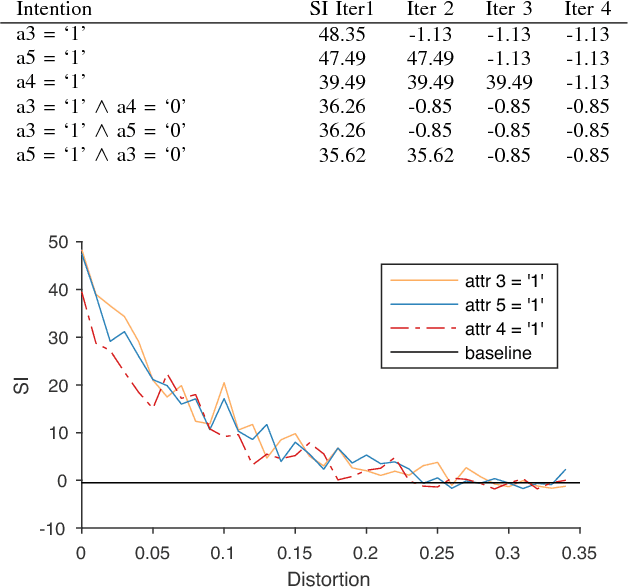
Deriving insights from high-dimensional data is one of the core problems in data mining. The difficulty mainly stems from the fact that there are exponentially many variable combinations to potentially consider, and there are infinitely many if we consider weighted combinations, even for linear combinations. Hence, an obvious question is whether we can automate the search for interesting patterns and visualizations. In this paper, we consider the setting where a user wants to learn as efficiently as possible about real-valued attributes. For example, to understand the distribution of crime rates in different geographic areas in terms of other (numerical, ordinal and/or categorical) variables that describe the areas. We introduce a method to find subgroups in the data that are maximally informative (in the formal Information Theoretic sense) with respect to a single or set of real-valued target attributes. The subgroup descriptions are in terms of a succinct set of arbitrarily-typed other attributes. The approach is based on the Subjective Interestingness framework FORSIED to enable the use of prior knowledge when finding most informative non-redundant patterns, and hence the method also supports iterative data mining.
Multivariate Confidence Intervals
Jan 20, 2017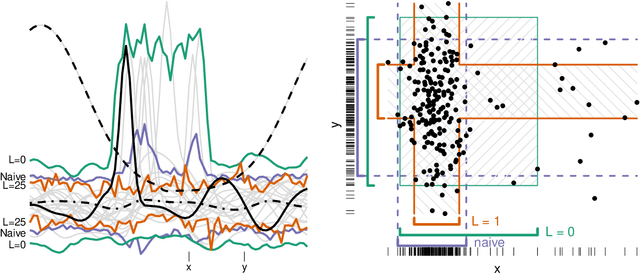
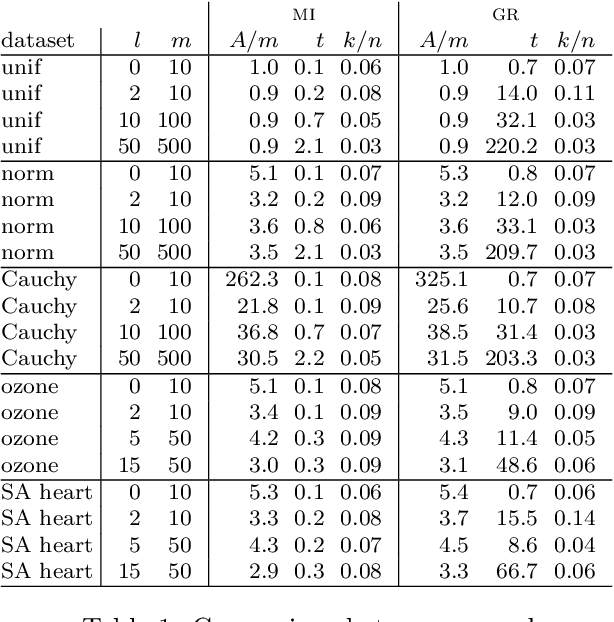
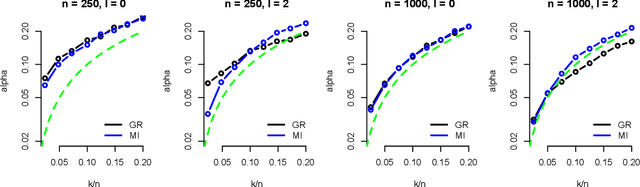
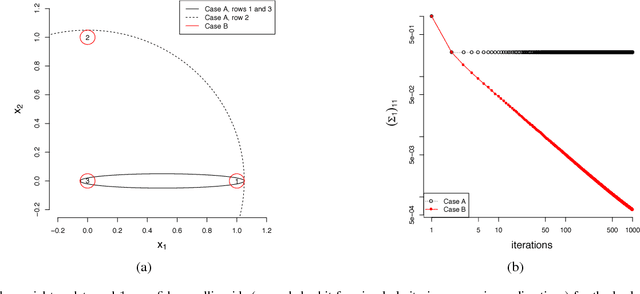
Confidence intervals are a popular way to visualize and analyze data distributions. Unlike p-values, they can convey information both about statistical significance as well as effect size. However, very little work exists on applying confidence intervals to multivariate data. In this paper we define confidence intervals for multivariate data that extend the one-dimensional definition in a natural way. In our definition every variable is associated with its own confidence interval as usual, but a data vector can be outside of a few of these, and still be considered to be within the confidence area. We analyze the problem and show that the resulting confidence areas retain the good qualities of their one-dimensional counterparts: they are informative and easy to interpret. Furthermore, we show that the problem of finding multivariate confidence intervals is hard, but provide efficient approximate algorithms to solve the problem.
