 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluential Training Data Retrieval for Explaining Verbalized Confidence of LLMs
Jan 15, 2026Large language models (LLMs) can increase users' perceived trust by verbalizing confidence in their outputs. However, prior work has shown that LLMs are often overconfident, making their stated confidence unreliable since it does not consistently align with factual accuracy. To better understand the sources of this verbalized confidence, we introduce TracVC (\textbf{Trac}ing \textbf{V}erbalized \textbf{C}onfidence), a method that builds on information retrieval and influence estimation to trace generated confidence expressions back to the training data. We evaluate TracVC on OLMo and Llama models in a question answering setting, proposing a new metric, content groundness, which measures the extent to which an LLM grounds its confidence in content-related training examples (relevant to the question and answer) versus in generic examples of confidence verbalization. Our analysis reveals that OLMo2-13B is frequently influenced by confidence-related data that is lexically unrelated to the query, suggesting that it may mimic superficial linguistic expressions of certainty rather than rely on genuine content grounding. These findings point to a fundamental limitation in current training regimes: LLMs may learn how to sound confident without learning when confidence is justified. Our analysis provides a foundation for improving LLMs' trustworthiness in expressing more reliable confidence.
Explaining Generalization of AI-Generated Text Detectors Through Linguistic Analysis
Jan 12, 2026AI-text detectors achieve high accuracy on in-domain benchmarks, but often struggle to generalize across different generation conditions such as unseen prompts, model families, or domains. While prior work has reported these generalization gaps, there are limited insights about the underlying causes. In this work, we present a systematic study aimed at explaining generalization behavior through linguistic analysis. We construct a comprehensive benchmark that spans 6 prompting strategies, 7 large language models (LLMs), and 4 domain datasets, resulting in a diverse set of human- and AI-generated texts. Using this dataset, we fine-tune classification-based detectors on various generation settings and evaluate their cross-prompt, cross-model, and cross-dataset generalization. To explain the performance variance, we compute correlations between generalization accuracies and feature shifts of 80 linguistic features between training and test conditions. Our analysis reveals that generalization performance for specific detectors and evaluation conditions is significantly associated with linguistic features such as tense usage and pronoun frequency.
Calibration Is Not Enough: Evaluating Confidence Estimation Under Language Variations
Jan 12, 2026Confidence estimation (CE) indicates how reliable the answers of large language models (LLMs) are, and can impact user trust and decision-making. Existing work evaluates CE methods almost exclusively through calibration, examining whether stated confidence aligns with accuracy, or discrimination, whether confidence is ranked higher for correct predictions than incorrect ones. However, these facets ignore pitfalls of CE in the context of LLMs and language variation: confidence estimates should remain consistent under semantically equivalent prompt or answer variations, and should change when the answer meaning differs. Therefore, we present a comprehensive evaluation framework for CE that measures their confidence quality on three new aspects: robustness of confidence against prompt perturbations, stability across semantic equivalent answers, and sensitivity to semantically different answers. In our work, we demonstrate that common CE methods for LLMs often fail on these metrics: methods that achieve good performance on calibration or discrimination are not robust to prompt variations or are not sensitive to answer changes. Overall, our framework reveals limitations of existing CE evaluations relevant for real-world LLM use cases and provides practical guidance for selecting and designing more reliable CE methods.
Influences on LLM Calibration: A Study of Response Agreement, Loss Functions, and Prompt Styles
Jan 07, 2025Calibration, the alignment between model confidence and prediction accuracy, is critical for the reliable deployment of large language models (LLMs). Existing works neglect to measure the generalization of their methods to other prompt styles and different sizes of LLMs. To address this, we define a controlled experimental setting covering 12 LLMs and four prompt styles. We additionally investigate if incorporating the response agreement of multiple LLMs and an appropriate loss function can improve calibration performance. Concretely, we build Calib-n, a novel framework that trains an auxiliary model for confidence estimation that aggregates responses from multiple LLMs to capture inter-model agreement. To optimize calibration, we integrate focal and AUC surrogate losses alongside binary cross-entropy. Experiments across four datasets demonstrate that both response agreement and focal loss improve calibration from baselines. We find that few-shot prompts are the most effective for auxiliary model-based methods, and auxiliary models demonstrate robust calibration performance across accuracy variations, outperforming LLMs' internal probabilities and verbalized confidences. These insights deepen the understanding of influence factors in LLM calibration, supporting their reliable deployment in diverse applications.
