 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmulet: a Python Library for Assessing Interactions Among ML Defenses and Risks
Sep 15, 2025
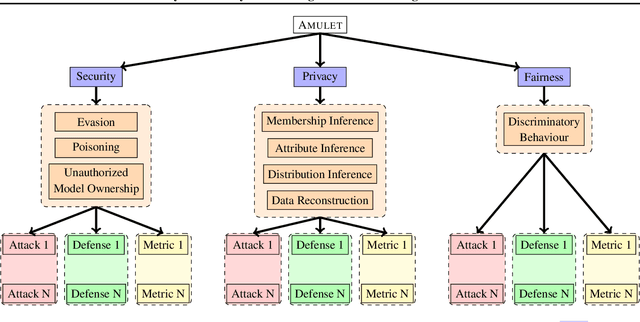
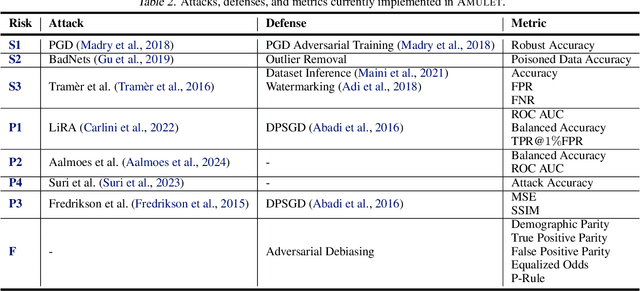
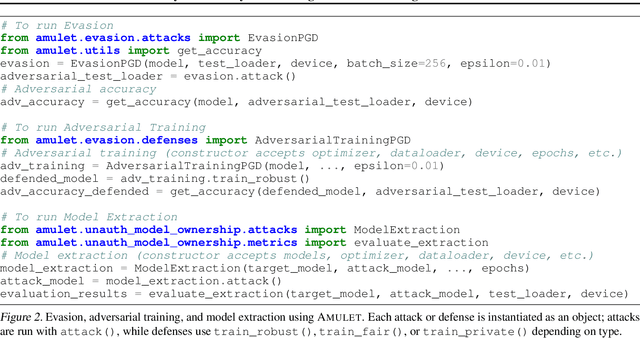
ML models are susceptible to risks to security, privacy, and fairness. Several defenses are designed to protect against their intended risks, but can inadvertently affect susceptibility to other unrelated risks, known as unintended interactions. Several jurisdictions are preparing ML regulatory frameworks that require ML practitioners to assess the susceptibility of ML models to different risks. A library for valuating unintended interactions that can be used by (a) practitioners to evaluate unintended interactions at scale prior to model deployment and (b) researchers to design defenses which do not suffer from an unintended increase in unrelated risks. Ideally, such a library should be i) comprehensive by including representative attacks, defenses and metrics for different risks, ii) extensible to new modules due to its modular design, iii) consistent with a user-friendly API template for inputs and outputs, iv) applicable to evaluate previously unexplored unintended interactions. We present AMULET, a Python library that covers risks to security, privacy, and fairness, which satisfies all these requirements. AMULET can be used to evaluate unexplored unintended interactions, compare effectiveness between defenses or attacks, and include new attacks and defenses.
Atlas: A Framework for ML Lifecycle Provenance & Transparency
Feb 26, 2025The rapid adoption of open source machine learning (ML) datasets and models exposes today's AI applications to critical risks like data poisoning and supply chain attacks across the ML lifecycle. With growing regulatory pressure to address these issues through greater transparency, ML model vendors face challenges balancing these requirements against confidentiality for data and intellectual property needs. We propose Atlas, a framework that enables fully attestable ML pipelines. Atlas leverages open specifications for data and software supply chain provenance to collect verifiable records of model artifact authenticity and end-to-end lineage metadata. Atlas combines trusted hardware and transparency logs to enhance metadata integrity, preserve data confidentiality, and limit unauthorized access during ML pipeline operations, from training through deployment. Our prototype implementation of Atlas integrates several open-source tools to build an ML lifecycle transparency system, and assess the practicality of Atlas through two case study ML pipelines.
