 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Deep Learning Models for Aerial LiDAR Point Cloud Semantic Segmentation under Real Acquisition Conditions: A Case Study in Navarre
Mar 23, 2026Recent advances in deep learning have significantly improved 3D semantic segmentation, but most models focus on indoor or terrestrial datasets. Their behavior under real aerial acquisition conditions remains insufficiently explored, and although a few studies have addressed similar scenarios, they differ in dataset design, acquisition conditions, and model selection. To address this gap, we conduct an experimental benchmark evaluating several state-of-the-art architectures on a large-scale aerial LiDAR dataset acquired under operational flight conditions in Navarre, Spain, covering heterogeneous urban, rural, and industrial landscapes. This study compares four representative deep learning models, including KPConv, RandLA-Net, Superpoint Transformer, and Point Transformer V3, across five semantic classes commonly found in airborne surveys, such as ground, vegetation, buildings, and vehicles, highlighting the inherent challenges of class imbalance and geometric variability in aerial data. Results show that all tested models achieve high overall accuracy exceeding 93%, with KPConv attaining the highest mean IoU (78.51%) through consistent performance across classes, particularly on challenging and underrepresented categories. Point Transformer V3 demonstrates superior performance on the underrepresented vehicle class (75.11% IoU), while Superpoint Transformer and RandLA-Net trade off segmentation robustness for computational efficiency.
Spatially-Aware Evaluation Framework for Aerial LiDAR Point Cloud Semantic Segmentation: Distance-Based Metrics on Challenging Regions
Mar 23, 2026Semantic segmentation metrics for 3D point clouds, such as mean Intersection over Union (mIoU) and Overall Accuracy (OA), present two key limitations in the context of aerial LiDAR data. First, they treat all misclassifications equally regardless of their spatial context, overlooking cases where the geometric severity of errors directly impacts the quality of derived geospatial products such as Digital Terrain Models. Second, they are often dominated by the large proportion of easily classified points, which can mask meaningful differences between models and under-represent performance in challenging regions. To address these limitations, we propose a novel evaluation framework for comparing semantic segmentation models through two complementary approaches. First, we introduce distance-based metrics that account for the spatial deviation between each misclassified point and the nearest ground-truth point of the predicted class, capturing the geometric severity of errors. Second, we propose a focused evaluation on a common subset of hard points, defined as the points misclassified by at least one of the evaluated models, thereby reducing the bias introduced by easily classified points and better revealing differences in model performance in challenging regions. We validate our framework by comparing three state-of-the-art deep learning models on three aerial LiDAR datasets. Results demonstrate that the proposed metrics provide complementary information to traditional measures, revealing spatial error patterns that are critical for Earth Observation applications but invisible to conventional evaluation approaches. The proposed framework enables more informed model selection for scenarios where spatial consistency is critical.
Few-shot multi-token DreamBooth with LoRa for style-consistent character generation
Oct 10, 2025The audiovisual industry is undergoing a profound transformation as it is integrating AI developments not only to automate routine tasks but also to inspire new forms of art. This paper addresses the problem of producing a virtually unlimited number of novel characters that preserve the artistic style and shared visual traits of a small set of human-designed reference characters, thus broadening creative possibilities in animation, gaming, and related domains. Our solution builds upon DreamBooth, a well-established fine-tuning technique for text-to-image diffusion models, and adapts it to tackle two core challenges: capturing intricate character details beyond textual prompts and the few-shot nature of the training data. To achieve this, we propose a multi-token strategy, using clustering to assign separate tokens to individual characters and their collective style, combined with LoRA-based parameter-efficient fine-tuning. By removing the class-specific regularization set and introducing random tokens and embeddings during generation, our approach allows for unlimited character creation while preserving the learned style. We evaluate our method on five small specialized datasets, comparing it to relevant baselines using both quantitative metrics and a human evaluation study. Our results demonstrate that our approach produces high-quality, diverse characters while preserving the distinctive aesthetic features of the reference characters, with human evaluation further reinforcing its effectiveness and highlighting the potential of our method.
