 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmulet: a Python Library for Assessing Interactions Among ML Defenses and Risks
Sep 15, 2025
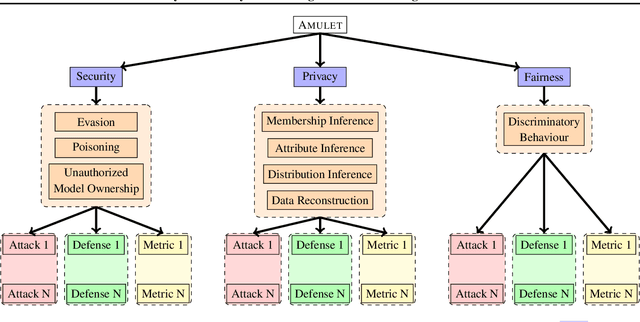
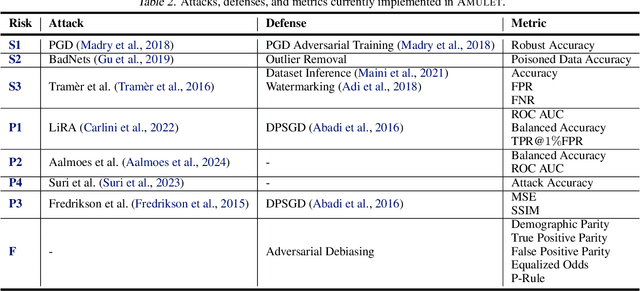
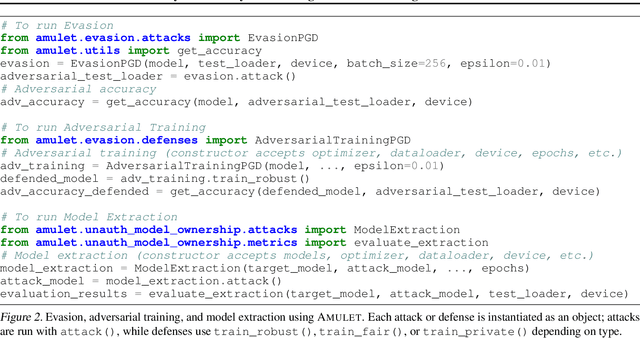
ML models are susceptible to risks to security, privacy, and fairness. Several defenses are designed to protect against their intended risks, but can inadvertently affect susceptibility to other unrelated risks, known as unintended interactions. Several jurisdictions are preparing ML regulatory frameworks that require ML practitioners to assess the susceptibility of ML models to different risks. A library for valuating unintended interactions that can be used by (a) practitioners to evaluate unintended interactions at scale prior to model deployment and (b) researchers to design defenses which do not suffer from an unintended increase in unrelated risks. Ideally, such a library should be i) comprehensive by including representative attacks, defenses and metrics for different risks, ii) extensible to new modules due to its modular design, iii) consistent with a user-friendly API template for inputs and outputs, iv) applicable to evaluate previously unexplored unintended interactions. We present AMULET, a Python library that covers risks to security, privacy, and fairness, which satisfies all these requirements. AMULET can be used to evaluate unexplored unintended interactions, compare effectiveness between defenses or attacks, and include new attacks and defenses.
Do Concept Replacement Techniques Really Erase Unacceptable Concepts?
