 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Performance of Continuous-Time Dynamic Link Prediction Algorithms
Paper and Code
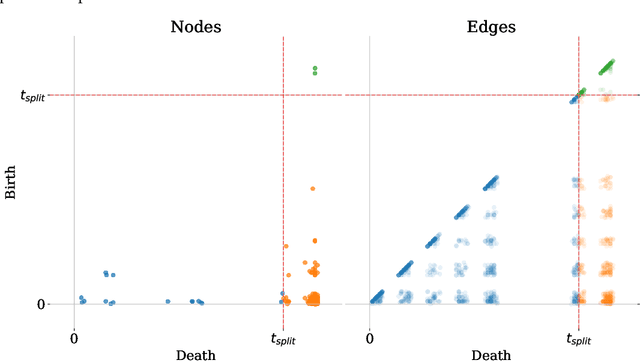



Dynamic Link Prediction (DLP) addresses the prediction of future links in evolving networks. However, accurately portraying the performance of DLP algorithms poses challenges that might impede progress in the field. Importantly, common evaluation pipelines usually calculate ranking or binary classification metrics, where the scores of observed interactions (positives) are compared with those of randomly generated ones (negatives). However, a single metric is not sufficient to fully capture the differences between DLP algorithms, and is prone to overly optimistic performance evaluation. Instead, an in-depth evaluation should reflect performance variations across different nodes, edges, and time segments. In this work, we contribute tools to perform such a comprehensive evaluation. (1) We propose Birth-Death diagrams, a simple but powerful visualization technique that illustrates the effect of time-based train-test splitting on the difficulty of DLP on a given dataset. (2) We describe an exhaustive taxonomy of negative sampling methods that can be used at evaluation time. (3) We carry out an empirical study of the effect of the different negative sampling strategies. Our comparison between heuristics and state-of-the-art memory-based methods on various real-world datasets confirms a strong effect of using different negative sampling strategies on the test Area Under the Curve (AUC). Moreover, we conduct a visual exploration of the prediction, with additional insights on which different types of errors are prominent over time.