 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAFFLE: Watermarking in Federated Learning
Aug 17, 2020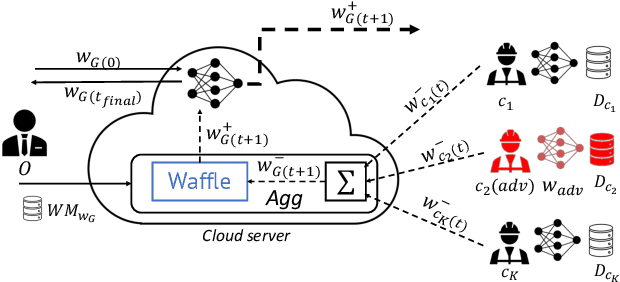


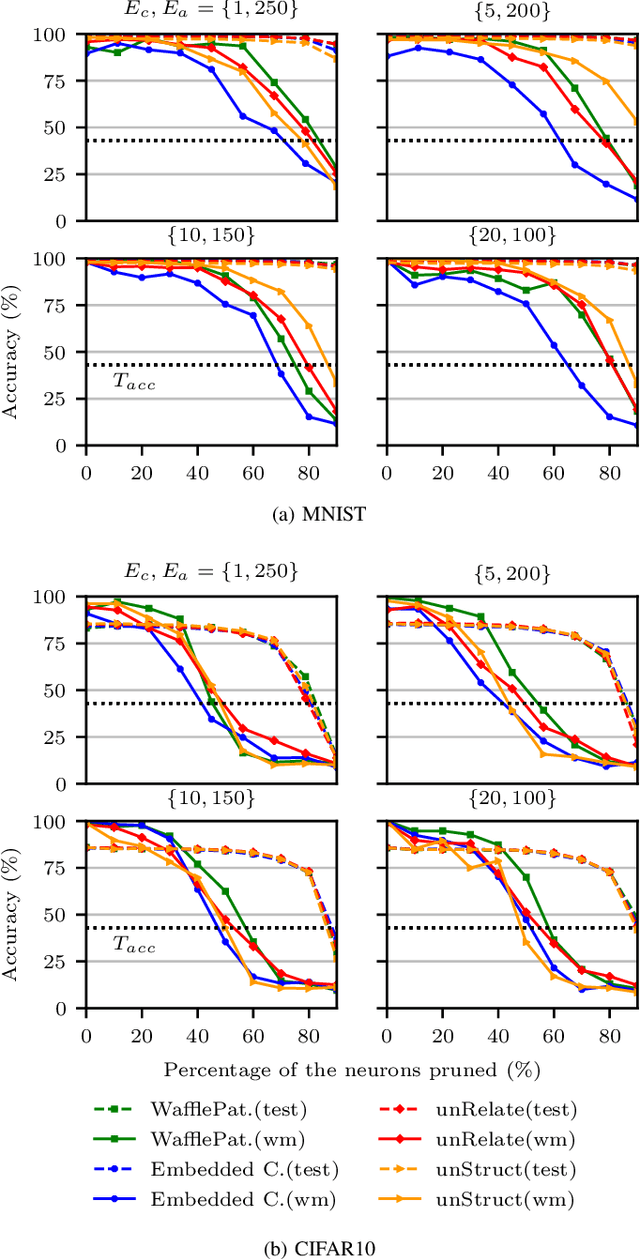
Creators of machine learning models can use watermarking as a technique to demonstrate their ownership if their models are stolen. Several recent proposals watermark deep neural network (DNN) models using backdooring: training them with additional mislabeled data. Backdooring requires full access to the training data and control of the training process. This is feasible when a single party trains the model in a centralized manner, but not in a federated learning setting where the training process and training data are distributed among several parties. In this paper, we introduce WAFFLE, the first approach to watermark DNN models in federated learning. It introduces a re-training step after each aggregation of local models into the global model. We show that WAFFLE efficiently embeds a resilient watermark into models with a negligible test accuracy degradation (-0.17%), and does not require access to the training data. We introduce a novel technique to generate the backdoor used as a watermark. It outperforms prior techniques, imposing no communication, and low computational(+2.8%) overhead.
Extraction of Complex DNN Models: Real Threat or Boogeyman?
Oct 11, 2019

