 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on XAI for Beyond 5G Security: Technical Aspects, Use Cases, Challenges and Research Directions
Apr 27, 2022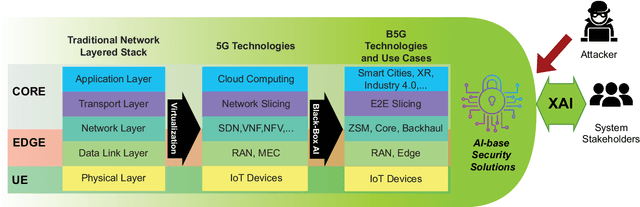
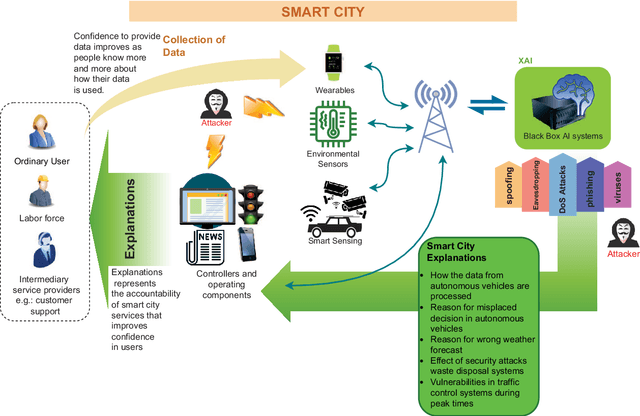
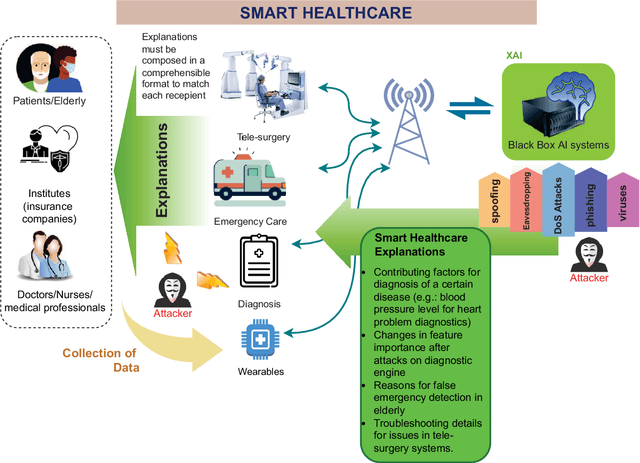
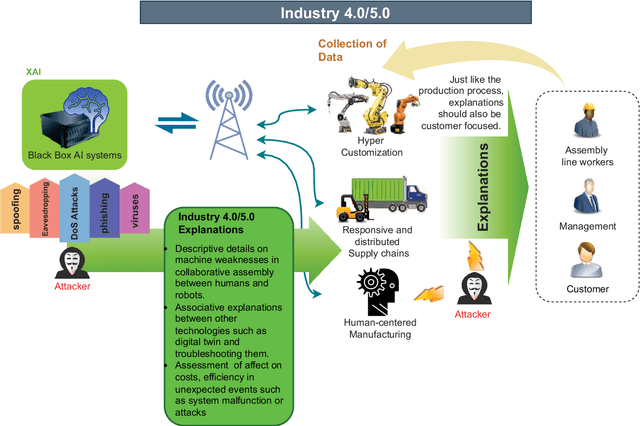
With the advent of 5G commercialization, the need for more reliable, faster, and intelligent telecommunication systems are envisaged for the next generation beyond 5G (B5G) radio access technologies. Artificial Intelligence (AI) and Machine Learning (ML) are not just immensely popular in the service layer applications but also have been proposed as essential enablers in many aspects of B5G networks, from IoT devices and edge computing to cloud-based infrastructures. However, most of the existing surveys in B5G security focus on the performance of AI/ML models and their accuracy, but they often overlook the accountability and trustworthiness of the models' decisions. Explainable AI (XAI) methods are promising techniques that would allow system developers to identify the internal workings of AI/ML black-box models. The goal of using XAI in the security domain of B5G is to allow the decision-making processes of the security of systems to be transparent and comprehensible to stakeholders making the systems accountable for automated actions. In every facet of the forthcoming B5G era, including B5G technologies such as RAN, zero-touch network management, E2E slicing, this survey emphasizes the role of XAI in them and the use cases that the general users would ultimately enjoy. Furthermore, we presented the lessons learned from recent efforts and future research directions on top of the currently conducted projects involving XAI.