Biased Heritage: How Datasets Shape Models in Facial Expression Recognition
Mar 05, 2025In recent years, the rapid development of artificial intelligence (AI) systems has raised concerns about our ability to ensure their fairness, that is, how to avoid discrimination based on protected characteristics such as gender, race, or age. While algorithmic fairness is well-studied in simple binary classification tasks on tabular data, its application to complex, real-world scenarios-such as Facial Expression Recognition (FER)-remains underexplored. FER presents unique challenges: it is inherently multiclass, and biases emerge across intersecting demographic variables, each potentially comprising multiple protected groups. We present a comprehensive framework to analyze bias propagation from datasets to trained models in image-based FER systems, while introducing new bias metrics specifically designed for multiclass problems with multiple demographic groups. Our methodology studies bias propagation by (1) inducing controlled biases in FER datasets, (2) training models on these biased datasets, and (3) analyzing the correlation between dataset bias metrics and model fairness notions. Our findings reveal that stereotypical biases propagate more strongly to model predictions than representational biases, suggesting that preventing emotion-specific demographic patterns should be prioritized over general demographic balance in FER datasets. Additionally, we observe that biased datasets lead to reduced model accuracy, challenging the assumed fairness-accuracy trade-off.
Improving diabetic retinopathy screening using Artificial Intelligence: design, evaluation and before-and-after study of a custom development
Dec 18, 2024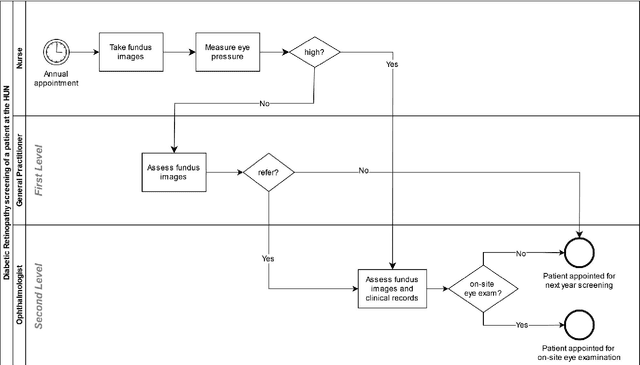


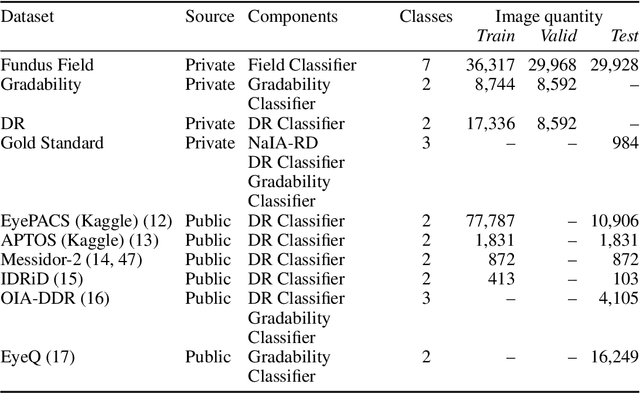
Background: The worst outcomes of diabetic retinopathy (DR) can be prevented by implementing DR screening programs assisted by AI. At the University Hospital of Navarre (HUN), Spain, general practitioners (GPs) grade fundus images in an ongoing DR screening program, referring to a second screening level (ophthalmologist) target patients. Methods: After collecting their requirements, HUN decided to develop a custom AI tool, called NaIA-RD, to assist their GPs in DR screening. This paper introduces NaIA-RD, details its implementation, and highlights its unique combination of DR and retinal image quality grading in a single system. Its impact is measured in an unprecedented before-and-after study that compares 19,828 patients screened before NaIA-RD's implementation and 22,962 patients screened after. Results: NaIA-RD influenced the screening criteria of 3/4 GPs, increasing their sensitivity. Agreement between NaIA-RD and the GPs was high for non-referral proposals (94.6% or more), but lower and variable (from 23.4\% to 86.6%) for referral proposals. An ophthalmologist discarded a NaIA-RD error in most of contradicted referral proposals by labeling the 93% of a sample of them as referable. In an autonomous setup, NaIA-RD would have reduced the study visualization workload by 4.27 times without missing a single case of sight-threatening DR referred by a GP. Conclusion: DR screening was more effective when supported by NaIA-RD, which could be safely used to autonomously perform the first level of screening. This shows how AI devices, when seamlessly integrated into clinical workflows, can help improve clinical pathways in the long term.
