 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Predicted Links Influence Network Evolution: Disentangling Choice and Algorithmic Feedback in Dynamic Graphs
Mar 04, 2026Link prediction models are increasingly used to recommend interactions in evolving networks, yet their impact on network structure is typically assessed from static snapshots. In particular, observed homophily conflates intrinsic interaction tendencies with amplification effects induced by network dynamics and algorithmic feedback. We propose a temporal framework based on multivariate Hawkes processes that disentangles these two sources and introduce an instantaneous bias measure derived from interaction intensities, capturing current reinforcement dynamics beyond cumulative metrics. We provide a theoretical characterization of the stability and convergence of the induced dynamics, and experiments show that the proposed measure reliably reflects algorithmic feedback effects across different link prediction strategies.
BiMi Sheets: Infosheets for bias mitigation methods
May 28, 2025
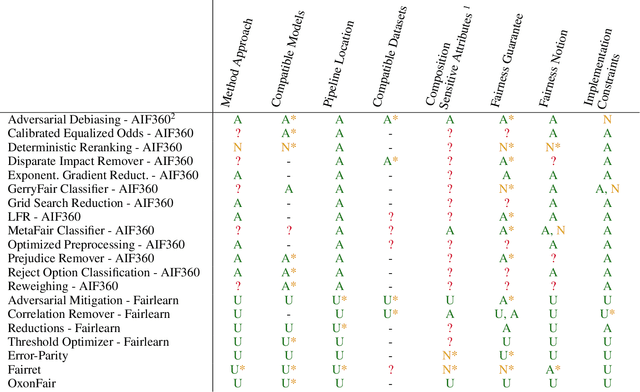
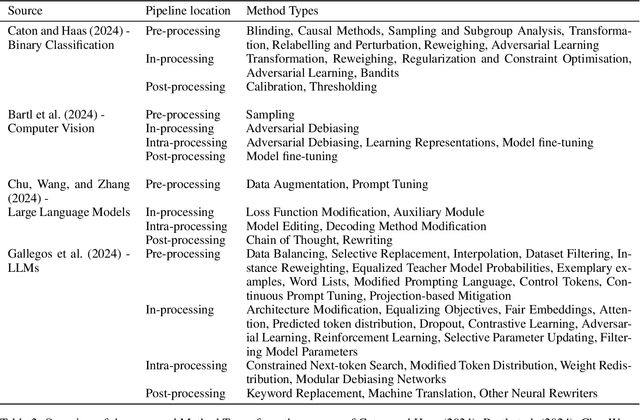

Over the past 15 years, hundreds of bias mitigation methods have been proposed in the pursuit of fairness in machine learning (ML). However, algorithmic biases are domain-, task-, and model-specific, leading to a `portability trap': bias mitigation solutions in one context may not be appropriate in another. Thus, a myriad of design choices have to be made when creating a bias mitigation method, such as the formalization of fairness it pursues, and where and how it intervenes in the ML pipeline. This creates challenges in benchmarking and comparing the relative merits of different bias mitigation methods, and limits their uptake by practitioners. We propose BiMi Sheets as a portable, uniform guide to document the design choices of any bias mitigation method. This enables researchers and practitioners to quickly learn its main characteristics and to compare with their desiderata. Furthermore, the sheets' structure allow for the creation of a structured database of bias mitigation methods. In order to foster the sheets' adoption, we provide a platform for finding and creating BiMi Sheets at bimisheet.com.
InfoClus: Informative Clustering of High-dimensional Data Embeddings
Apr 15, 2025



Developing an understanding of high-dimensional data can be facilitated by visualizing that data using dimensionality reduction. However, the low-dimensional embeddings are often difficult to interpret. To facilitate the exploration and interpretation of low-dimensional embeddings, we introduce a new concept named partitioning with explanations. The idea is to partition the data shown through the embedding into groups, each of which is given a sparse explanation using the original high-dimensional attributes. We introduce an objective function that quantifies how much we can learn through observing the explanations of the data partitioning, using information theory, and also how complex the explanations are. Through parameterization of the complexity, we can tune the solutions towards the desired granularity. We propose InfoClus, which optimizes the partitioning and explanations jointly, through greedy search constrained over a hierarchical clustering. We conduct a qualitative and quantitative analysis of InfoClus on three data sets. We contrast the results on the Cytometry data with published manual analysis results, and compare with two other recent methods for explaining embeddings (RVX and VERA). These comparisons highlight that InfoClus has distinct advantages over existing procedures and methods. We find that InfoClus can automatically create good starting points for the analysis of dimensionality-reduction-based scatter plots.