Real-time Attacks Against Deep Reinforcement Learning Policies
Jun 16, 2021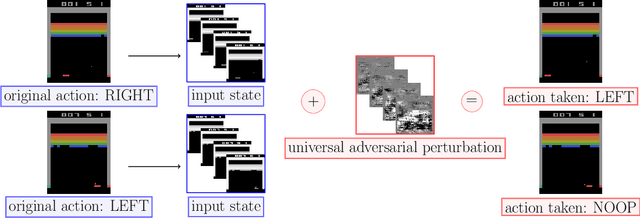
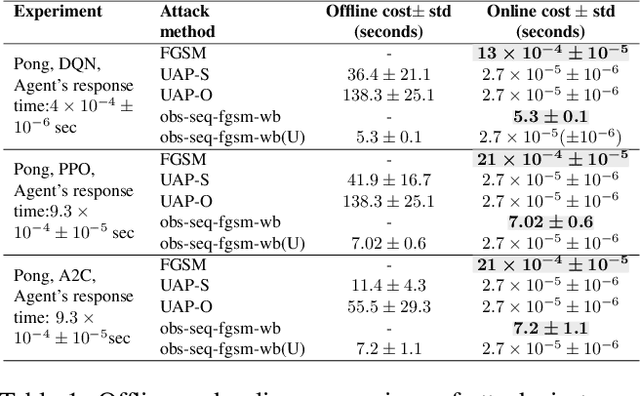
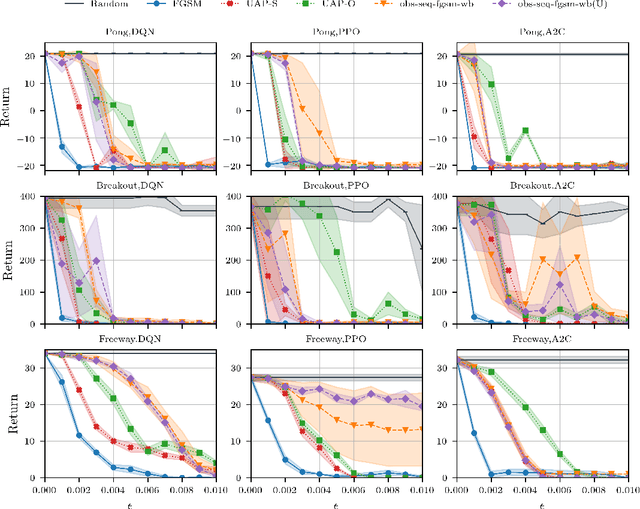

Recent work has discovered that deep reinforcement learning (DRL) policies are vulnerable to adversarial examples. These attacks mislead the policy of DRL agents by perturbing the state of the environment observed by agents. They are feasible in principle but too slow to fool DRL policies in real time. We propose a new attack to fool DRL policies that is both effective and efficient enough to be mounted in real time. We utilize the Universal Adversarial Perturbation (UAP) method to compute effective perturbations independent of the individual inputs to which they are applied. Via an extensive evaluation using Atari 2600 games, we show that our technique is effective, as it fully degrades the performance of both deterministic and stochastic policies (up to 100%, even when the $l_\infty$ bound on the perturbation is as small as 0.005). We also show that our attack is efficient, incurring an online computational cost of 0.027ms on average. It is faster compared to the response time (0.6ms on average) of agents with different DRL policies, and considerably faster than prior attacks (2.7ms on average). Furthermore, we demonstrate that known defenses are ineffective against universal perturbations. We propose an effective detection technique which can form the basis for robust defenses against attacks based on universal perturbations.
