 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinistral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
ProbLog4Fairness: A Neurosymbolic Approach to Modeling and Mitigating Bias
Nov 12, 2025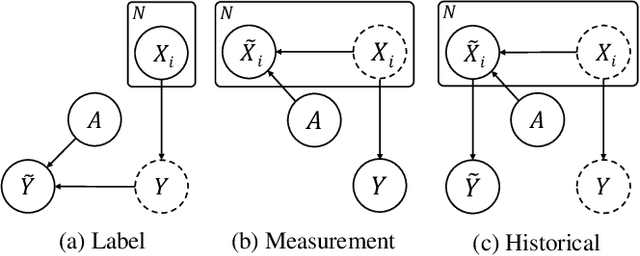

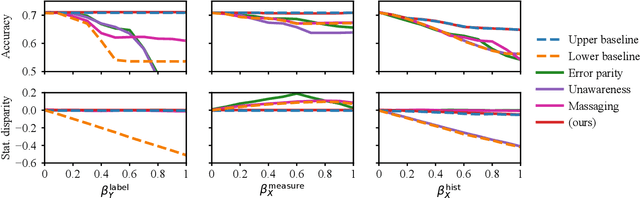

Operationalizing definitions of fairness is difficult in practice, as multiple definitions can be incompatible while each being arguably desirable. Instead, it may be easier to directly describe algorithmic bias through ad-hoc assumptions specific to a particular real-world task, e.g., based on background information on systemic biases in its context. Such assumptions can, in turn, be used to mitigate this bias during training. Yet, a framework for incorporating such assumptions that is simultaneously principled, flexible, and interpretable is currently lacking. Our approach is to formalize bias assumptions as programs in ProbLog, a probabilistic logic programming language that allows for the description of probabilistic causal relationships through logic. Neurosymbolic extensions of ProbLog then allow for easy integration of these assumptions in a neural network's training process. We propose a set of templates to express different types of bias and show the versatility of our approach on synthetic tabular datasets with known biases. Using estimates of the bias distortions present, we also succeed in mitigating algorithmic bias in real-world tabular and image data. We conclude that ProbLog4Fairness outperforms baselines due to its ability to flexibly model the relevant bias assumptions, where other methods typically uphold a fixed bias type or notion of fairness.
BiMi Sheets: Infosheets for bias mitigation methods
May 28, 2025
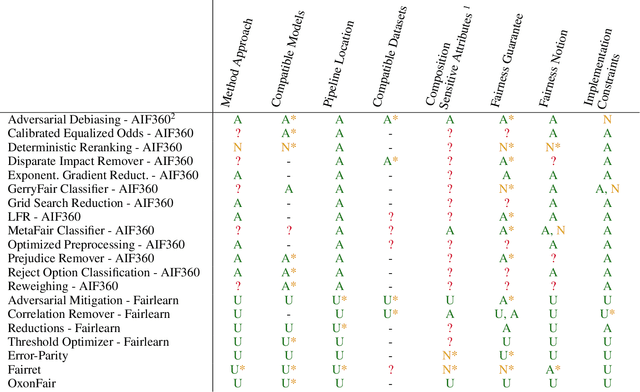
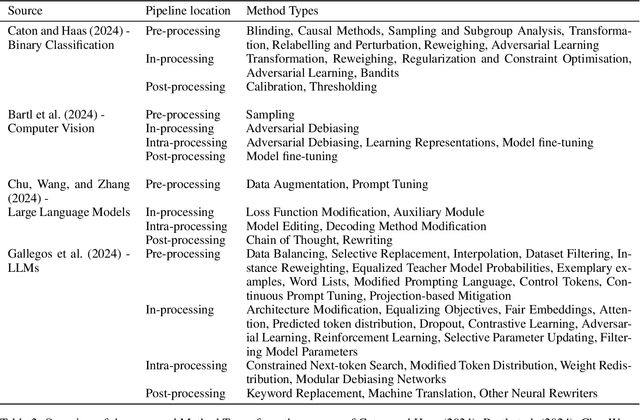

Over the past 15 years, hundreds of bias mitigation methods have been proposed in the pursuit of fairness in machine learning (ML). However, algorithmic biases are domain-, task-, and model-specific, leading to a `portability trap': bias mitigation solutions in one context may not be appropriate in another. Thus, a myriad of design choices have to be made when creating a bias mitigation method, such as the formalization of fairness it pursues, and where and how it intervenes in the ML pipeline. This creates challenges in benchmarking and comparing the relative merits of different bias mitigation methods, and limits their uptake by practitioners. We propose BiMi Sheets as a portable, uniform guide to document the design choices of any bias mitigation method. This enables researchers and practitioners to quickly learn its main characteristics and to compare with their desiderata. Furthermore, the sheets' structure allow for the creation of a structured database of bias mitigation methods. In order to foster the sheets' adoption, we provide a platform for finding and creating BiMi Sheets at bimisheet.com.
