 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubjectively Interesting Subgroup Discovery on Real-valued Targets
Paper and Code
Oct 12, 2017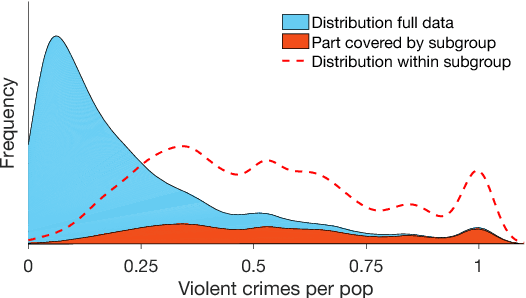
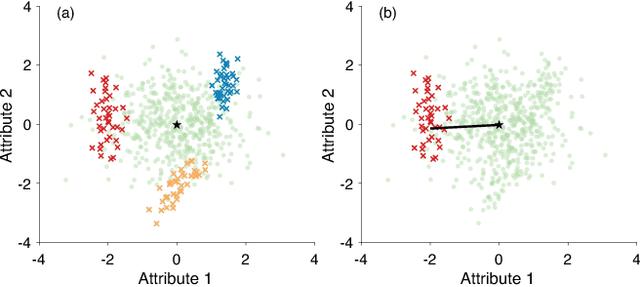
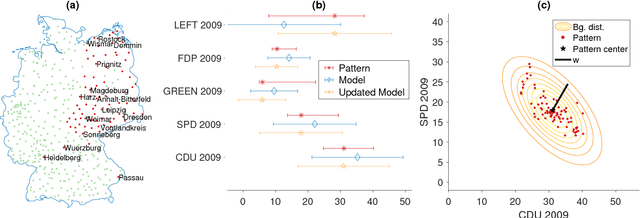
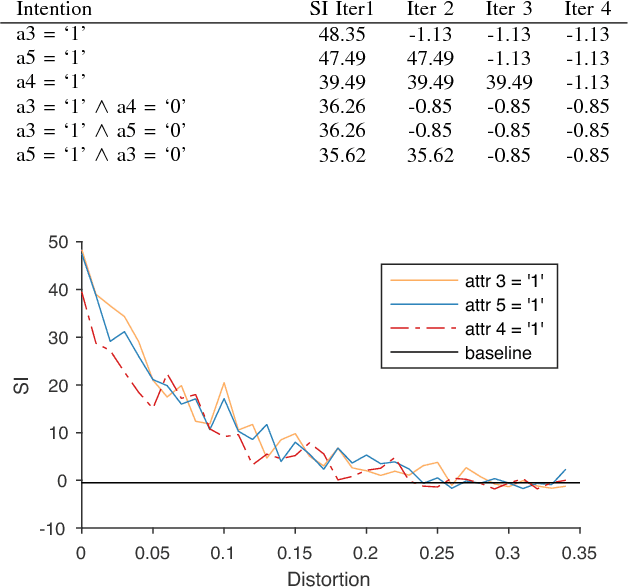
Deriving insights from high-dimensional data is one of the core problems in data mining. The difficulty mainly stems from the fact that there are exponentially many variable combinations to potentially consider, and there are infinitely many if we consider weighted combinations, even for linear combinations. Hence, an obvious question is whether we can automate the search for interesting patterns and visualizations. In this paper, we consider the setting where a user wants to learn as efficiently as possible about real-valued attributes. For example, to understand the distribution of crime rates in different geographic areas in terms of other (numerical, ordinal and/or categorical) variables that describe the areas. We introduce a method to find subgroups in the data that are maximally informative (in the formal Information Theoretic sense) with respect to a single or set of real-valued target attributes. The subgroup descriptions are in terms of a succinct set of arbitrarily-typed other attributes. The approach is based on the Subjective Interestingness framework FORSIED to enable the use of prior knowledge when finding most informative non-redundant patterns, and hence the method also supports iterative data mining.