Soft Token Attacks Cannot Reliably Audit Unlearning in Large Language Models
Feb 20, 2025Large language models (LLMs) have become increasingly popular. Their emergent capabilities can be attributed to their massive training datasets. However, these datasets often contain undesirable or inappropriate content, e.g., harmful texts, personal information, and copyrighted material. This has promoted research into machine unlearning that aims to remove information from trained models. In particular, approximate unlearning seeks to achieve information removal by strategically editing the model rather than complete model retraining. Recent work has shown that soft token attacks (STA) can successfully extract purportedly unlearned information from LLMs, thereby exposing limitations in current unlearning methodologies. In this work, we reveal that STAs are an inadequate tool for auditing unlearning. Through systematic evaluation on common unlearning benchmarks (Who Is Harry Potter? and TOFU), we demonstrate that such attacks can elicit any information from the LLM, regardless of (1) the deployed unlearning algorithm, and (2) whether the queried content was originally present in the training corpus. Furthermore, we show that STA with just a few soft tokens (1-10) can elicit random strings over 400-characters long. Thus showing that STAs are too powerful, and misrepresent the effectiveness of the unlearning methods. Our work highlights the need for better evaluation baselines, and more appropriate auditing tools for assessing the effectiveness of unlearning in LLMs.
Imperceptible Adversarial Examples in the Physical World
Nov 25, 2024



Adversarial examples in the digital domain against deep learning-based computer vision models allow for perturbations that are imperceptible to human eyes. However, producing similar adversarial examples in the physical world has been difficult due to the non-differentiable image distortion functions in visual sensing systems. The existing algorithms for generating physically realizable adversarial examples often loosen their definition of adversarial examples by allowing unbounded perturbations, resulting in obvious or even strange visual patterns. In this work, we make adversarial examples imperceptible in the physical world using a straight-through estimator (STE, a.k.a. BPDA). We employ STE to overcome the non-differentiability -- applying exact, non-differentiable distortions in the forward pass of the backpropagation step, and using the identity function in the backward pass. Our differentiable rendering extension to STE also enables imperceptible adversarial patches in the physical world. Using printout photos, and experiments in the CARLA simulator, we show that STE enables fast generation of $\ell_\infty$ bounded adversarial examples despite the non-differentiable distortions. To the best of our knowledge, this is the first work demonstrating imperceptible adversarial examples bounded by small $\ell_\infty$ norms in the physical world that force zero classification accuracy in the global perturbation threat model and cause near-zero ($4.22\%$) AP50 in object detection in the patch perturbation threat model. We urge the community to re-evaluate the threat of adversarial examples in the physical world.
SoK: Unintended Interactions among Machine Learning Defenses and Risks
Dec 07, 2023



Machine learning (ML) models cannot neglect risks to security, privacy, and fairness. Several defenses have been proposed to mitigate such risks. When a defense is effective in mitigating one risk, it may correspond to increased or decreased susceptibility to other risks. Existing research lacks an effective framework to recognize and explain these unintended interactions. We present such a framework, based on the conjecture that overfitting and memorization underlie unintended interactions. We survey existing literature on unintended interactions, accommodating them within our framework. We use our framework to conjecture on two previously unexplored interactions, and empirically validate our conjectures.
False Claims against Model Ownership Resolution
Apr 28, 2023Deep neural network (DNN) models are valuable intellectual property of model owners, constituting a competitive advantage. Therefore, it is crucial to develop techniques to protect against model theft. Model ownership resolution (MOR) is a class of techniques that can deter model theft. A MOR scheme enables an accuser to assert an ownership claim for a suspect model by presenting evidence, such as a watermark or fingerprint, to show that the suspect model was stolen or derived from a source model owned by the accuser. Most of the existing MOR schemes prioritize robustness against malicious suspects, ensuring that the accuser will win if the suspect model is indeed a stolen model. In this paper, we show that common MOR schemes in the literature are vulnerable to a different, equally important but insufficiently explored, robustness concern: a malicious accuser. We show how malicious accusers can successfully make false claims against independent suspect models that were not stolen. Our core idea is that a malicious accuser can deviate (without detection) from the specified MOR process by finding (transferable) adversarial examples that successfully serve as evidence against independent suspect models. To this end, we first generalize the procedures of common MOR schemes and show that, under this generalization, defending against false claims is as challenging as preventing (transferable) adversarial examples. Via systematic empirical evaluation we demonstrate that our false claim attacks always succeed in all prominent MOR schemes with realistic configurations, including against a real-world model: Amazon's Rekognition API.