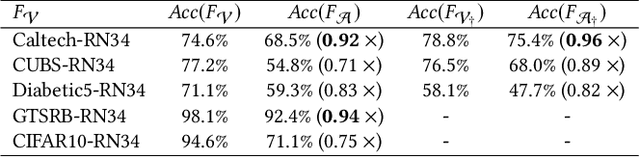
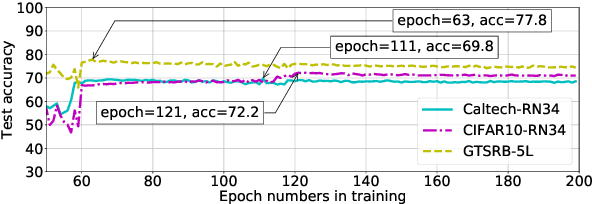
Recently, machine learning (ML) has introduced advanced solutions to many domains. Since ML models provide business advantage to model owners, protecting intellectual property (IP) of ML models has emerged as an important consideration. Confidentiality of ML models can be protected by exposing them to clients only via prediction APIs. However, model extraction attacks can steal the functionality of ML models using the information leaked to clients through the results returned via the API. In this work, we question whether model extraction is a serious threat to complex, real-life ML models. We evaluate the current state-of-the-art model extraction attack (the Knockoff attack) against complex models. We reproduced and confirm the results in the Knockoff attack paper. But we also show that the performance of this attack can be limited by several factors, including ML model architecture and the granularity of API response. Furthermore, we introduce a defense based on distinguishing queries used for Knockoff attack from benign queries. Despite the limitations of the Knockoff attack, we show that a more realistic adversary can effectively steal complex ML models and evade known defenses.
DAWN: Dynamic Adversarial Watermarking of Neural Networks
Jun 12, 2019
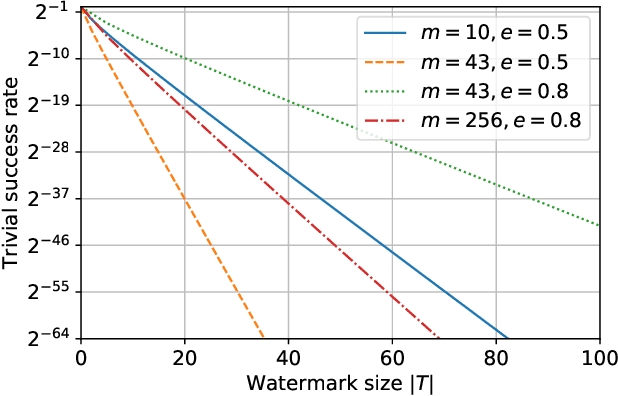
Training machine learning (ML) models is expensive in terms of computational power, large amounts of labeled data, and human expertise. Thus, ML models constitute intellectual property (IP) and business value for their owners. Embedding digital watermarks during model training allows a model owner to later identify their models in case of theft or misuse. However, model functionality can also be stolen via model extraction, where an adversary trains a surrogate model using results returned from a prediction API of the original model. Recent work has shown that model extraction is a realistic threat. Existing watermarking schemes are ineffective against IP theft via model extraction since it is the adversary who trains the surrogate model. In this paper, we introduce DAWN (Dynamic Adversarial Watermarking of Neural Networks), the first approach to use watermarking to deter IP theft via model extraction. Unlike prior watermarking schemes, DAWN does not impose changes to the training process. Instead, it operates at the prediction API of the protected model, by dynamically changing the responses for a small subset of queries (e.g. $<0.5\%$) from API clients. This set represents a watermark that will be embedded in case a client uses its queries to train a surrogate model. We show that DAWN is resilient against two state-of-the-art model extraction attacks, effectively watermarking all extracted surrogate models, allowing model owners to reliably demonstrate ownership (with confidence $>1-2^{-64}$), incurring negligible loss of prediction accuracy ($0.03-0.5\%$).
Making targeted black-box evasion attacks effective and efficient
Jun 08, 2019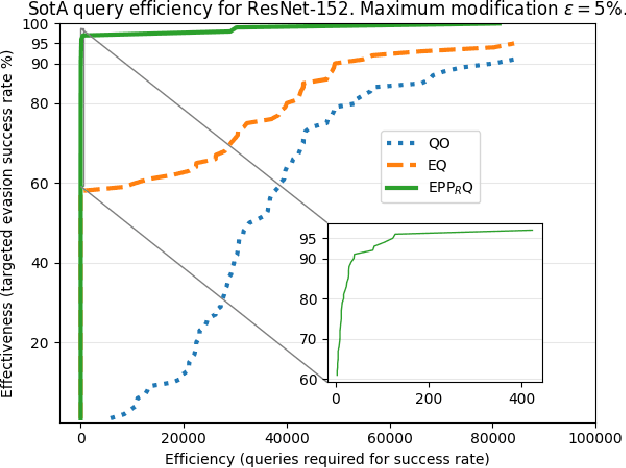