WAFFLE: Watermarking in Federated Learning
Aug 17, 2020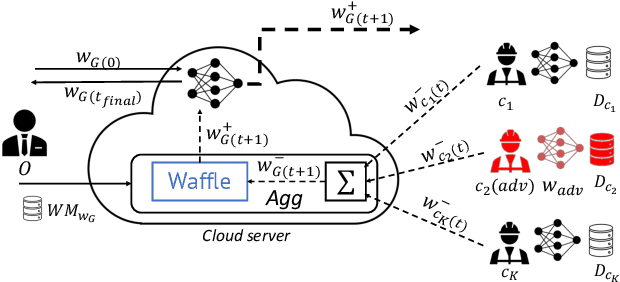


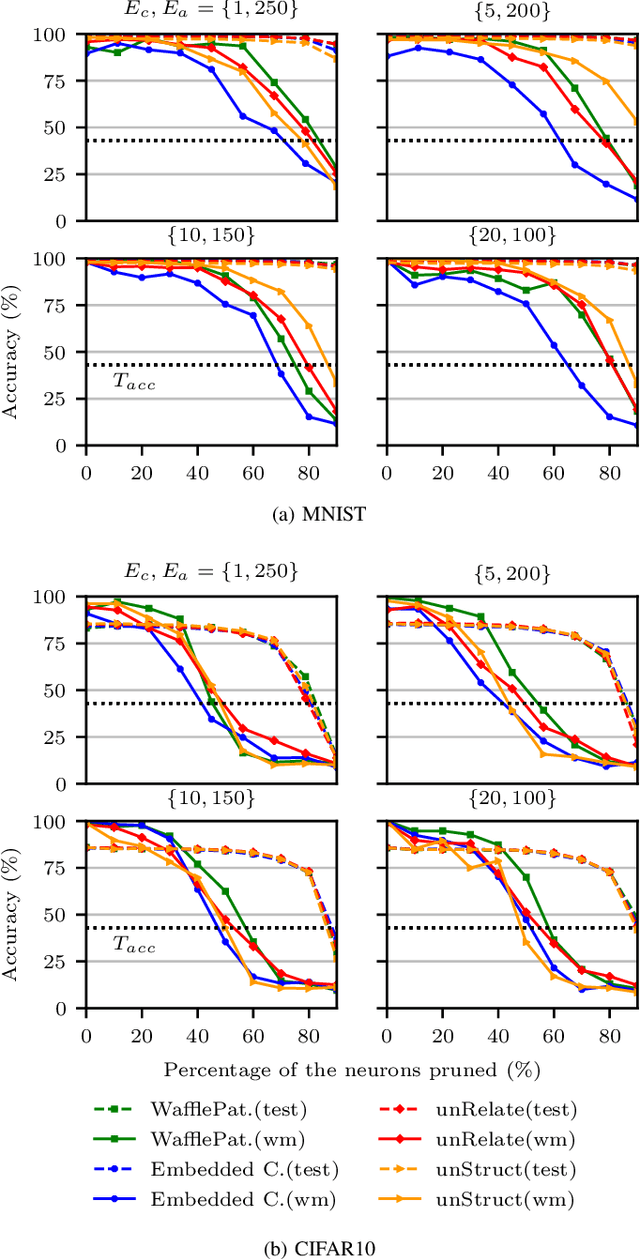
Creators of machine learning models can use watermarking as a technique to demonstrate their ownership if their models are stolen. Several recent proposals watermark deep neural network (DNN) models using backdooring: training them with additional mislabeled data. Backdooring requires full access to the training data and control of the training process. This is feasible when a single party trains the model in a centralized manner, but not in a federated learning setting where the training process and training data are distributed among several parties. In this paper, we introduce WAFFLE, the first approach to watermark DNN models in federated learning. It introduces a re-training step after each aggregation of local models into the global model. We show that WAFFLE efficiently embeds a resilient watermark into models with a negligible test accuracy degradation (-0.17%), and does not require access to the training data. We introduce a novel technique to generate the backdoor used as a watermark. It outperforms prior techniques, imposing no communication, and low computational(+2.8%) overhead.