On the Robustness of Dataset Inference
Oct 24, 2022
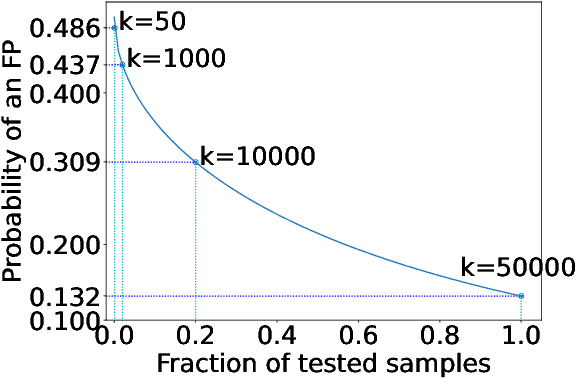
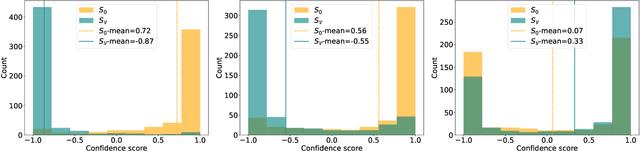

Machine learning (ML) models are costly to train as they can require a significant amount of data, computational resources and technical expertise. Thus, they constitute valuable intellectual property that needs protection from adversaries wanting to steal them. Ownership verification techniques allow the victims of model stealing attacks to demonstrate that a suspect model was in fact stolen from theirs. Although a number of ownership verification techniques based on watermarking or fingerprinting have been proposed, most of them fall short either in terms of security guarantees (well-equipped adversaries can evade verification) or computational cost. A fingerprinting technique introduced at ICLR '21, Dataset Inference (DI), has been shown to offer better robustness and efficiency than prior methods. The authors of DI provided a correctness proof for linear (suspect) models. However, in the same setting, we prove that DI suffers from high false positives (FPs) -- it can incorrectly identify an independent model trained with non-overlapping data from the same distribution as stolen. We further prove that DI also triggers FPs in realistic, non-linear suspect models. We then confirm empirically that DI leads to FPs, with high confidence. Second, we show that DI also suffers from false negatives (FNs) -- an adversary can fool DI by regularising a stolen model's decision boundaries using adversarial training, thereby leading to an FN. To this end, we demonstrate that DI fails to identify a model adversarially trained from a stolen dataset -- the setting where DI is the hardest to evade. Finally, we discuss the implications of our findings, the viability of fingerprinting-based ownership verification in general, and suggest directions for future work.