Jun 10, 2025
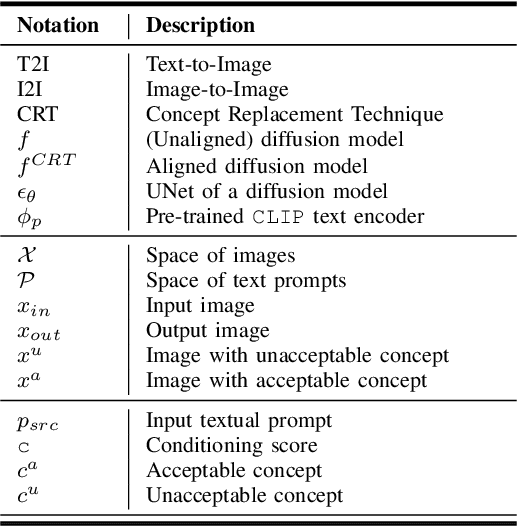
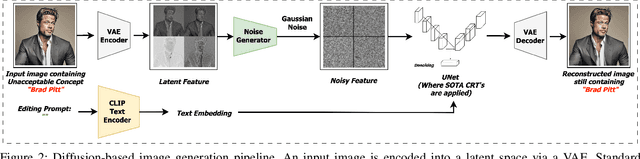
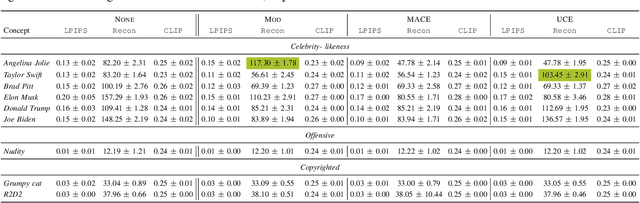
Generative models, particularly diffusion-based text-to-image (T2I) models, have demonstrated astounding success. However, aligning them to avoid generating content with unacceptable concepts (e.g., offensive or copyrighted content, or celebrity likenesses) remains a significant challenge. Concept replacement techniques (CRTs) aim to address this challenge, often by trying to "erase" unacceptable concepts from models. Recently, model providers have started offering image editing services which accept an image and a text prompt as input, to produce an image altered as specified by the prompt. These are known as image-to-image (I2I) models. In this paper, we first use an I2I model to empirically demonstrate that today's state-of-the-art CRTs do not in fact erase unacceptable concepts. Existing CRTs are thus likely to be ineffective in emerging I2I scenarios, despite their proven ability to remove unwanted concepts in T2I pipelines, highlighting the need to understand this discrepancy between T2I and I2I settings. Next, we argue that a good CRT, while replacing unacceptable concepts, should preserve other concepts specified in the inputs to generative models. We call this fidelity. Prior work on CRTs have neglected fidelity in the case of unacceptable concepts. Finally, we propose the use of targeted image-editing techniques to achieve both effectiveness and fidelity. We present such a technique, AntiMirror, and demonstrate its viability.
Combining Machine Learning Defenses without Conflicts
Nov 14, 2024



Machine learning (ML) defenses protect against various risks to security, privacy, and fairness. Real-life models need simultaneous protection against multiple different risks which necessitates combining multiple defenses. But combining defenses with conflicting interactions in an ML model can be ineffective, incurring a significant drop in the effectiveness of one or more defenses being combined. Practitioners need a way to determine if a given combination can be effective. Experimentally identifying effective combinations can be time-consuming and expensive, particularly when multiple defenses need to be combined. We need an inexpensive, easy-to-use combination technique to identify effective combinations. Ideally, a combination technique should be (a) accurate (correctly identifies whether a combination is effective or not), (b) scalable (allows combining multiple defenses), (c) non-invasive (requires no change to the defenses being combined), and (d) general (is applicable to different types of defenses). Prior works have identified several ad-hoc techniques but none satisfy all the requirements above. We propose a principled combination technique, Def\Con, to identify effective defense combinations. Def\Con meets all requirements, achieving 90% accuracy on eight combinations explored in prior work and 81% in 30 previously unexplored combinations that we empirically evaluate in this paper.
Espresso: Robust Concept Filtering in Text-to-Image Models
May 01, 2024



Diffusion-based text-to-image (T2I) models generate high-fidelity images for given textual prompts. They are trained on large datasets scraped from the Internet, potentially containing unacceptable concepts (e.g., copyright infringing or unsafe). Retraining T2I models after filtering out unacceptable concepts in the training data is inefficient and degrades utility. Hence, there is a need for concept removal techniques (CRTs) which are effective in removing unacceptable concepts, utility-preserving on acceptable concepts, and robust against evasion with adversarial prompts. None of the prior filtering and fine-tuning CRTs satisfy all these requirements simultaneously. We introduce Espresso, the first robust concept filter based on Contrastive Language-Image Pre-Training (CLIP). It identifies unacceptable concepts by projecting the generated image's embedding onto the vector connecting unacceptable and acceptable concepts in the joint text-image embedding space. This ensures robustness by restricting the adversary to adding noise only along this vector, in the direction of the acceptable concept. Further fine-tuning Espresso to separate embeddings of acceptable and unacceptable concepts, while preserving their pairing with image embeddings, ensures both effectiveness and utility. We evaluate Espresso on eleven concepts to show that it is effective (~5% CLIP accuracy on unacceptable concepts), utility-preserving (~93% normalized CLIP score on acceptable concepts), and robust (~4% CLIP accuracy on adversarial prompts for unacceptable concepts). Finally, we present theoretical bounds for the certified robustness of Espresso against adversarial prompts, and an empirical analysis.
