 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUntangling Input Language from Reasoning Language: A Diagnostic Framework for Cross-Lingual Moral Alignment in LLMs
Jan 15, 2026When LLMs judge moral dilemmas, do they reach different conclusions in different languages, and if so, why? Two factors could drive such differences: the language of the dilemma itself, or the language in which the model reasons. Standard evaluation conflates these by testing only matched conditions (e.g., English dilemma with English reasoning). We introduce a methodology that separately manipulates each factor, covering also mismatched conditions (e.g., English dilemma with Chinese reasoning), enabling decomposition of their contributions. To study \emph{what} changes, we propose an approach to interpret the moral judgments in terms of Moral Foundations Theory. As a side result, we identify evidence for splitting the Authority dimension into a family-related and an institutional dimension. Applying this methodology to English-Chinese moral judgment with 13 LLMs, we demonstrate its diagnostic power: (1) the framework isolates reasoning-language effects as contributing twice the variance of input-language effects; (2) it detects context-dependency in nearly half of models that standard evaluation misses; and (3) a diagnostic taxonomy translates these patterns into deployment guidance. We release our code and datasets at https://anonymous.4open.science/r/CrossCulturalMoralJudgement.
Building Data-Driven Occupation Taxonomies: A Bottom-Up Multi-Stage Approach via Semantic Clustering and Multi-Agent Collaboration
Sep 19, 2025Creating robust occupation taxonomies, vital for applications ranging from job recommendation to labor market intelligence, is challenging. Manual curation is slow, while existing automated methods are either not adaptive to dynamic regional markets (top-down) or struggle to build coherent hierarchies from noisy data (bottom-up). We introduce CLIMB (CLusterIng-based Multi-agent taxonomy Builder), a framework that fully automates the creation of high-quality, data-driven taxonomies from raw job postings. CLIMB uses global semantic clustering to distill core occupations, then employs a reflection-based multi-agent system to iteratively build a coherent hierarchy. On three diverse, real-world datasets, we show that CLIMB produces taxonomies that are more coherent and scalable than existing methods and successfully capture unique regional characteristics. We release our code and datasets at https://anonymous.4open.science/r/CLIMB.
Your Next State-of-the-Art Could Come from Another Domain: A Cross-Domain Analysis of Hierarchical Text Classification
Dec 17, 2024
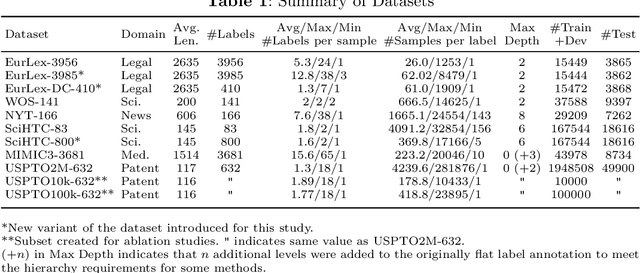
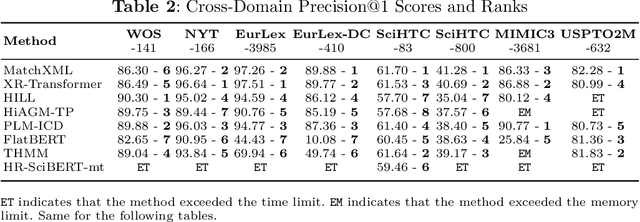
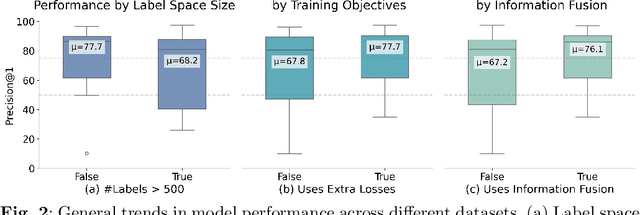
Text classification with hierarchical labels is a prevalent and challenging task in natural language processing. Examples include assigning ICD codes to patient records, tagging patents into IPC classes, assigning EUROVOC descriptors to European legal texts, and more. Despite its widespread applications, a comprehensive understanding of state-of-the-art methods across different domains has been lacking. In this paper, we provide the first comprehensive cross-domain overview with empirical analysis of state-of-the-art methods. We propose a unified framework that positions each method within a common structure to facilitate research. Our empirical analysis yields key insights and guidelines, confirming the necessity of learning across different research areas to design effective methods. Notably, under our unified evaluation pipeline, we achieved new state-of-the-art results by applying techniques beyond their original domains.
