 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLARE: Fingerprinting Deep Reinforcement Learning Agents using Universal Adversarial Masks
Jul 27, 2023We propose FLARE, the first fingerprinting mechanism to verify whether a suspected Deep Reinforcement Learning (DRL) policy is an illegitimate copy of another (victim) policy. We first show that it is possible to find non-transferable, universal adversarial masks, i.e., perturbations, to generate adversarial examples that can successfully transfer from a victim policy to its modified versions but not to independently trained policies. FLARE employs these masks as fingerprints to verify the true ownership of stolen DRL policies by measuring an action agreement value over states perturbed via such masks. Our empirical evaluations show that FLARE is effective (100% action agreement on stolen copies) and does not falsely accuse independent policies (no false positives). FLARE is also robust to model modification attacks and cannot be easily evaded by more informed adversaries without negatively impacting agent performance. We also show that not all universal adversarial masks are suitable candidates for fingerprints due to the inherent characteristics of DRL policies. The spatio-temporal dynamics of DRL problems and sequential decision-making process make characterizing the decision boundary of DRL policies more difficult, as well as searching for universal masks that capture the geometry of it.
Real-time Attacks Against Deep Reinforcement Learning Policies
Jun 16, 2021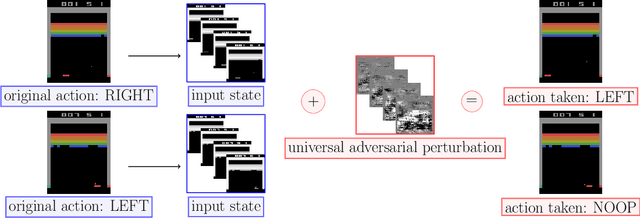
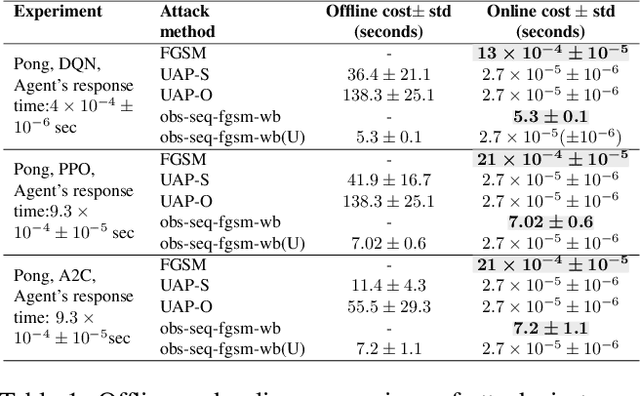
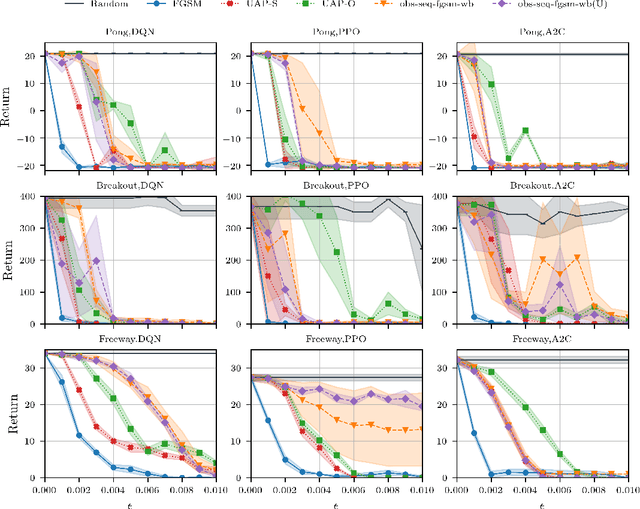

Recent work has discovered that deep reinforcement learning (DRL) policies are vulnerable to adversarial examples. These attacks mislead the policy of DRL agents by perturbing the state of the environment observed by agents. They are feasible in principle but too slow to fool DRL policies in real time. We propose a new attack to fool DRL policies that is both effective and efficient enough to be mounted in real time. We utilize the Universal Adversarial Perturbation (UAP) method to compute effective perturbations independent of the individual inputs to which they are applied. Via an extensive evaluation using Atari 2600 games, we show that our technique is effective, as it fully degrades the performance of both deterministic and stochastic policies (up to 100%, even when the $l_\infty$ bound on the perturbation is as small as 0.005). We also show that our attack is efficient, incurring an online computational cost of 0.027ms on average. It is faster compared to the response time (0.6ms on average) of agents with different DRL policies, and considerably faster than prior attacks (2.7ms on average). Furthermore, we demonstrate that known defenses are ineffective against universal perturbations. We propose an effective detection technique which can form the basis for robust defenses against attacks based on universal perturbations.