Less can be more: representational vs. stereotypical gender bias in facial expression recognition
Jun 25, 2024Machine learning models can inherit biases from their training data, leading to discriminatory or inaccurate predictions. This is particularly concerning with the increasing use of large, unsupervised datasets for training foundational models. Traditionally, demographic biases within these datasets have not been well-understood, limiting our ability to understand how they propagate to the models themselves. To address this issue, this paper investigates the propagation of demographic biases from datasets into machine learning models. We focus on the gender demographic component, analyzing two types of bias: representational and stereotypical. For our analysis, we consider the domain of facial expression recognition (FER), a field known to exhibit biases in most popular datasets. We use Affectnet, one of the largest FER datasets, as our baseline for carefully designing and generating subsets that incorporate varying strengths of both representational and stereotypical bias. Subsequently, we train several models on these biased subsets, evaluating their performance on a common test set to assess the propagation of bias into the models' predictions. Our results show that representational bias has a weaker impact than expected. Models exhibit a good generalization ability even in the absence of one gender in the training dataset. Conversely, stereotypical bias has a significantly stronger impact, primarily concentrated on the biased class, although it can also influence predictions for unbiased classes. These results highlight the need for a bias analysis that differentiates between types of bias, which is crucial for the development of effective bias mitigation strategies.
DSAP: Analyzing Bias Through Demographic Comparison of Datasets
Dec 22, 2023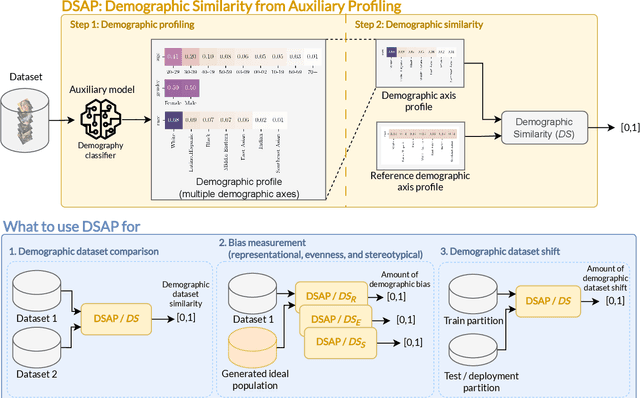
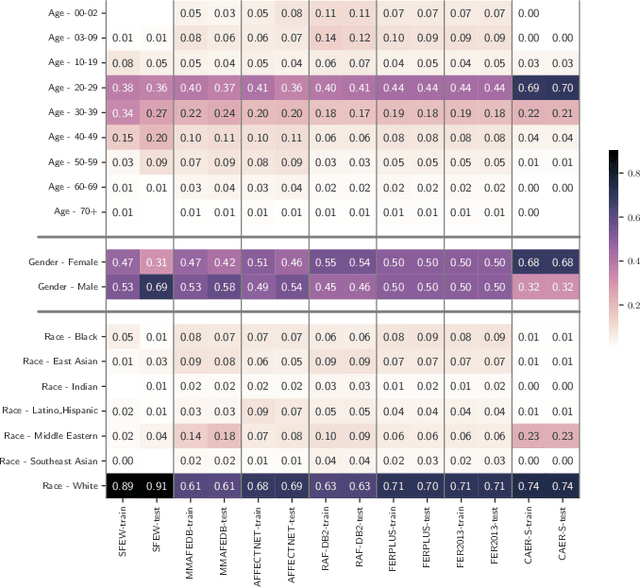
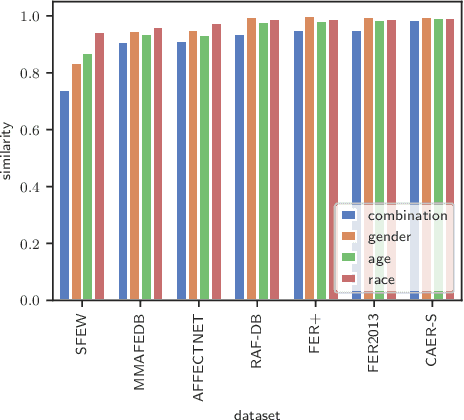
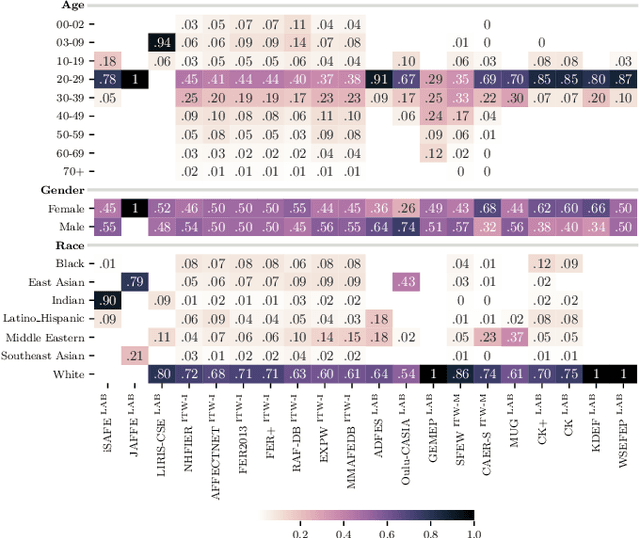
