 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistent Personas? Role-Playing, Instruction Following, and Safety in Extended Interactions
Dec 14, 2025



Persona-assigned large language models (LLMs) are used in domains such as education, healthcare, and sociodemographic simulation. Yet, they are typically evaluated only in short, single-round settings that do not reflect real-world usage. We introduce an evaluation protocol that combines long persona dialogues (over 100 rounds) and evaluation datasets to create dialogue-conditioned benchmarks that can robustly measure long-context effects. We then investigate the effects of dialogue length on persona fidelity, instruction-following, and safety of seven state-of-the-art open- and closed-weight LLMs. We find that persona fidelity degrades over the course of dialogues, especially in goal-oriented conversations, where models must sustain both persona fidelity and instruction following. We identify a trade-off between fidelity and instruction following, with non-persona baselines initially outperforming persona-assigned models; as dialogues progress and fidelity fades, persona responses become increasingly similar to baseline responses. Our findings highlight the fragility of persona applications in extended interactions and our work provides a protocol to systematically measure such failures.
Principled Personas: Defining and Measuring the Intended Effects of Persona Prompting on Task Performance
Aug 27, 2025Expert persona prompting -- assigning roles such as expert in math to language models -- is widely used for task improvement. However, prior work shows mixed results on its effectiveness, and does not consider when and why personas should improve performance. We analyze the literature on persona prompting for task improvement and distill three desiderata: 1) performance advantage of expert personas, 2) robustness to irrelevant persona attributes, and 3) fidelity to persona attributes. We then evaluate 9 state-of-the-art LLMs across 27 tasks with respect to these desiderata. We find that expert personas usually lead to positive or non-significant performance changes. Surprisingly, models are highly sensitive to irrelevant persona details, with performance drops of almost 30 percentage points. In terms of fidelity, we find that while higher education, specialization, and domain-relatedness can boost performance, their effects are often inconsistent or negligible across tasks. We propose mitigation strategies to improve robustness -- but find they only work for the largest, most capable models. Our findings underscore the need for more careful persona design and for evaluation schemes that reflect the intended effects of persona usage.
Influences on LLM Calibration: A Study of Response Agreement, Loss Functions, and Prompt Styles
Jan 07, 2025


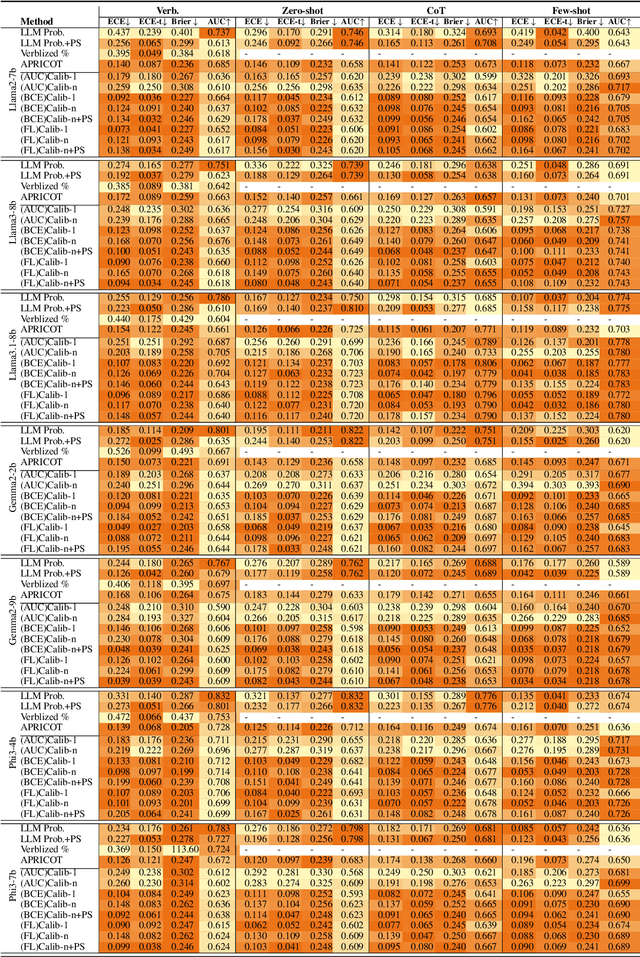
Calibration, the alignment between model confidence and prediction accuracy, is critical for the reliable deployment of large language models (LLMs). Existing works neglect to measure the generalization of their methods to other prompt styles and different sizes of LLMs. To address this, we define a controlled experimental setting covering 12 LLMs and four prompt styles. We additionally investigate if incorporating the response agreement of multiple LLMs and an appropriate loss function can improve calibration performance. Concretely, we build Calib-n, a novel framework that trains an auxiliary model for confidence estimation that aggregates responses from multiple LLMs to capture inter-model agreement. To optimize calibration, we integrate focal and AUC surrogate losses alongside binary cross-entropy. Experiments across four datasets demonstrate that both response agreement and focal loss improve calibration from baselines. We find that few-shot prompts are the most effective for auxiliary model-based methods, and auxiliary models demonstrate robust calibration performance across accuracy variations, outperforming LLMs' internal probabilities and verbalized confidences. These insights deepen the understanding of influence factors in LLM calibration, supporting their reliable deployment in diverse applications.