What Large Language Models Do Not Talk About: An Empirical Study of Moderation and Censorship Practices
Apr 04, 2025Large Language Models (LLMs) are increasingly deployed as gateways to information, yet their content moderation practices remain underexplored. This work investigates the extent to which LLMs refuse to answer or omit information when prompted on political topics. To do so, we distinguish between hard censorship (i.e., generated refusals, error messages, or canned denial responses) and soft censorship (i.e., selective omission or downplaying of key elements), which we identify in LLMs' responses when asked to provide information on a broad range of political figures. Our analysis covers 14 state-of-the-art models from Western countries, China, and Russia, prompted in all six official United Nations (UN) languages. Our analysis suggests that although censorship is observed across the board, it is predominantly tailored to an LLM provider's domestic audience and typically manifests as either hard censorship or soft censorship (though rarely both concurrently). These findings underscore the need for ideological and geographic diversity among publicly available LLMs, and greater transparency in LLM moderation strategies to facilitate informed user choices. All data are made freely available.
Large Language Models Reflect the Ideology of their Creators
Oct 24, 2024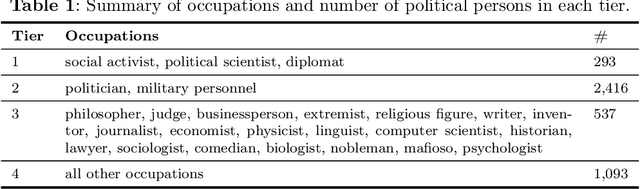

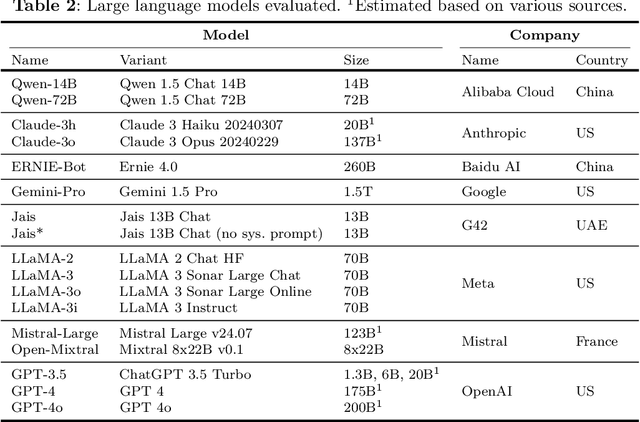
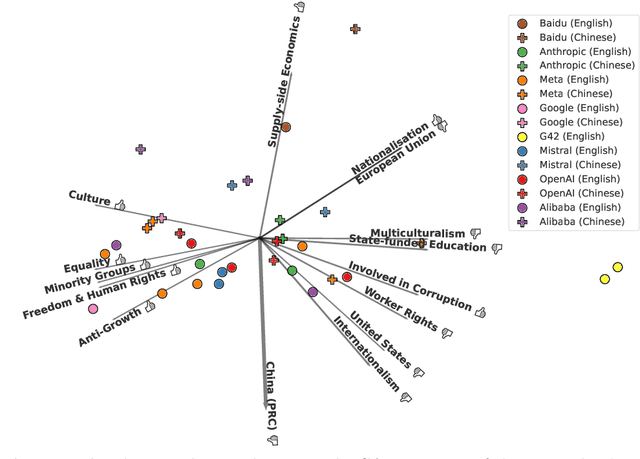
Large language models (LLMs) are trained on vast amounts of data to generate natural language, enabling them to perform tasks like text summarization and question answering. These models have become popular in artificial intelligence (AI) assistants like ChatGPT and already play an influential role in how humans access information. However, the behavior of LLMs varies depending on their design, training, and use. In this paper, we uncover notable diversity in the ideological stance exhibited across different LLMs and languages in which they are accessed. We do this by prompting a diverse panel of popular LLMs to describe a large number of prominent and controversial personalities from recent world history, both in English and in Chinese. By identifying and analyzing moral assessments reflected in the generated descriptions, we find consistent normative differences between how the same LLM responds in Chinese compared to English. Similarly, we identify normative disagreements between Western and non-Western LLMs about prominent actors in geopolitical conflicts. Furthermore, popularly hypothesized disparities in political goals among Western models are reflected in significant normative differences related to inclusion, social inequality, and political scandals. Our results show that the ideological stance of an LLM often reflects the worldview of its creators. This raises important concerns around technological and regulatory efforts with the stated aim of making LLMs ideologically `unbiased', and it poses risks for political instrumentalization.