Extraction of Complex DNN Models: Real Threat or Boogeyman?
Oct 11, 2019

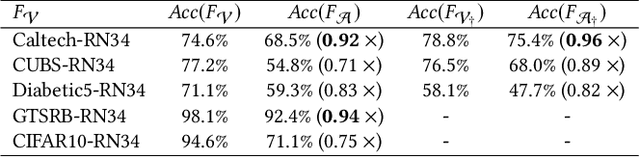
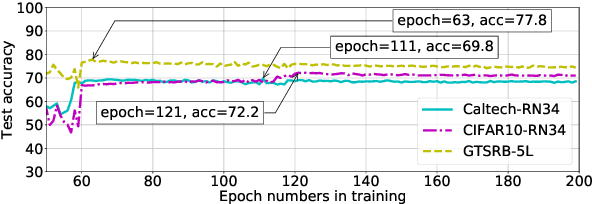
Recently, machine learning (ML) has introduced advanced solutions to many domains. Since ML models provide business advantage to model owners, protecting intellectual property (IP) of ML models has emerged as an important consideration. Confidentiality of ML models can be protected by exposing them to clients only via prediction APIs. However, model extraction attacks can steal the functionality of ML models using the information leaked to clients through the results returned via the API. In this work, we question whether model extraction is a serious threat to complex, real-life ML models. We evaluate the current state-of-the-art model extraction attack (the Knockoff attack) against complex models. We reproduced and confirm the results in the Knockoff attack paper. But we also show that the performance of this attack can be limited by several factors, including ML model architecture and the granularity of API response. Furthermore, we introduce a defense based on distinguishing queries used for Knockoff attack from benign queries. Despite the limitations of the Knockoff attack, we show that a more realistic adversary can effectively steal complex ML models and evade known defenses.
Detecting organized eCommerce fraud using scalable categorical clustering
Oct 10, 2019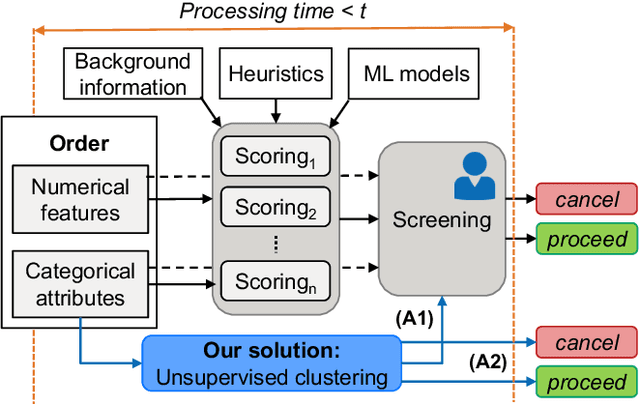

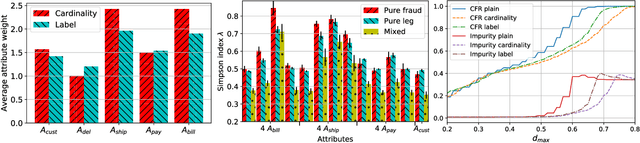
Online retail, eCommerce, frequently falls victim to fraud conducted by malicious customers (fraudsters) who obtain goods or services through deception. Fraud coordinated by groups of professional fraudsters that place several fraudulent orders to maximize their gain is referred to as organized fraud. Existing approaches to fraud detection typically analyze orders in isolation and they are not effective at identifying groups of fraudulent orders linked to organized fraud. These also wrongly identify many legitimate orders as fraud, which hinders their usage for automated fraud cancellation. We introduce a novel solution to detect organized fraud by analyzing orders in bulk. Our approach is based on clustering and aims to group together fraudulent orders placed by the same group of fraudsters. It selectively uses two existing techniques, agglomerative clustering and sampling to recursively group orders into small clusters in a reasonable amount of time. We assess our clustering technique on real-world orders placed on the Zalando website, the largest online apparel retailer in Europe1. Our clustering processes 100,000s of orders in a few hours and groups 35-45% of fraudulent orders together. We propose a simple technique built on top of our clustering that detects 26.2% of fraud while raising false alarms for only 0.1% of legitimate orders.