What Large Language Models Do Not Talk About: An Empirical Study of Moderation and Censorship Practices
Apr 04, 2025Large Language Models (LLMs) are increasingly deployed as gateways to information, yet their content moderation practices remain underexplored. This work investigates the extent to which LLMs refuse to answer or omit information when prompted on political topics. To do so, we distinguish between hard censorship (i.e., generated refusals, error messages, or canned denial responses) and soft censorship (i.e., selective omission or downplaying of key elements), which we identify in LLMs' responses when asked to provide information on a broad range of political figures. Our analysis covers 14 state-of-the-art models from Western countries, China, and Russia, prompted in all six official United Nations (UN) languages. Our analysis suggests that although censorship is observed across the board, it is predominantly tailored to an LLM provider's domestic audience and typically manifests as either hard censorship or soft censorship (though rarely both concurrently). These findings underscore the need for ideological and geographic diversity among publicly available LLMs, and greater transparency in LLM moderation strategies to facilitate informed user choices. All data are made freely available.
Biased Heritage: How Datasets Shape Models in Facial Expression Recognition
Mar 05, 2025In recent years, the rapid development of artificial intelligence (AI) systems has raised concerns about our ability to ensure their fairness, that is, how to avoid discrimination based on protected characteristics such as gender, race, or age. While algorithmic fairness is well-studied in simple binary classification tasks on tabular data, its application to complex, real-world scenarios-such as Facial Expression Recognition (FER)-remains underexplored. FER presents unique challenges: it is inherently multiclass, and biases emerge across intersecting demographic variables, each potentially comprising multiple protected groups. We present a comprehensive framework to analyze bias propagation from datasets to trained models in image-based FER systems, while introducing new bias metrics specifically designed for multiclass problems with multiple demographic groups. Our methodology studies bias propagation by (1) inducing controlled biases in FER datasets, (2) training models on these biased datasets, and (3) analyzing the correlation between dataset bias metrics and model fairness notions. Our findings reveal that stereotypical biases propagate more strongly to model predictions than representational biases, suggesting that preventing emotion-specific demographic patterns should be prioritized over general demographic balance in FER datasets. Additionally, we observe that biased datasets lead to reduced model accuracy, challenging the assumed fairness-accuracy trade-off.
Persuasion with Large Language Models: a Survey
Nov 11, 2024The rapid rise of Large Language Models (LLMs) has created new disruptive possibilities for persuasive communication, by enabling fully-automated personalized and interactive content generation at an unprecedented scale. In this paper, we survey the research field of LLM-based persuasion that has emerged as a result. We begin by exploring the different modes in which LLM Systems are used to influence human attitudes and behaviors. In areas such as politics, marketing, public health, e-commerce, and charitable giving, such LLM Systems have already achieved human-level or even super-human persuasiveness. We identify key factors influencing their effectiveness, such as the manner of personalization and whether the content is labelled as AI-generated. We also summarize the experimental designs that have been used to evaluate progress. Our survey suggests that the current and future potential of LLM-based persuasion poses profound ethical and societal risks, including the spread of misinformation, the magnification of biases, and the invasion of privacy. These risks underscore the urgent need for ethical guidelines and updated regulatory frameworks to avoid the widespread deployment of irresponsible and harmful LLM Systems.