Pattern or Artifact? Interactively Exploring Embedding Quality with TRACE
Jun 18, 2024This paper presents TRACE, a tool to analyze the quality of 2D embeddings generated through dimensionality reduction techniques. Dimensionality reduction methods often prioritize preserving either local neighborhoods or global distances, but insights from visual structures can be misleading if the objective has not been achieved uniformly. TRACE addresses this challenge by providing a scalable and extensible pipeline for computing both local and global quality measures. The interactive browser-based interface allows users to explore various embeddings while visually assessing the pointwise embedding quality. The interface also facilitates in-depth analysis by highlighting high-dimensional nearest neighbors for any group of points and displaying high-dimensional distances between points. TRACE enables analysts to make informed decisions regarding the most suitable dimensionality reduction method for their specific use case, by showing the degree and location where structure is preserved in the reduced space.
Exploring the Performance of Continuous-Time Dynamic Link Prediction Algorithms
May 27, 2024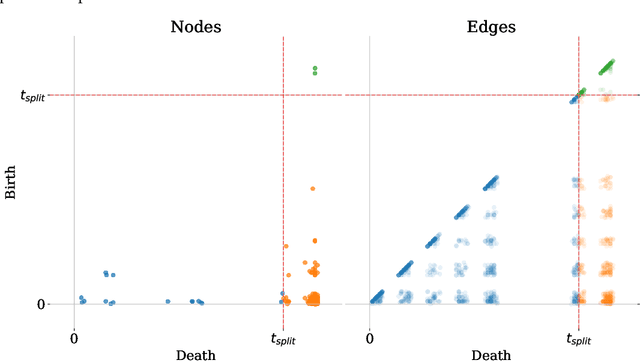



Dynamic Link Prediction (DLP) addresses the prediction of future links in evolving networks. However, accurately portraying the performance of DLP algorithms poses challenges that might impede progress in the field. Importantly, common evaluation pipelines usually calculate ranking or binary classification metrics, where the scores of observed interactions (positives) are compared with those of randomly generated ones (negatives). However, a single metric is not sufficient to fully capture the differences between DLP algorithms, and is prone to overly optimistic performance evaluation. Instead, an in-depth evaluation should reflect performance variations across different nodes, edges, and time segments. In this work, we contribute tools to perform such a comprehensive evaluation. (1) We propose Birth-Death diagrams, a simple but powerful visualization technique that illustrates the effect of time-based train-test splitting on the difficulty of DLP on a given dataset. (2) We describe an exhaustive taxonomy of negative sampling methods that can be used at evaluation time. (3) We carry out an empirical study of the effect of the different negative sampling strategies. Our comparison between heuristics and state-of-the-art memory-based methods on various real-world datasets confirms a strong effect of using different negative sampling strategies on the test Area Under the Curve (AUC). Moreover, we conduct a visual exploration of the prediction, with additional insights on which different types of errors are prominent over time.
Gaussian Embedding of Temporal Networks
May 27, 2024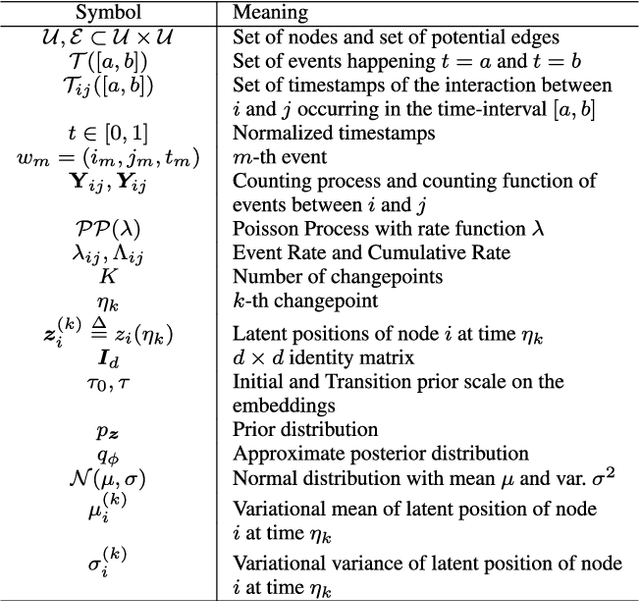


Representing the nodes of continuous-time temporal graphs in a low-dimensional latent space has wide-ranging applications, from prediction to visualization. Yet, analyzing continuous-time relational data with timestamped interactions introduces unique challenges due to its sparsity. Merely embedding nodes as trajectories in the latent space overlooks this sparsity, emphasizing the need to quantify uncertainty around the latent positions. In this paper, we propose TGNE (\textbf{T}emporal \textbf{G}aussian \textbf{N}etwork \textbf{E}mbedding), an innovative method that bridges two distinct strands of literature: the statistical analysis of networks via Latent Space Models (LSM)\cite{Hoff2002} and temporal graph machine learning. TGNE embeds nodes as piece-wise linear trajectories of Gaussian distributions in the latent space, capturing both structural information and uncertainty around the trajectories. We evaluate TGNE's effectiveness in reconstructing the original graph and modelling uncertainty. The results demonstrate that TGNE generates competitive time-varying embedding locations compared to common baselines for reconstructing unobserved edge interactions based on observed edges. Furthermore, the uncertainty estimates align with the time-varying degree distribution in the network, providing valuable insights into the temporal dynamics of the graph. To facilitate reproducibility, we provide an open-source implementation of TGNE at \url{https://github.com/aida-ugent/tgne}.