Content-Agnostic Moderation for Stance-Neutral Recommendation
May 29, 2024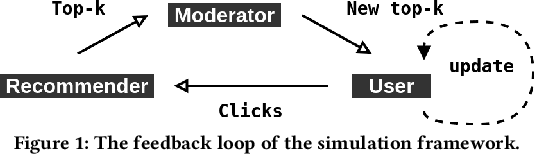
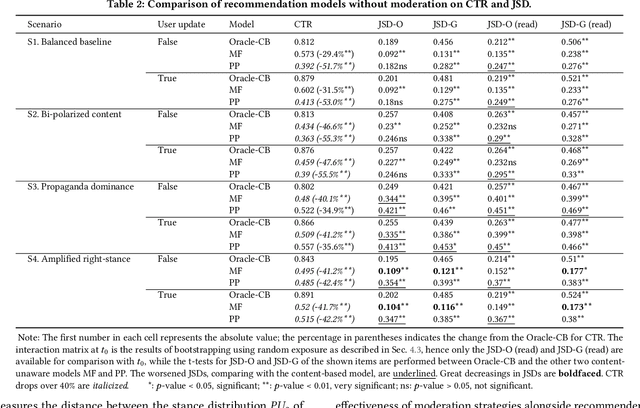
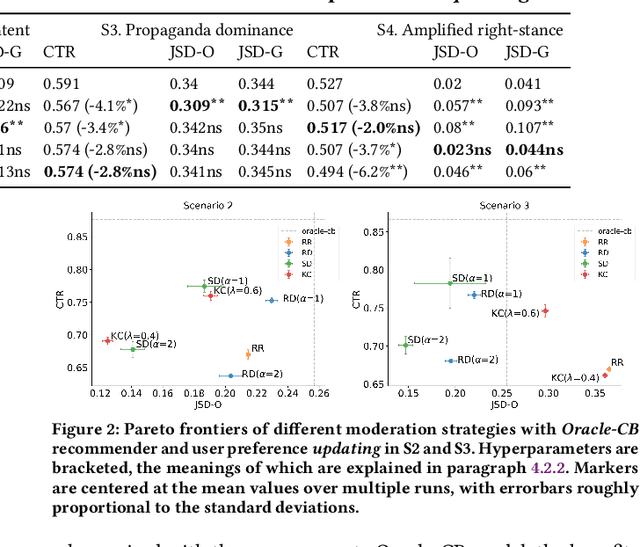
Personalized recommendation systems often drive users towards more extreme content, exacerbating opinion polarization. While (content-aware) moderation has been proposed to mitigate these effects, such approaches risk curtailing the freedom of speech and of information. To address this concern, we propose and explore the feasibility of \emph{content-agnostic} moderation as an alternative approach for reducing polarization. Content-agnostic moderation does not rely on the actual content being moderated, arguably making it less prone to forms of censorship. We establish theoretically that content-agnostic moderation cannot be guaranteed to work in a fully generic setting. However, we show that it can often be effectively achieved in practice with plausible assumptions. We introduce two novel content-agnostic moderation methods that modify the recommendations from the content recommender to disperse user-item co-clusters without relying on content features. To evaluate the potential of content-agnostic moderation in controlled experiments, we built a simulation environment to analyze the closed-loop behavior of a system with a given set of users, recommendation system, and moderation approach. Through comprehensive experiments in this environment, we show that our proposed moderation methods significantly enhance stance neutrality and maintain high recommendation quality across various data scenarios. Our results indicate that achieving stance neutrality without direct content information is not only feasible but can also help in developing more balanced and informative recommendation systems without substantially degrading user engagement.