Large Language Models Reflect the Ideology of their Creators
Oct 24, 2024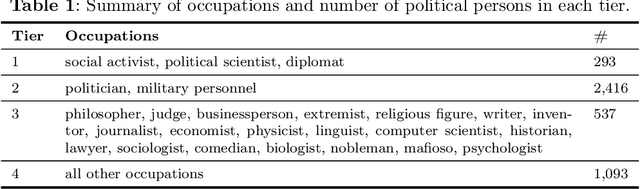

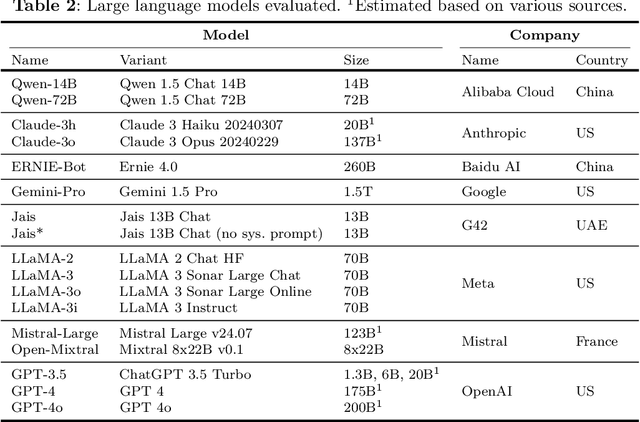
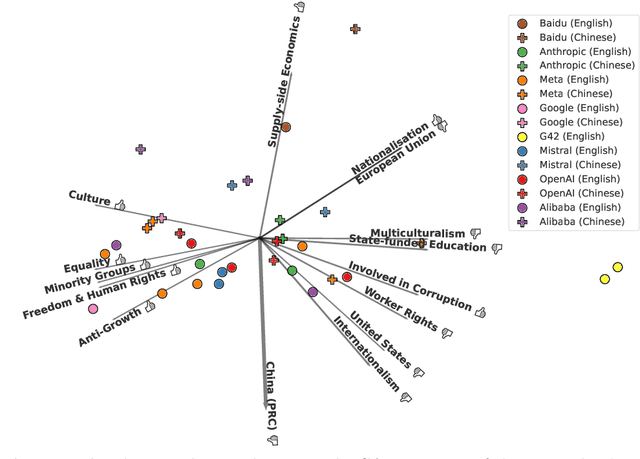
Large language models (LLMs) are trained on vast amounts of data to generate natural language, enabling them to perform tasks like text summarization and question answering. These models have become popular in artificial intelligence (AI) assistants like ChatGPT and already play an influential role in how humans access information. However, the behavior of LLMs varies depending on their design, training, and use. In this paper, we uncover notable diversity in the ideological stance exhibited across different LLMs and languages in which they are accessed. We do this by prompting a diverse panel of popular LLMs to describe a large number of prominent and controversial personalities from recent world history, both in English and in Chinese. By identifying and analyzing moral assessments reflected in the generated descriptions, we find consistent normative differences between how the same LLM responds in Chinese compared to English. Similarly, we identify normative disagreements between Western and non-Western LLMs about prominent actors in geopolitical conflicts. Furthermore, popularly hypothesized disparities in political goals among Western models are reflected in significant normative differences related to inclusion, social inequality, and political scandals. Our results show that the ideological stance of an LLM often reflects the worldview of its creators. This raises important concerns around technological and regulatory efforts with the stated aim of making LLMs ideologically `unbiased', and it poses risks for political instrumentalization.