New Perspectives on the Evaluation of Link Prediction Algorithms for Dynamic Graphs
Nov 30, 2023



There is a fast-growing body of research on predicting future links in dynamic networks, with many new algorithms. Some benchmark data exists, and performance evaluations commonly rely on comparing the scores of observed network events (positives) with those of randomly generated ones (negatives). These evaluation measures depend on both the predictive ability of the model and, crucially, the type of negative samples used. Besides, as generally the case with temporal data, prediction quality may vary over time. This creates a complex evaluation space. In this work, we catalog the possibilities for negative sampling and introduce novel visualization methods that can yield insight into prediction performance and the dynamics of temporal networks. We leverage these visualization tools to investigate the effect of negative sampling on the predictive performance, at the node and edge level. We validate empirically, on datasets extracted from recent benchmarks that the error is typically not evenly distributed across different data segments. Finally, we argue that such visualization tools can serve as powerful guides to evaluate dynamic link prediction methods at different levels.
FEIR: Quantifying and Reducing Envy and Inferiority for Fair Recommendation of Limited Resources
Nov 08, 2023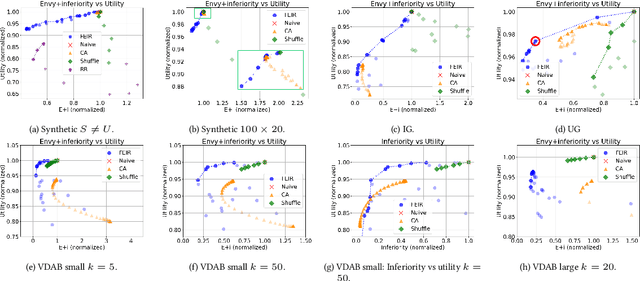
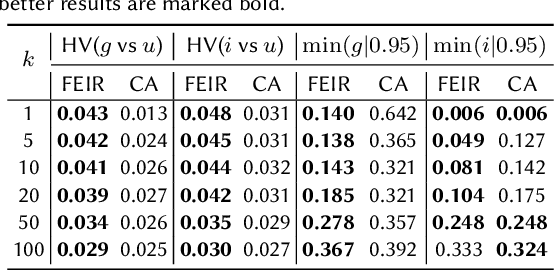
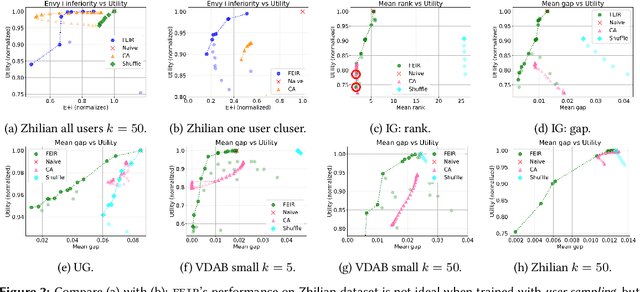
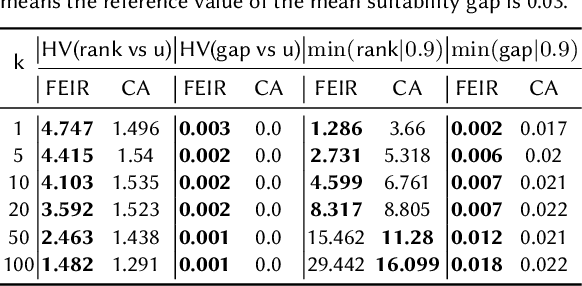
In settings such as e-recruitment and online dating, recommendation involves distributing limited opportunities, calling for novel approaches to quantify and enforce fairness. We introduce \emph{inferiority}, a novel (un)fairness measure quantifying a user's competitive disadvantage for their recommended items. Inferiority complements \emph{envy}, a fairness notion measuring preference for others' recommendations. We combine inferiority and envy with \emph{utility}, an accuracy-related measure of aggregated relevancy scores. Since these measures are non-differentiable, we reformulate them using a probabilistic interpretation of recommender systems, yielding differentiable versions. We combine these loss functions in a multi-objective optimization problem called \texttt{FEIR} (Fairness through Envy and Inferiority Reduction), applied as post-processing for standard recommender systems. Experiments on synthetic and real-world data demonstrate that our approach improves trade-offs between inferiority, envy, and utility compared to naive recommendations and the baseline methods.