An Evaluation of Explanation Methods for Black-Box Detectors of Machine-Generated Text
Aug 26, 2024The increasing difficulty to distinguish language-model-generated from human-written text has led to the development of detectors of machine-generated text (MGT). However, in many contexts, a black-box prediction is not sufficient, it is equally important to know on what grounds a detector made that prediction. Explanation methods that estimate feature importance promise to provide indications of which parts of an input are used by classifiers for prediction. However, the quality of different explanation methods has not previously been assessed for detectors of MGT. This study conducts the first systematic evaluation of explanation quality for this task. The dimensions of faithfulness and stability are assessed with five automated experiments, and usefulness is evaluated in a user study. We use a dataset of ChatGPT-generated and human-written documents, and pair predictions of three existing language-model-based detectors with the corresponding SHAP, LIME, and Anchor explanations. We find that SHAP performs best in terms of faithfulness, stability, and in helping users to predict the detector's behavior. In contrast, LIME, perceived as most useful by users, scores the worst in terms of user performance at predicting the detectors' behavior.
Exploring prompts to elicit memorization in masked language model-based named entity recognition
May 05, 2024Training data memorization in language models impacts model capability (generalization) and safety (privacy risk). This paper focuses on analyzing prompts' impact on detecting the memorization of 6 masked language model-based named entity recognition models. Specifically, we employ a diverse set of 400 automatically generated prompts, and a pairwise dataset where each pair consists of one person's name from the training set and another name out of the set. A prompt completed with a person's name serves as input for getting the model's confidence in predicting this name. Finally, the prompt performance of detecting model memorization is quantified by the percentage of name pairs for which the model has higher confidence for the name from the training set. We show that the performance of different prompts varies by as much as 16 percentage points on the same model, and prompt engineering further increases the gap. Moreover, our experiments demonstrate that prompt performance is model-dependent but does generalize across different name sets. A comprehensive analysis indicates how prompt performance is influenced by prompt properties, contained tokens, and the model's self-attention weights on the prompt.
Specification Overfitting in Artificial Intelligence
Mar 13, 2024Machine learning (ML) and artificial intelligence (AI) approaches are often criticized for their inherent bias and for their lack of control, accountability, and transparency. Consequently, regulatory bodies struggle with containing this technology's potential negative side effects. High-level requirements such as fairness and robustness need to be formalized into concrete specification metrics, imperfect proxies that capture isolated aspects of the underlying requirements. Given possible trade-offs between different metrics and their vulnerability to over-optimization, integrating specification metrics in system development processes is not trivial. This paper defines specification overfitting, a scenario where systems focus excessively on specified metrics to the detriment of high-level requirements and task performance. We present an extensive literature survey to categorize how researchers propose, measure, and optimize specification metrics in several AI fields (e.g., natural language processing, computer vision, reinforcement learning). Using a keyword-based search on papers from major AI conferences and journals between 2018 and mid-2023, we identify and analyze 74 papers that propose or optimize specification metrics. We find that although most papers implicitly address specification overfitting (e.g., by reporting more than one specification metric), they rarely discuss which role specification metrics should play in system development or explicitly define the scope and assumptions behind metric formulations.