ABCFair: an Adaptable Benchmark approach for Comparing Fairness Methods
Sep 25, 2024
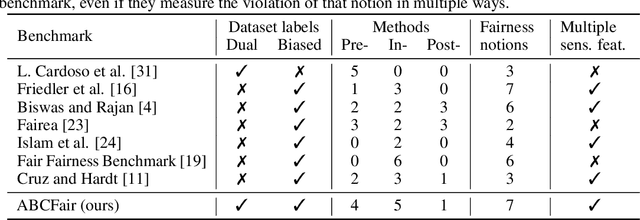


Numerous methods have been implemented that pursue fairness with respect to sensitive features by mitigating biases in machine learning. Yet, the problem settings that each method tackles vary significantly, including the stage of intervention, the composition of sensitive features, the fairness notion, and the distribution of the output. Even in binary classification, these subtle differences make it highly complicated to benchmark fairness methods, as their performance can strongly depend on exactly how the bias mitigation problem was originally framed. Hence, we introduce ABCFair, a benchmark approach which allows adapting to the desiderata of the real-world problem setting, enabling proper comparability between methods for any use case. We apply ABCFair to a range of pre-, in-, and postprocessing methods on both large-scale, traditional datasets and on a dual label (biased and unbiased) dataset to sidestep the fairness-accuracy trade-off.
Exploring the Performance of Continuous-Time Dynamic Link Prediction Algorithms
May 27, 2024Dynamic Link Prediction (DLP) addresses the prediction of future links in evolving networks. However, accurately portraying the performance of DLP algorithms poses challenges that might impede progress in the field. Importantly, common evaluation pipelines usually calculate ranking or binary classification metrics, where the scores of observed interactions (positives) are compared with those of randomly generated ones (negatives). However, a single metric is not sufficient to fully capture the differences between DLP algorithms, and is prone to overly optimistic performance evaluation. Instead, an in-depth evaluation should reflect performance variations across different nodes, edges, and time segments. In this work, we contribute tools to perform such a comprehensive evaluation. (1) We propose Birth-Death diagrams, a simple but powerful visualization technique that illustrates the effect of time-based train-test splitting on the difficulty of DLP on a given dataset. (2) We describe an exhaustive taxonomy of negative sampling methods that can be used at evaluation time. (3) We carry out an empirical study of the effect of the different negative sampling strategies. Our comparison between heuristics and state-of-the-art memory-based methods on various real-world datasets confirms a strong effect of using different negative sampling strategies on the test Area Under the Curve (AUC). Moreover, we conduct a visual exploration of the prediction, with additional insights on which different types of errors are prominent over time.
KamerRaad: Enhancing Information Retrieval in Belgian National Politics through Hierarchical Summarization and Conversational Interfaces
Apr 22, 2024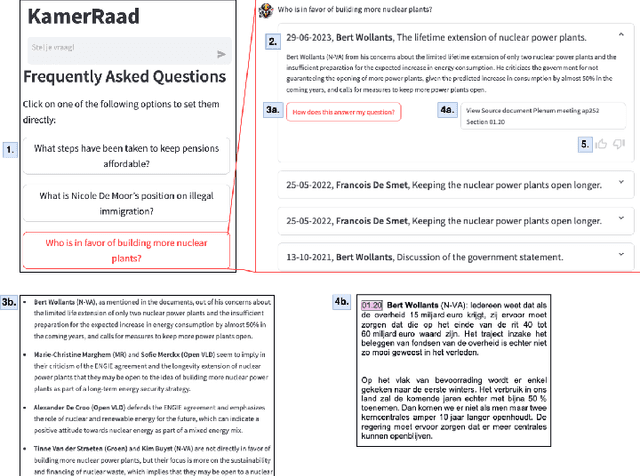
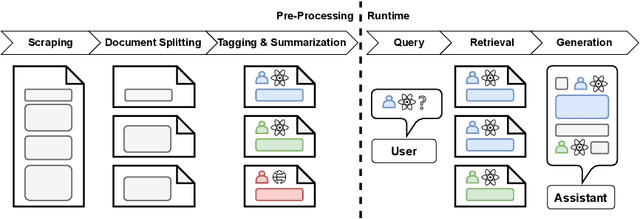
KamerRaad is an AI tool that leverages large language models to help citizens interactively engage with Belgian political information. The tool extracts and concisely summarizes key excerpts from parliamentary proceedings, followed by the potential for interaction based on generative AI that allows users to steadily build up their understanding. KamerRaad's front-end, built with Streamlit, facilitates easy interaction, while the back-end employs open-source models for text embedding and generation to ensure accurate and relevant responses. By collecting feedback, we intend to enhance the relevancy of our source retrieval and the quality of our summarization, thereby enriching the user experience with a focus on source-driven dialogue.