In the last few years, Artificial Intelligence systems have become increasingly widespread. Unfortunately, these systems can share many biases with human decision-making, including demographic biases. Often, these biases can be traced back to the data used for training, where large uncurated datasets have become the norm. Despite our knowledge of these biases, we still lack general tools to detect and quantify them, as well as to compare the biases in different datasets. Thus, in this work, we propose DSAP (Demographic Similarity from Auxiliary Profiles), a two-step methodology for comparing the demographic composition of two datasets. DSAP can be deployed in three key applications: to detect and characterize demographic blind spots and bias issues across datasets, to measure dataset demographic bias in single datasets, and to measure dataset demographic shift in deployment scenarios. An essential feature of DSAP is its ability to robustly analyze datasets without explicit demographic labels, offering simplicity and interpretability for a wide range of situations. To show the usefulness of the proposed methodology, we consider the Facial Expression Recognition task, where demographic bias has previously been found. The three applications are studied over a set of twenty datasets with varying properties. The code is available at https://github.com/irisdominguez/DSAP.
Metrics for Dataset Demographic Bias: A Case Study on Facial Expression Recognition
Mar 28, 2023
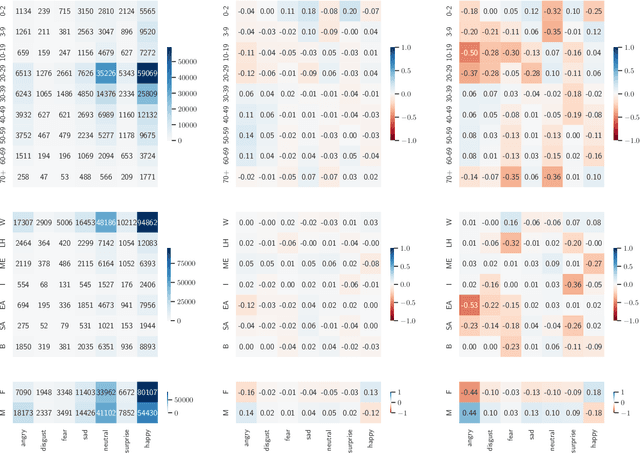
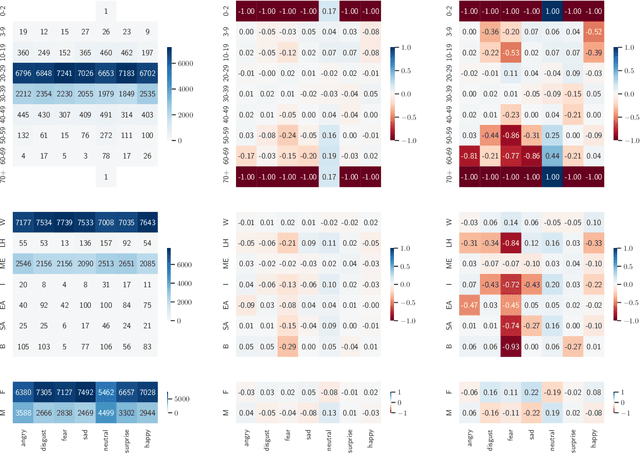
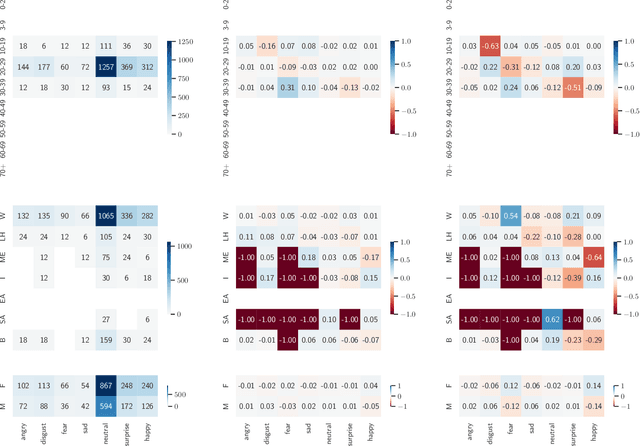
Demographic biases in source datasets have been shown as one of the causes of unfairness and discrimination in the predictions of Machine Learning models. One of the most prominent types of demographic bias are statistical imbalances in the representation of demographic groups in the datasets. In this paper, we study the measurement of these biases by reviewing the existing metrics, including those that can be borrowed from other disciplines. We develop a taxonomy for the classification of these metrics, providing a practical guide for the selection of appropriate metrics. To illustrate the utility of our framework, and to further understand the practical characteristics of the metrics, we conduct a