Conflicting Interactions Among Protections Mechanisms for Machine Learning Models
Jul 05, 2022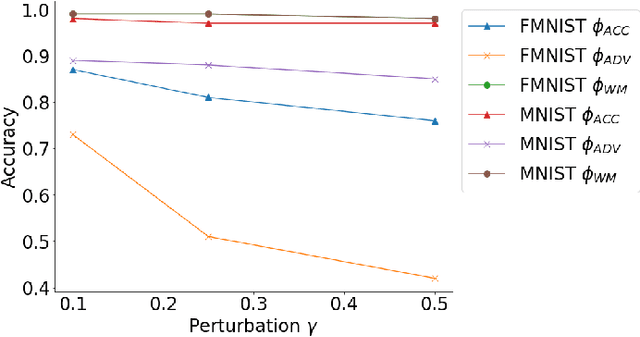
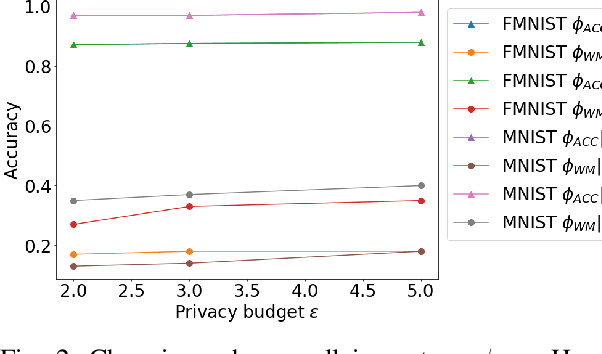
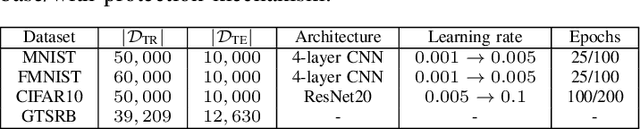

Nowadays, systems based on machine learning (ML) are widely used in different domains. Given their popularity, ML models have become targets for various attacks. As a result, research at the intersection of security and privacy, and ML has flourished. The research community has been exploring the attack vectors and potential mitigations separately. However, practitioners will likely need to deploy defences against several threats simultaneously. A solution that is optimal for a specific concern may interact negatively with solutions intended to address other concerns. In this work, we explore the potential for conflicting interactions between different solutions that enhance the security/privacy of ML-base systems. We focus on model and data ownership; exploring how ownership verification techniques interact with other ML security/privacy techniques like differentially private training, and robustness against model evasion. We provide a framework, and conduct systematic analysis of pairwise interactions. We show that many pairs are incompatible. Where possible, we provide relaxations to the hyperparameters or the techniques themselves that allow for the simultaneous deployment. Lastly, we discuss the implications and provide guidelines for future work.
SHAPr: An Efficient and Versatile Membership Privacy Risk Metric for Machine Learning
Dec 04, 2021
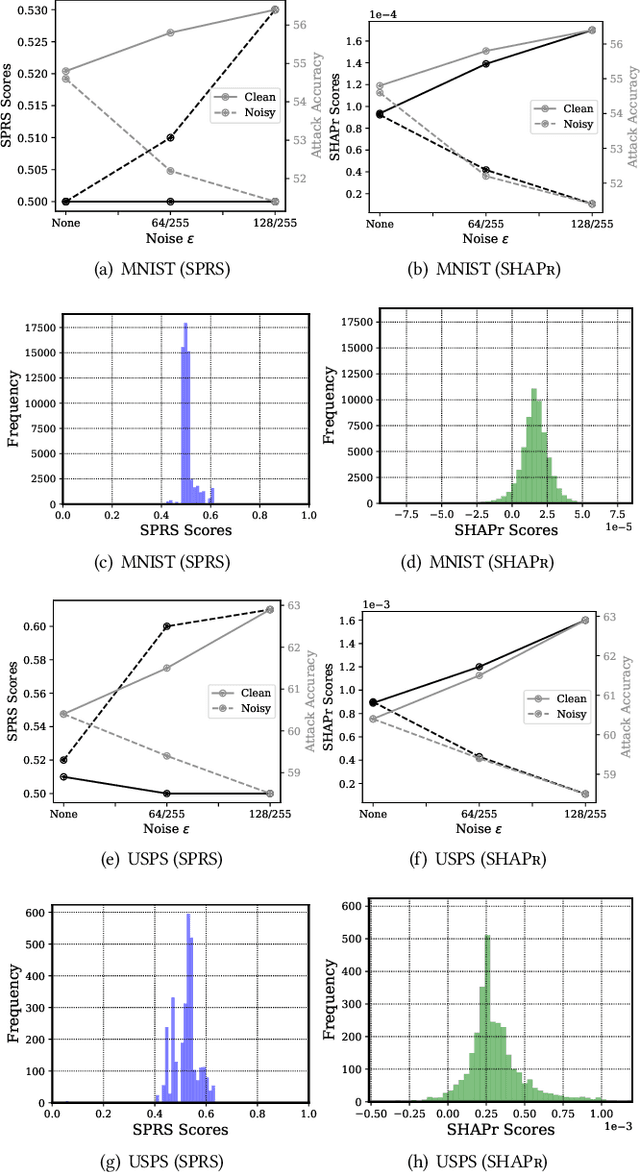
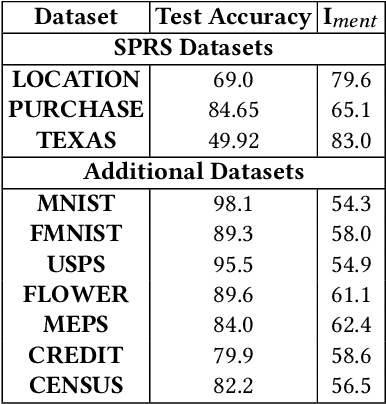

Data used to train machine learning (ML) models can be sensitive. Membership inference attacks (MIAs), attempting to determine whether a particular data record was used to train an ML model, risk violating membership privacy. ML model builders need a principled definition of a metric that enables them to quantify the privacy risk of (a) individual training data records, (b) independently of specific MIAs, (c) efficiently. None of the prior work on membership privacy risk metrics simultaneously meets all of these criteria. We propose such a metric, SHAPr, which uses Shapley values to quantify a model's memorization of an individual training data record by measuring its influence on the model's utility. This memorization is a measure of the likelihood of a successful MIA. Using ten benchmark datasets, we show that SHAPr is effective (precision: 0.94$\pm 0.06$, recall: 0.88$\pm 0.06$) in estimating susceptibility of a training data record for MIAs, and is