SoK: Unintended Interactions among Machine Learning Defenses and Risks
Dec 07, 2023



Machine learning (ML) models cannot neglect risks to security, privacy, and fairness. Several defenses have been proposed to mitigate such risks. When a defense is effective in mitigating one risk, it may correspond to increased or decreased susceptibility to other risks. Existing research lacks an effective framework to recognize and explain these unintended interactions. We present such a framework, based on the conjecture that overfitting and memorization underlie unintended interactions. We survey existing literature on unintended interactions, accommodating them within our framework. We use our framework to conjecture on two previously unexplored interactions, and empirically validate our conjectures.
Attesting Distributional Properties of Training Data for Machine Learning
Aug 18, 2023



The success of machine learning (ML) has been accompanied by increased concerns about its trustworthiness. Several jurisdictions are preparing ML regulatory frameworks. One such concern is ensuring that model training data has desirable distributional properties for certain sensitive attributes. For example, draft regulations indicate that model trainers are required to show that training datasets have specific distributional properties, such as reflecting diversity of the population. We propose the notion of property attestation allowing a prover (e.g., model trainer) to demonstrate relevant distributional properties of training data to a verifier (e.g., a customer) without revealing the data. We present an effective hybrid property attestation combining property inference with cryptographic mechanisms.
FLARE: Fingerprinting Deep Reinforcement Learning Agents using Universal Adversarial Masks
Jul 27, 2023We propose FLARE, the first fingerprinting mechanism to verify whether a suspected Deep Reinforcement Learning (DRL) policy is an illegitimate copy of another (victim) policy. We first show that it is possible to find non-transferable, universal adversarial masks, i.e., perturbations, to generate adversarial examples that can successfully transfer from a victim policy to its modified versions but not to independently trained policies. FLARE employs these masks as fingerprints to verify the true ownership of stolen DRL policies by measuring an action agreement value over states perturbed via such masks. Our empirical evaluations show that FLARE is effective (100% action agreement on stolen copies) and does not falsely accuse independent policies (no false positives). FLARE is also robust to model modification attacks and cannot be easily evaded by more informed adversaries without negatively impacting agent performance. We also show that not all universal adversarial masks are suitable candidates for fingerprints due to the inherent characteristics of DRL policies. The spatio-temporal dynamics of DRL problems and sequential decision-making process make characterizing the decision boundary of DRL policies more difficult, as well as searching for universal masks that capture the geometry of it.
False Claims against Model Ownership Resolution
Apr 28, 2023Deep neural network (DNN) models are valuable intellectual property of model owners, constituting a competitive advantage. Therefore, it is crucial to develop techniques to protect against model theft. Model ownership resolution (MOR) is a class of techniques that can deter model theft. A MOR scheme enables an accuser to assert an ownership claim for a suspect model by presenting evidence, such as a watermark or fingerprint, to show that the suspect model was stolen or derived from a source model owned by the accuser. Most of the existing MOR schemes prioritize robustness against malicious suspects, ensuring that the accuser will win if the suspect model is indeed a stolen model. In this paper, we show that common MOR schemes in the literature are vulnerable to a different, equally important but insufficiently explored, robustness concern: a malicious accuser. We show how malicious accusers can successfully make false claims against independent suspect models that were not stolen. Our core idea is that a malicious accuser can deviate (without detection) from the specified MOR process by finding (transferable) adversarial examples that successfully serve as evidence against independent suspect models. To this end, we first generalize the procedures of common MOR schemes and show that, under this generalization, defending against false claims is as challenging as preventing (transferable) adversarial examples. Via systematic empirical evaluation we demonstrate that our false claim attacks always succeed in all prominent MOR schemes with realistic configurations, including against a real-world model: Amazon's Rekognition API.