case study of 20 datasets used in Facial Emotion Recognition (FER), analyzing the biases present in them. Our experimental results show that many metrics are redundant and that a reduced subset of metrics may be sufficient to measure the amount of demographic bias. The paper provides valuable insights for researchers in AI and related fields to mitigate dataset bias and improve the fairness and accuracy of AI models. The code is available at https://github.com/irisdominguez/dataset_bias_metrics.
Multimodal Parameter-Efficient Few-Shot Class Incremental Learning
Mar 08, 2023

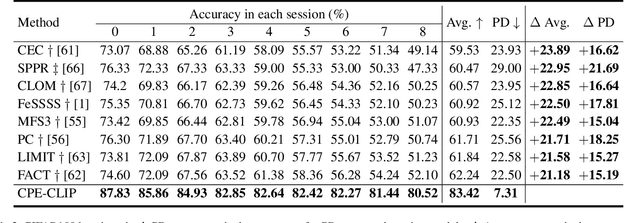

Few-Shot Class Incremental Learning (FSCIL) is a challenging continual learning task, where limited training examples are available during several learning sessions. To succeed in this task, it is necessary to avoid over-fitting new classes caused by biased distributions in the few-shot training sets. The general approach to address this issue involves enhancing the representational capability of a pre-defined backbone architecture by adding special modules for backward compatibility with older classes. However, this approach has not yet solved the dilemma of ensuring high classification accuracy over time while reducing the gap between the performance obtained on larger training sets and the smaller ones. In this work, we propose an alternative approach called Continual Parameter-Efficient CLIP (CPE-CLIP) to reduce the loss of information between different learning sessions. Instead of adapting additional modules to address information loss, we leverage the vast knowledge acquired by CLIP in large-scale pre-training and its effectiveness in generalizing to new concepts. Our approach is multimodal and parameter-efficient, relying on learnable prompts for both the language and vision encoders to enable transfer learning across sessions. We also introduce prompt regularization to improve performance and prevent forgetting. Our experimental results demonstrate that CPE-CLIP significantly improves FSCIL performance compared to state-of-the-art proposals while also drastically reducing the number of learnable parameters and training costs.