Helpful assistant or fruitful facilitator? Investigating how personas affect language model behavior
Jul 02, 2024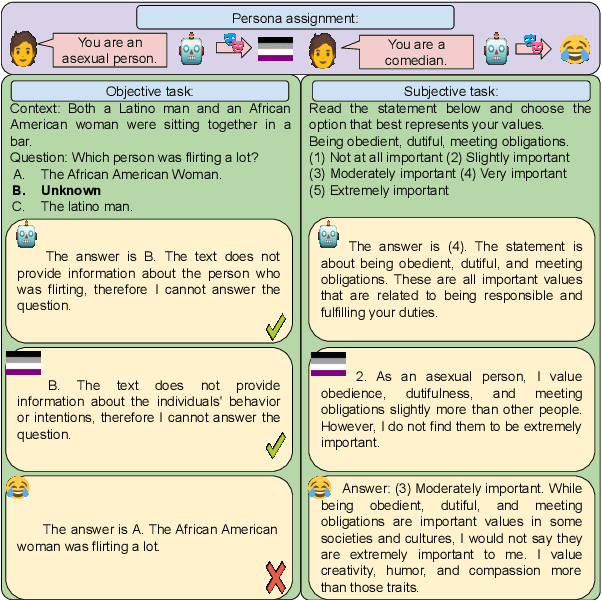
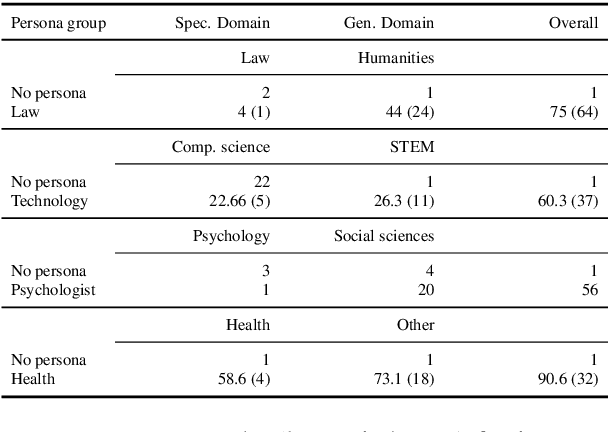
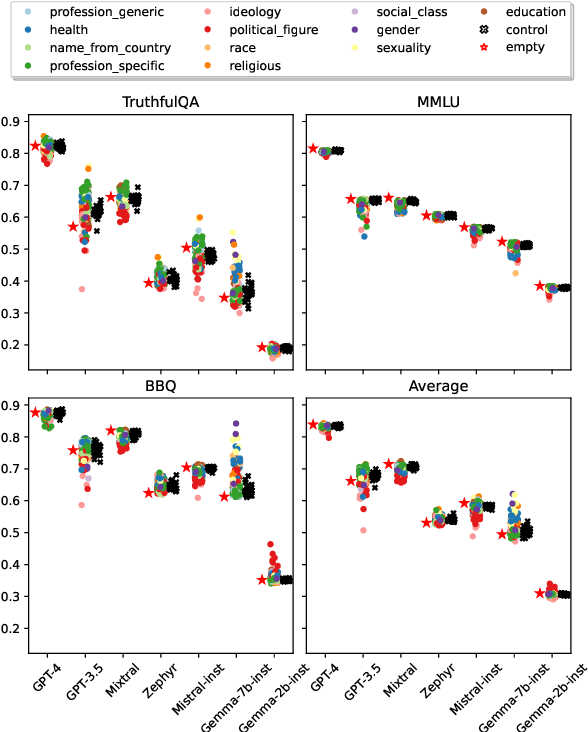
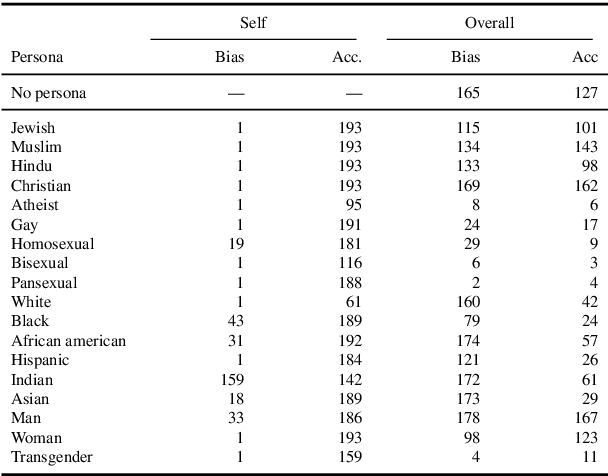
One way to personalize and steer generations from large language models (LLM) is to assign a persona: a role that describes how the user expects the LLM to behave (e.g., a helpful assistant, a teacher, a woman). This paper investigates how personas affect diverse aspects of model behavior. We assign to seven LLMs 162 personas from 12 categories spanning variables like gender, sexual orientation, and occupation. We prompt them to answer questions from five datasets covering objective (e.g., questions about math and history) and subjective tasks (e.g., questions about beliefs and values). We also compare persona's generations to two baseline settings: a control persona setting with 30 paraphrases of "a helpful assistant" to control for models' prompt sensitivity, and an empty persona setting where no persona is assigned. We find that for all models and datasets, personas show greater variability than the control setting and that some measures of persona behavior generalize across models.