KamerRaad: Enhancing Information Retrieval in Belgian National Politics through Hierarchical Summarization and Conversational Interfaces
Apr 22, 2024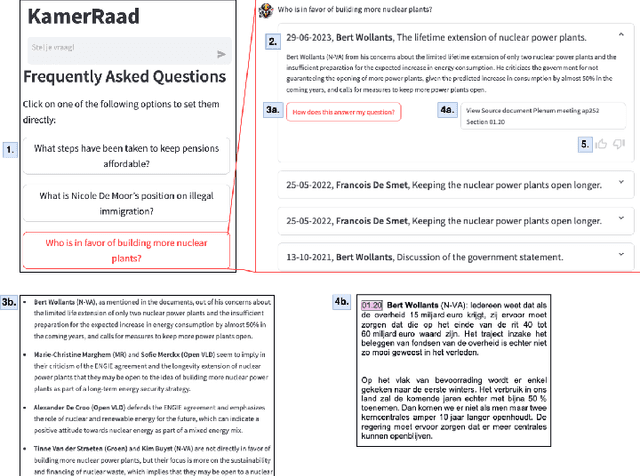
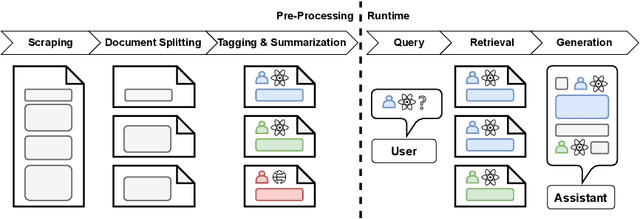
KamerRaad is an AI tool that leverages large language models to help citizens interactively engage with Belgian political information. The tool extracts and concisely summarizes key excerpts from parliamentary proceedings, followed by the potential for interaction based on generative AI that allows users to steadily build up their understanding. KamerRaad's front-end, built with Streamlit, facilitates easy interaction, while the back-end employs open-source models for text embedding and generation to ensure accurate and relevant responses. By collecting feedback, we intend to enhance the relevancy of our source retrieval and the quality of our summarization, thereby enriching the user experience with a focus on source-driven dialogue.
FEIR: Quantifying and Reducing Envy and Inferiority for Fair Recommendation of Limited Resources
Nov 08, 2023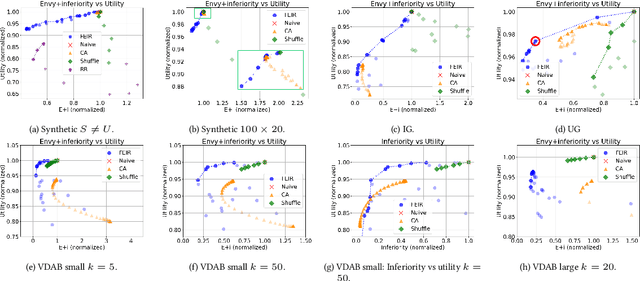
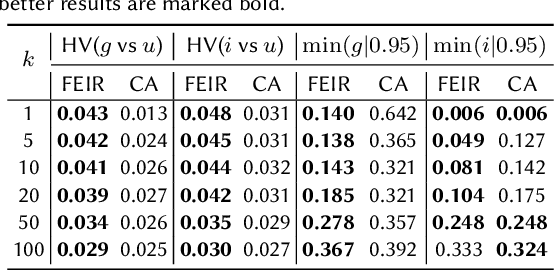
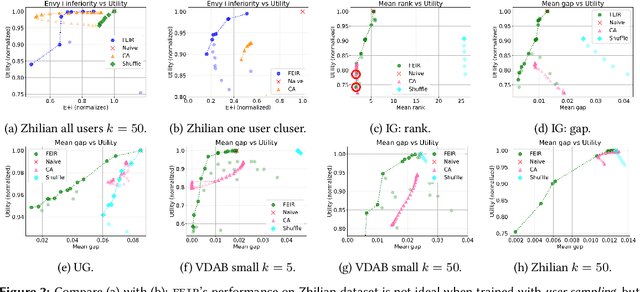
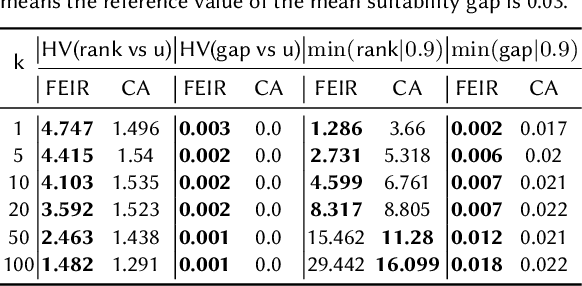
In settings such as e-recruitment and online dating, recommendation involves distributing limited opportunities, calling for novel approaches to quantify and enforce fairness. We introduce \emph{inferiority}, a novel (un)fairness measure quantifying a user's competitive disadvantage for their recommended items. Inferiority complements \emph{envy}, a fairness notion measuring preference for others' recommendations. We combine inferiority and envy with \emph{utility}, an accuracy-related measure of aggregated relevancy scores. Since these measures are non-differentiable, we reformulate them using a probabilistic interpretation of recommender systems, yielding differentiable versions. We combine these loss functions in a multi-objective optimization problem called \texttt{FEIR} (Fairness through Envy and Inferiority Reduction), applied as post-processing for standard recommender systems. Experiments on synthetic and real-world data demonstrate that our approach improves trade-offs between inferiority, envy, and utility compared to naive recommendations and the baseline methods.