efficient (computable within minutes for smaller datasets and in ~90 minutes for the largest dataset). SHAPr is also versatile in that it can be used for other purposes like assessing fairness or assigning valuation for subsets of a dataset. For example, we show that SHAPr correctly captures the disproportionate vulnerability of different subgroups to MIAs. Using SHAPr, we show that the membership privacy risk of a dataset is not necessarily improved by removing high risk training data records, thereby confirming an observation from prior work in a significantly extended setting (in ten datasets, removing up to 50% of data).
Good Artists Copy, Great Artists Steal: Model Extraction Attacks Against Image Translation Generative Adversarial Networks
Apr 26, 2021


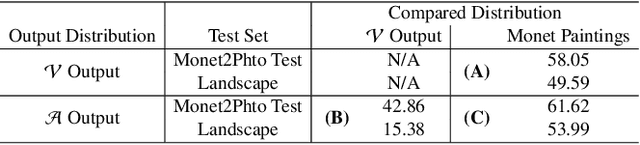
Machine learning models are typically made available to potential client users via inference APIs. Model extraction attacks occur when a malicious client uses information gleaned from queries to the inference API of a victim model $F_V$ to build a surrogate model $F_A$ that has comparable functionality. Recent research has shown successful model extraction attacks against image classification, and NLP models. In this paper, we show the first model extraction attack against real-world generative adversarial network (GAN) image translation models. We present a framework for conducting model extraction attacks against image translation models, and show that the adversary can successfully extract functional surrogate models. The adversary is not required to know $F_V$'s architecture or any other information about it beyond its intended image translation task, and queries $F_V$'s inference interface using data drawn from the same domain as the training data for $F_V$. We evaluate the effectiveness of our attacks using three different instances of two popular categories of image translation: (1) Selfie-to-Anime and (2) Monet-to-Photo (image style transfer), and (3) Super-Resolution (super resolution). Using standard performance metrics for GANs, we show that our attacks are effective in each of the three cases -- the differences between $F_V$ and $F_A$, compared to the target are in the following ranges: Selfie-to-Anime: FID $13.36-68.66$, Monet-to-Photo: FID $3.57-4.40$, and Super-Resolution: SSIM: $0.06-0.08$ and PSNR: $1.43-4.46$. Furthermore, we conducted a large scale (125 participants) user study on Selfie-to-Anime and Monet-to-Photo to show that human perception of the images produced by the victim and surrogate models can be considered equivalent, within an equivalence bound of Cohen's $d=0.3$.