 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiMi Sheets: Infosheets for bias mitigation methods
May 28, 2025
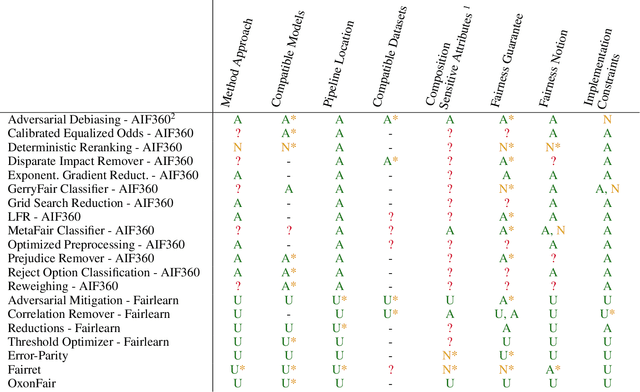
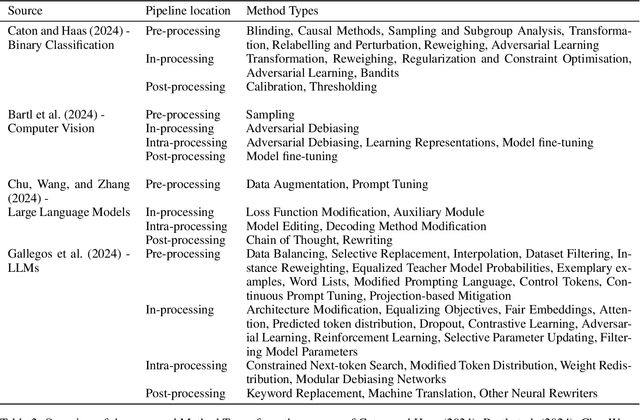

Over the past 15 years, hundreds of bias mitigation methods have been proposed in the pursuit of fairness in machine learning (ML). However, algorithmic biases are domain-, task-, and model-specific, leading to a `portability trap': bias mitigation solutions in one context may not be appropriate in another. Thus, a myriad of design choices have to be made when creating a bias mitigation method, such as the formalization of fairness it pursues, and where and how it intervenes in the ML pipeline. This creates challenges in benchmarking and comparing the relative merits of different bias mitigation methods, and limits their uptake by practitioners. We propose BiMi Sheets as a portable, uniform guide to document the design choices of any bias mitigation method. This enables researchers and practitioners to quickly learn its main characteristics and to compare with their desiderata. Furthermore, the sheets' structure allow for the creation of a structured database of bias mitigation methods. In order to foster the sheets' adoption, we provide a platform for finding and creating BiMi Sheets at bimisheet.com.
InfoClus: Informative Clustering of High-dimensional Data Embeddings
Apr 15, 2025



Developing an understanding of high-dimensional data can be facilitated by visualizing that data using dimensionality reduction. However, the low-dimensional embeddings are often difficult to interpret. To facilitate the exploration and interpretation of low-dimensional embeddings, we introduce a new concept named partitioning with explanations. The idea is to partition the data shown through the embedding into groups, each of which is given a sparse explanation using the original high-dimensional attributes. We introduce an objective function that quantifies how much we can learn through observing the explanations of the data partitioning, using information theory, and also how complex the explanations are. Through parameterization of the complexity, we can tune the solutions towards the desired granularity. We propose InfoClus, which optimizes the partitioning and explanations jointly, through greedy search constrained over a hierarchical clustering. We conduct a qualitative and quantitative analysis of InfoClus on three data sets. We contrast the results on the Cytometry data with published manual analysis results, and compare with two other recent methods for explaining embeddings (RVX and VERA). These comparisons highlight that InfoClus has distinct advantages over existing procedures and methods. We find that InfoClus can automatically create good starting points for the analysis of dimensionality-reduction-based scatter plots.
What Large Language Models Do Not Talk About: An Empirical Study of Moderation and Censorship Practices
Apr 04, 2025Large Language Models (LLMs) are increasingly deployed as gateways to information, yet their content moderation practices remain underexplored. This work investigates the extent to which LLMs refuse to answer or omit information when prompted on political topics. To do so, we distinguish between hard censorship (i.e., generated refusals, error messages, or canned denial responses) and soft censorship (i.e., selective omission or downplaying of key elements), which we identify in LLMs' responses when asked to provide information on a broad range of political figures. Our analysis covers 14 state-of-the-art models from Western countries, China, and Russia, prompted in all six official United Nations (UN) languages. Our analysis suggests that although censorship is observed across the board, it is predominantly tailored to an LLM provider's domestic audience and typically manifests as either hard censorship or soft censorship (though rarely both concurrently). These findings underscore the need for ideological and geographic diversity among publicly available LLMs, and greater transparency in LLM moderation strategies to facilitate informed user choices. All data are made freely available.