GrOVe: Ownership Verification of Graph Neural Networks using Embeddings
Apr 17, 2023



Graph neural networks (GNNs) have emerged as a state-of-the-art approach to model and draw inferences from large scale graph-structured data in various application settings such as social networking. The primary goal of a GNN is to learn an embedding for each graph node in a dataset that encodes both the node features and the local graph structure around the node. Embeddings generated by a GNN for a graph node are unique to that GNN. Prior work has shown that GNNs are prone to model extraction attacks. Model extraction attacks and defenses have been explored extensively in other non-graph settings. While detecting or preventing model extraction appears to be difficult, deterring them via effective ownership verification techniques offer a potential defense. In non-graph settings, fingerprinting models, or the data used to build them, have shown to be a promising approach toward ownership verification. We present GrOVe, a state-of-the-art GNN model fingerprinting scheme that, given a target model and a suspect model, can reliably determine if the suspect model was trained independently of the target model or if it is a surrogate of the target model obtained via model extraction. We show that GrOVe can distinguish between surrogate and independent models even when the independent model uses the same training dataset and architecture as the original target model. Using six benchmark datasets and three model architectures, we show that consistently achieves low false-positive and false-negative rates. We demonstrate that is robust against known fingerprint evasion techniques while remaining computationally efficient.
On the Robustness of Dataset Inference
Oct 24, 2022
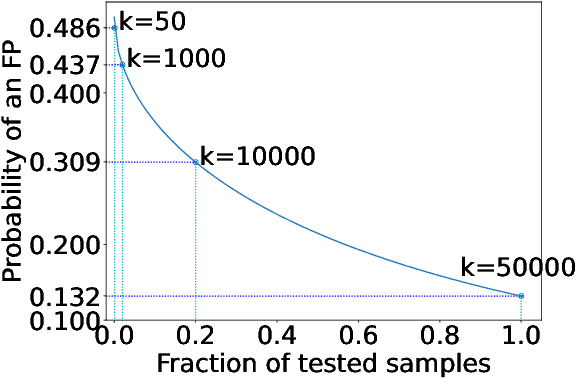
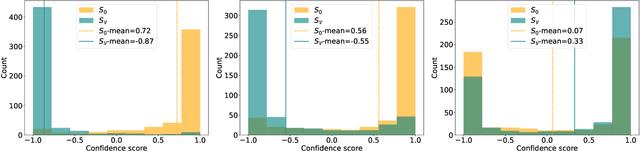

Machine learning (ML) models are costly to train as they can require a significant amount of data, computational resources and technical expertise. Thus, they constitute valuable intellectual property that needs protection from adversaries wanting to steal them. Ownership verification techniques allow the victims of model stealing attacks to demonstrate that a suspect model was in fact stolen from theirs. Although a number of ownership verification techniques based on watermarking or fingerprinting have been proposed, most of them fall short either in terms of security guarantees (well-equipped adversaries can evade verification) or computational cost. A fingerprinting technique introduced at ICLR '21, Dataset Inference (DI), has been shown to offer better robustness and efficiency than prior methods. The authors of DI provided a correctness proof for linear (suspect) models. However, in the same setting, we prove that DI suffers from high false positives (FPs) -- it can incorrectly identify an independent model trained with non-overlapping data from the same distribution as stolen. We further prove that DI also triggers FPs in realistic, non-linear suspect models. We then confirm empirically that DI leads to FPs, with high confidence. Second, we show that DI also suffers from false negatives (FNs) -- an adversary can fool DI by regularising a stolen model's decision boundaries using adversarial training, thereby leading to an FN. To this end, we demonstrate that DI fails to identify a model adversarially trained from a stolen dataset -- the setting where DI is the hardest to evade. Finally, we discuss the implications of our findings, the viability of fingerprinting-based ownership verification in general, and suggest directions for future work.