Optimizing Phylogenetic Supertrees Using Answer Set Programming
Jul 19, 2015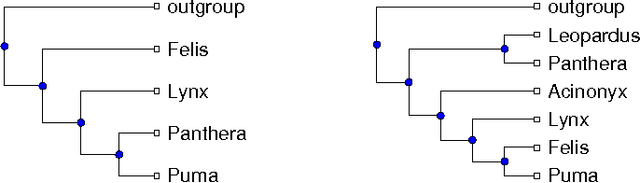
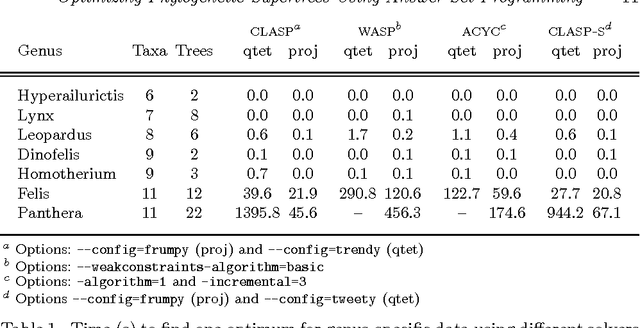
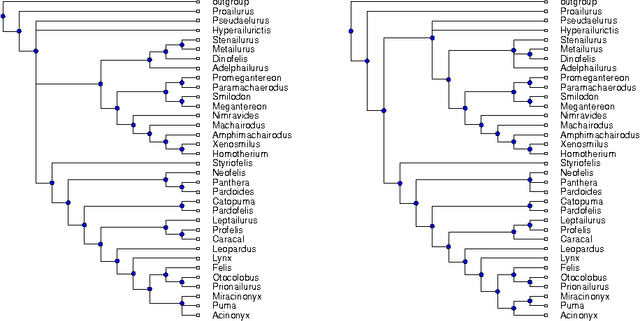
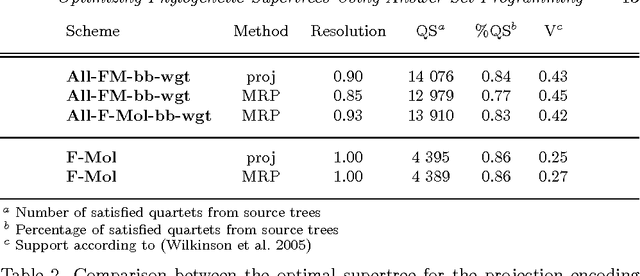
The supertree construction problem is about combining several phylogenetic trees with possibly conflicting information into a single tree that has all the leaves of the source trees as its leaves and the relationships between the leaves are as consistent with the source trees as possible. This leads to an optimization problem that is computationally challenging and typically heuristic methods, such as matrix representation with parsimony (MRP), are used. In this paper we consider the use of answer set programming to solve the supertree construction problem in terms of two alternative encodings. The first is based on an existing encoding of trees using substructures known as quartets, while the other novel encoding captures the relationships present in trees through direct projections. We use these encodings to compute a genus-level supertree for the family of cats (Felidae). Furthermore, we compare our results to recent supertrees obtained by the MRP method.
* To appear in Theory and Practice of Logic Programming (TPLP), Proceedings of ICLP 2015
Modularity Aspects of Disjunctive Stable Models
Jan 15, 2014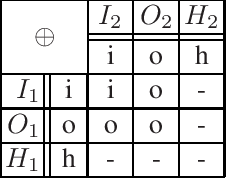
Practically all programming languages allow the programmer to split a program into several modules which brings along several advantages in software development. In this paper, we are interested in the area of answer-set programming where fully declarative and nonmonotonic languages are applied. In this context, obtaining a modular structure for programs is by no means straightforward since the output of an entire program cannot in general be composed from the output of its components. To better understand the effects of disjunctive information on modularity we restrict the scope of analysis to the case of disjunctive logic programs (DLPs) subject to stable-model semantics. We define the notion of a DLP-function, where a well-defined input/output interface is provided, and establish a novel module theorem which indicates the compositionality of stable-model semantics for DLP-functions. The module theorem extends the well-known splitting-set theorem and enables the decomposition of DLP-functions given their strongly connected components based on positive dependencies induced by rules. In this setting, it is also possible to split shared disjunctive rules among components using a generalized shifting technique. The concept of modular equivalence is introduced for the mutual comparison of DLP-functions using a generalization of a translation-based verification method.
Achieving compositionality of the stable model semantics for Smodels programs
Sep 26, 2008In this paper, a Gaifman-Shapiro-style module architecture is tailored to the case of Smodels programs under the stable model semantics. The composition of Smodels program modules is suitably limited by module conditions which ensure the compatibility of the module system with stable models. Hence the semantics of an entire Smodels program depends directly on stable models assigned to its modules. This result is formalized as a module theorem which truly strengthens Lifschitz and Turner's splitting-set theorem for the class of Smodels programs. To streamline generalizations in the future, the module theorem is first proved for normal programs and then extended to cover Smodels programs using a translation from the latter class of programs to the former class. Moreover, the respective notion of module-level equivalence, namely modular equivalence, is shown to be a proper congruence relation: it is preserved under substitutions of modules that are modularly equivalent. Principles for program decomposition are also addressed. The strongly connected components of the respective dependency graph can be exploited in order to extract a module structure when there is no explicit a priori knowledge about the modules of a program. The paper includes a practical demonstration of tools that have been developed for automated (de)composition of Smodels programs. To appear in Theory and Practice of Logic Programming.