LLM4Jobs: Unsupervised occupation extraction and standardization leveraging Large Language Models
Sep 19, 2023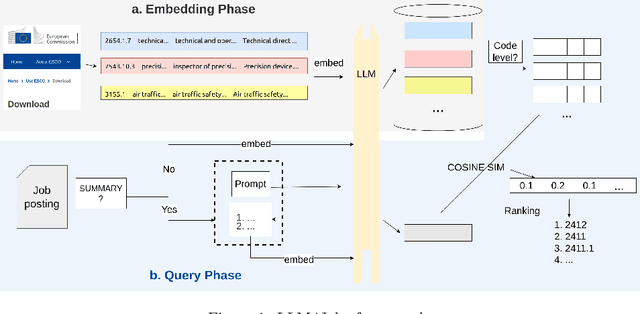
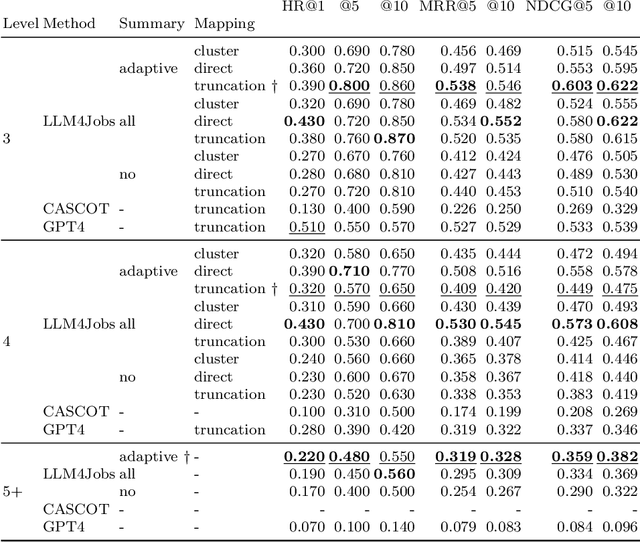
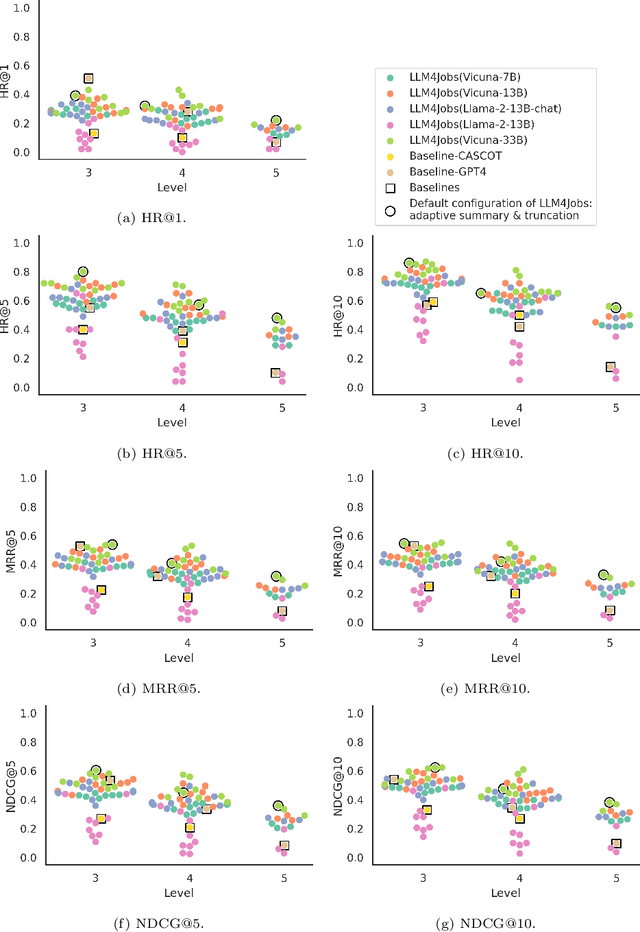
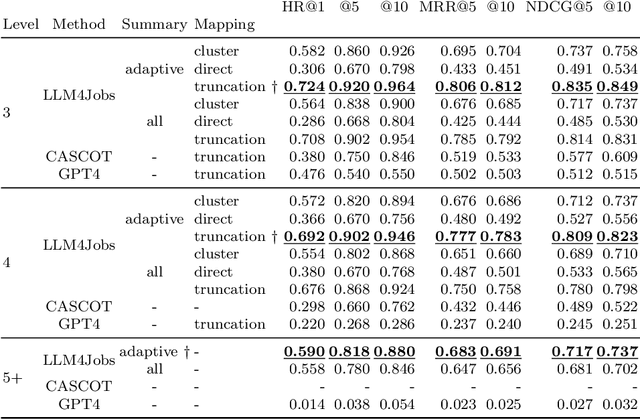
Automated occupation extraction and standardization from free-text job postings and resumes are crucial for applications like job recommendation and labor market policy formation. This paper introduces LLM4Jobs, a novel unsupervised methodology that taps into the capabilities of large language models (LLMs) for occupation coding. LLM4Jobs uniquely harnesses both the natural language understanding and generation capacities of LLMs. Evaluated on rigorous experimentation on synthetic and real-world datasets, we demonstrate that LLM4Jobs consistently surpasses unsupervised state-of-the-art benchmarks, demonstrating its versatility across diverse datasets and granularities. As a side result of our work, we present both synthetic and real-world datasets, which may be instrumental for subsequent research in this domain. Overall, this investigation highlights the promise of contemporary LLMs for the intricate task of occupation extraction and standardization, laying the foundation for a robust and adaptable framework relevant to both research and industrial contexts.
ReCon: Reducing Congestion in Job Recommendation using Optimal Transport
Aug 18, 2023



Recommender systems may suffer from congestion, meaning that there is an unequal distribution of the items in how often they are recommended. Some items may be recommended much more than others. Recommenders are increasingly used in domains where items have limited availability, such as the job market, where congestion is especially problematic: Recommending a vacancy -- for which typically only one person will be hired -- to a large number of job seekers may lead to frustration for job seekers, as they may be applying for jobs where they are not hired. This may also leave vacancies unfilled and result in job market inefficiency. We propose a novel approach to job recommendation called ReCon, accounting for the congestion problem. Our approach is to use an optimal transport component to ensure a more equal spread of vacancies over job seekers, combined with a job recommendation model in a multi-objective optimization problem. We evaluated our approach on two real-world job market datasets. The evaluation results show that ReCon has good performance on both congestion-related (e.g., Congestion) and desirability (e.g., NDCG) measures.
