 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Approach to Multilabel Stratified Cross Validation with Application to Large and Sparse Gene Ontology Datasets
Sep 03, 2021


Multilabel learning is an important topic in machine learning research. Evaluating models in multilabel settings requires specific cross validation methods designed for multilabel data. In this article, we show a weakness in an evaluation metric widely used in literature and we present improved versions of this metric and a general method, optisplit, for optimising cross validations splits. We present an extensive comparison of various types of cross validation methods in which we show that optisplit produces better cross validation splits than the existing methods and that it is fast enough to be used on big Gene Ontology (GO) datasets
Estimating regression errors without ground truth values
Oct 09, 2019
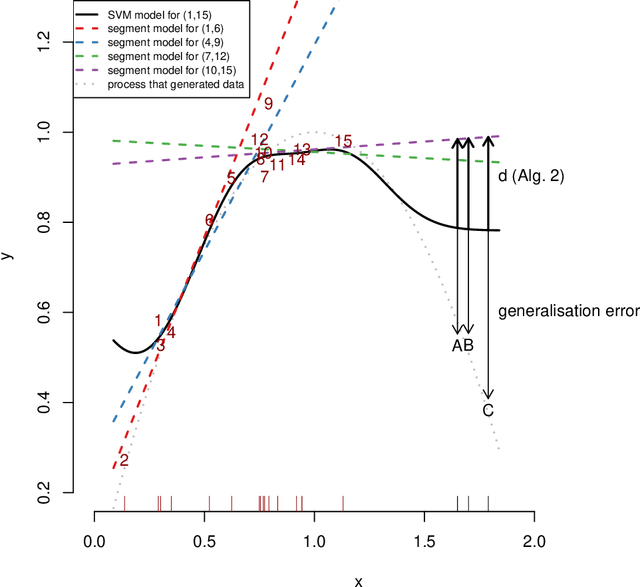
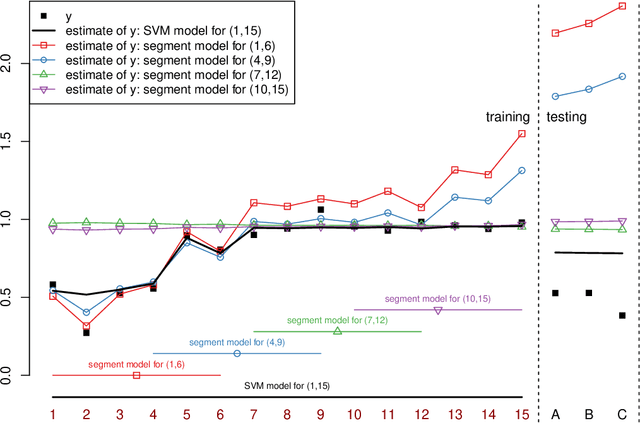
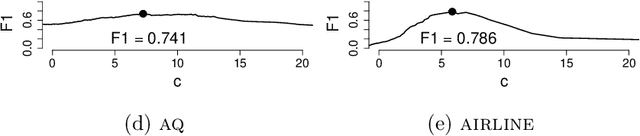
Regression analysis is a standard supervised machine learning method used to model an outcome variable in terms of a set of predictor variables. In most real-world applications we do not know the true value of the outcome variable being predicted outside the training data, i.e., the ground truth is unknown. It is hence not straightforward to directly observe when the estimate from a model potentially is wrong, due to phenomena such as overfitting and concept drift. In this paper we present an efficient framework for estimating the generalization error of regression functions, applicable to any family of regression functions when the ground truth is unknown. We present a theoretical derivation of the framework and empirically evaluate its strengths and limitations. We find that it performs robustly and is useful for detecting concept drift in datasets in several real-world domains.