DAWN: Dynamic Adversarial Watermarking of Neural Networks
Jun 12, 2019
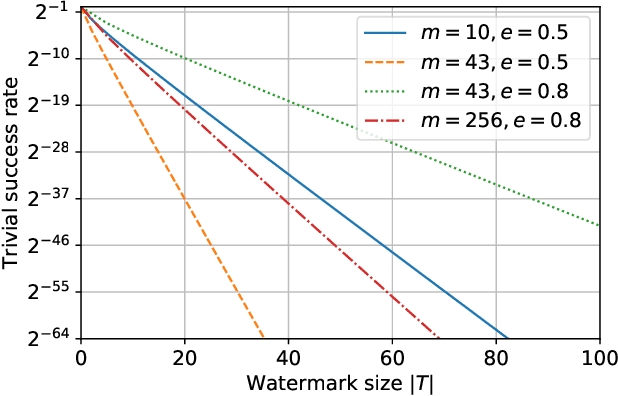
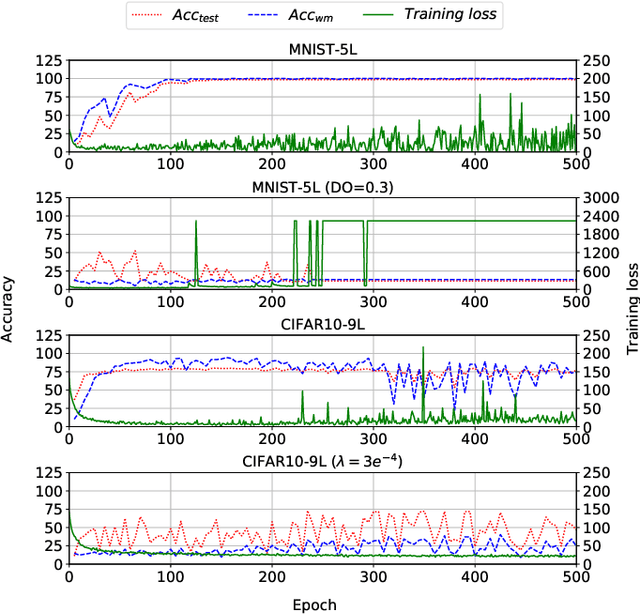
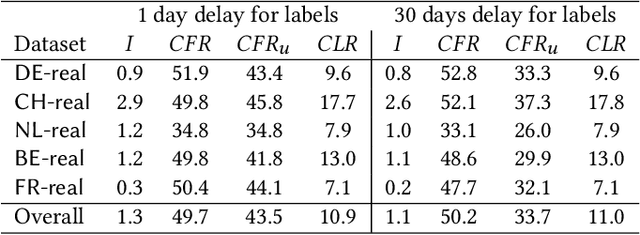
Training machine learning (ML) models is expensive in terms of computational power, large amounts of labeled data, and human expertise. Thus, ML models constitute intellectual property (IP) and business value for their owners. Embedding digital watermarks during model training allows a model owner to later identify their models in case of theft or misuse. However, model functionality can also be stolen via model extraction, where an adversary trains a surrogate model using results returned from a prediction API of the original model. Recent work has shown that model extraction is a realistic threat. Existing watermarking schemes are ineffective against IP theft via model extraction since it is the adversary who trains the surrogate model. In this paper, we introduce DAWN (Dynamic Adversarial Watermarking of Neural Networks), the first approach to use watermarking to deter IP theft via model extraction. Unlike prior watermarking schemes, DAWN does not impose changes to the training process. Instead, it operates at the prediction API of the protected model, by dynamically changing the responses for a small subset of queries (e.g. $<0.5\%$) from API clients. This set represents a watermark that will be embedded in case a client uses its queries to train a surrogate model. We show that DAWN is resilient against two state-of-the-art model extraction attacks, effectively watermarking all extracted surrogate models, allowing model owners to reliably demonstrate ownership (with confidence $>1-2^{-64}$), incurring negligible loss of prediction accuracy ($0.03-0.5\%$).