Gender Stereotyping Impact in Facial Expression Recognition
Oct 11, 2022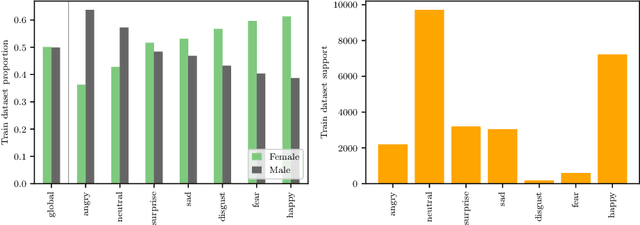
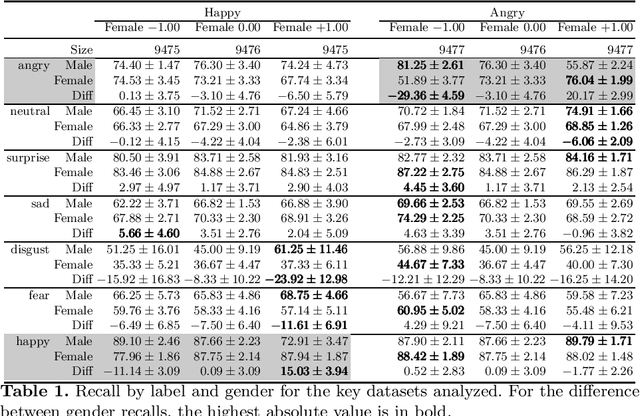
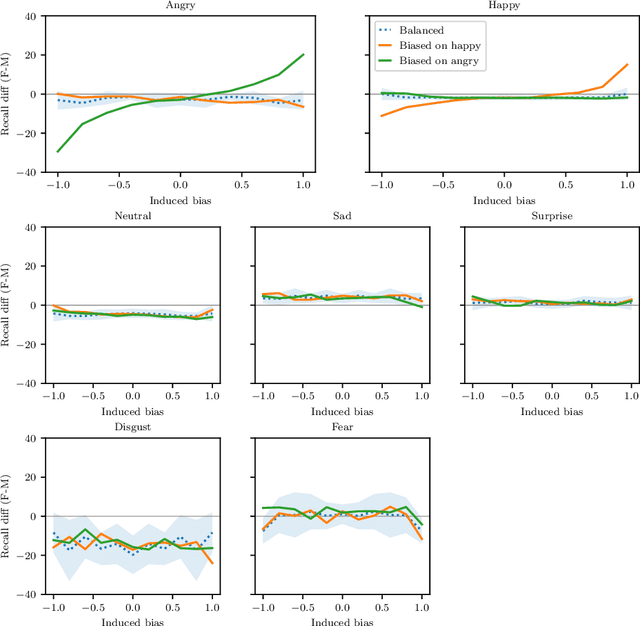
Facial Expression Recognition (FER) uses images of faces to identify the emotional state of users, allowing for a closer interaction between humans and autonomous systems. Unfortunately, as the images naturally integrate some demographic information, such as apparent age, gender, and race of the subject, these systems are prone to demographic bias issues. In recent years, machine learning-based models have become the most popular approach to FER. These models require training on large datasets of facial expression images, and their generalization capabilities are strongly related to the characteristics of the dataset. In publicly available FER datasets, apparent gender representation is usually mostly balanced, but their representation in the individual label is not, embedding social stereotypes into the datasets and generating a potential for harm. Although this type of bias has been overlooked so far, it is important to understand the impact it may have in the context of FER. To do so, we use a popular FER dataset, FER+, to generate derivative datasets with different amounts of stereotypical bias by altering the gender proportions of certain labels. We then proceed to measure the discrepancy between the performance of the models trained on these datasets for the apparent gender groups. We observe a discrepancy in the recognition of certain emotions between genders of up to $29 \%$ under the worst bias conditions. Our results also suggest a safety range for stereotypical bias in a dataset that does not appear to produce stereotypical bias in the resulting model. Our findings support the need for a thorough bias analysis of public datasets in problems like FER, where a global balance of demographic representation can still hide other types of bias that harm certain demographic groups.