We investigate how an adversary can optimally use its query budget for targeted evasion attacks against deep neural networks in a black-box setting. We formalize the problem setting and systematically evaluate what benefits the adversary can gain by using substitute models. We show that there is an exploration-exploitation tradeoff in that query efficiency comes at the cost of effectiveness. We present two new attack strategies for using substitute models and show that they are as effective as previous query-only techniques but require significantly fewer queries, by up to three orders of magnitude. We also show that an agile adversary capable of switching through different attack techniques can achieve pareto-optimal efficiency. We demonstrate our attack against Google Cloud Vision showing that the difficulty of black-box attacks against real-world prediction APIs is significantly easier than previously thought (requiring approximately 500 queries instead of approximately 20,000 as in previous works).
Online Feature Ranking for Intrusion Detection Systems
Jun 15, 2018



Many current approaches to the design of intrusion detection systems apply feature selection in a static, non-adaptive fashion. These methods often neglect the dynamic nature of network data which requires to use adaptive feature selection techniques. In this paper, we present a simple technique based on incremental learning of support vector machines in order to rank the features in real time within a streaming model for network data. Some illustrative numerical experiments with two popular benchmark datasets show that our approach allows to adapt to the changes in normal network behaviour and novel attack patterns which have not been experienced before.
Human-guided data exploration using randomisation
May 20, 2018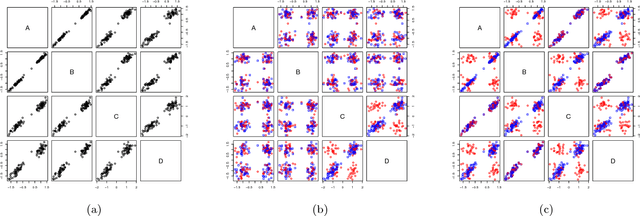

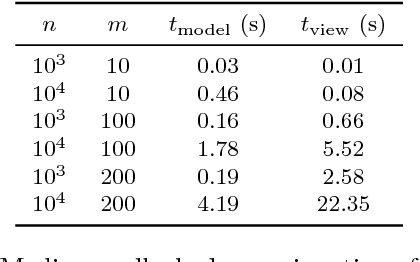
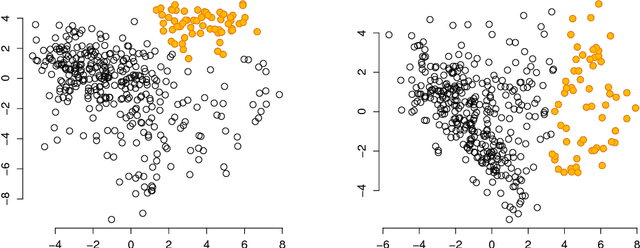
An explorative data analysis system should be aware of what the user already knows and what the user wants to know of the data: otherwise the system cannot provide the user with the most informative and useful views of the data. We propose a principled way to do explorative data analysis, where the user's background knowledge is modeled by a distribution parametrised by subsets of rows and columns in the data, called tiles. The user can also use tiles to describe his or her interests concerning relations in the data. We provide a computationally efficient implementation of this concept based on constrained randomisation. This is used to model both the background knowledge and the user's information request and is a necessary prerequisite for any interactive system. Furthermore, we describe a novel linear projection pursuit method to find and show the views most informative to the user, which at the limit of no background knowledge and with generic objective reduces to PCA. We show that our method is robust under noise and fast enough for interactive use. We also show that the method gives understandable and useful results when analysing real-world data sets. We will release, under an open source license, a software library implementing the idea, including the experiments presented in this paper. We show that our method can outperform standard projection pursuit visualisation methods in exploration tasks. Our framework makes it possible to construct human-guided data exploration systems which are fast, powerful, and give results that are easy to comprehend.