WAFFLE: Watermarking in Federated Learning
Aug 17, 2020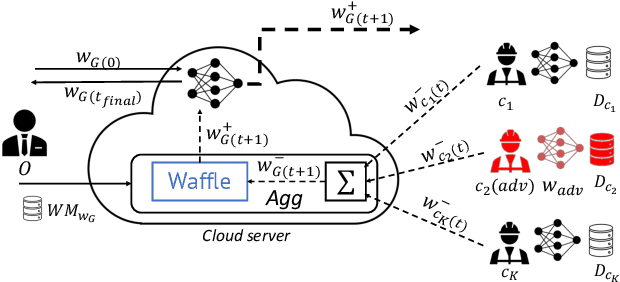


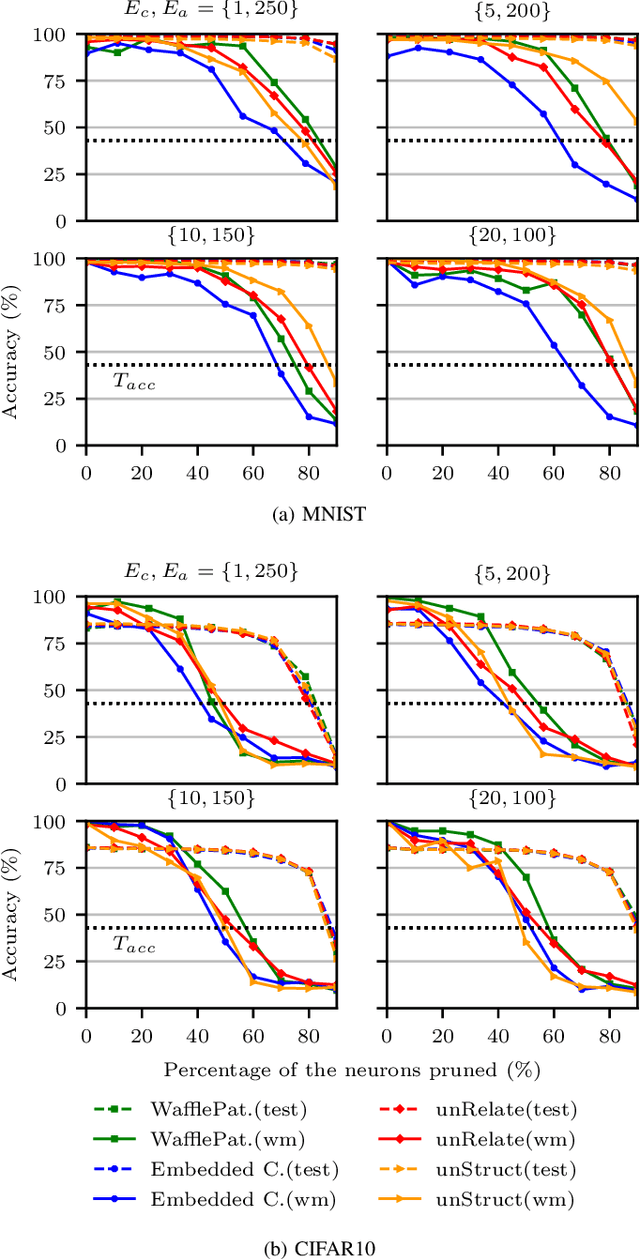
Creators of machine learning models can use watermarking as a technique to demonstrate their ownership if their models are stolen. Several recent proposals watermark deep neural network (DNN) models using backdooring: training them with additional mislabeled data. Backdooring requires full access to the training data and control of the training process. This is feasible when a single party trains the model in a centralized manner, but not in a federated learning setting where the training process and training data are distributed among several parties. In this paper, we introduce WAFFLE, the first approach to watermark DNN models in federated learning. It introduces a re-training step after each aggregation of local models into the global model. We show that WAFFLE efficiently embeds a resilient watermark into models with a negligible test accuracy degradation (-0.17%), and does not require access to the training data. We introduce a novel technique to generate the backdoor used as a watermark. It outperforms prior techniques, imposing no communication, and low computational(+2.8%) overhead.