SkillGPT: a RESTful API service for skill extraction and standardization using a Large Language Model
Apr 17, 2023We present SkillGPT, a tool for skill extraction and standardization (SES) from free-style job descriptions and user profiles with an open-source Large Language Model (LLM) as backbone. Most previous methods for similar tasks either need supervision or rely on heavy data-preprocessing and feature engineering. Directly prompting the latest conversational LLM for standard skills, however, is slow, costly and inaccurate. In contrast, SkillGPT utilizes a LLM to perform its tasks in steps via summarization and vector similarity search, to balance speed with precision. The backbone LLM of SkillGPT is based on Llama, free for academic use and thus useful for exploratory research and prototype development. Hence, our cost-free SkillGPT gives users the convenience of conversational SES, efficiently and reliably.
Revised Conditional t-SNE: Looking Beyond the Nearest Neighbors
Feb 07, 2023Conditional t-SNE (ct-SNE) is a recent extension to t-SNE that allows removal of known cluster information from the embedding, to obtain a visualization revealing structure beyond label information. This is useful, for example, when one wants to factor out unwanted differences between a set of classes. We show that ct-SNE fails in many realistic settings, namely if the data is well clustered over the labels in the original high-dimensional space. We introduce a revised method by conditioning the high-dimensional similarities instead of the low-dimensional similarities and storing within- and across-label nearest neighbors separately. This also enables the use of recently proposed speedups for t-SNE, improving the scalability. From experiments on synthetic data, we find that our proposed method resolves the considered problems and improves the embedding quality. On real data containing batch effects, the expected improvement is not always there. We argue revised ct-SNE is preferable overall, given its improved scalability. The results also highlight new open questions, such as how to handle distance variations between clusters.