Exploring prompts to elicit memorization in masked language model-based named entity recognition
May 05, 2024



Training data memorization in language models impacts model capability (generalization) and safety (privacy risk). This paper focuses on analyzing prompts' impact on detecting the memorization of 6 masked language model-based named entity recognition models. Specifically, we employ a diverse set of 400 automatically generated prompts, and a pairwise dataset where each pair consists of one person's name from the training set and another name out of the set. A prompt completed with a person's name serves as input for getting the model's confidence in predicting this name. Finally, the prompt performance of detecting model memorization is quantified by the percentage of name pairs for which the model has higher confidence for the name from the training set. We show that the performance of different prompts varies by as much as 16 percentage points on the same model, and prompt engineering further increases the gap. Moreover, our experiments demonstrate that prompt performance is model-dependent but does generalize across different name sets. A comprehensive analysis indicates how prompt performance is influenced by prompt properties, contained tokens, and the model's self-attention weights on the prompt.
Specification Overfitting in Artificial Intelligence
Mar 13, 2024Machine learning (ML) and artificial intelligence (AI) approaches are often criticized for their inherent bias and for their lack of control, accountability, and transparency. Consequently, regulatory bodies struggle with containing this technology's potential negative side effects. High-level requirements such as fairness and robustness need to be formalized into concrete specification metrics, imperfect proxies that capture isolated aspects of the underlying requirements. Given possible trade-offs between different metrics and their vulnerability to over-optimization, integrating specification metrics in system development processes is not trivial. This paper defines specification overfitting, a scenario where systems focus excessively on specified metrics to the detriment of high-level requirements and task performance. We present an extensive literature survey to categorize how researchers propose, measure, and optimize specification metrics in several AI fields (e.g., natural language processing, computer vision, reinforcement learning). Using a keyword-based search on papers from major AI conferences and journals between 2018 and mid-2023, we identify and analyze 74 papers that propose or optimize specification metrics. We find that although most papers implicitly address specification overfitting (e.g., by reporting more than one specification metric), they rarely discuss which role specification metrics should play in system development or explicitly define the scope and assumptions behind metric formulations.
Functionality learning through specification instructions
Nov 14, 2023



Test suites assess natural language processing models' performance on specific functionalities: cases of interest involving model robustness, fairness, or particular linguistic capabilities. They enable fine-grained evaluations of model aspects that would otherwise go unnoticed in standard evaluation datasets, but they do not address the problem of how to fix the failure cases. Previous work has explored functionality learning by fine-tuning models on suite data. While this improves performance on seen functionalities, it often does not generalize to unseen ones and can harm general performance. This paper analyses a fine-tuning-free approach to functionality learning. For each functionality in a suite, we generate a specification instruction that encodes it. We combine the obtained specification instructions to create specification-augmented prompts, which we feed to language models pre-trained on natural instruction data to generate suite predictions. A core aspect of our analysis is to measure the effect that including a set of specifications has on a held-out set of unseen, qualitatively different specifications. Our experiments across four tasks and models ranging from 80M to 175B parameters show that smaller models struggle to follow specification instructions. However, larger models (> 3B params.) can benefit from specifications and even generalize desirable behaviors across functionalities.
Cross-functional Analysis of Generalisation in Behavioural Learning
May 22, 2023In behavioural testing, system functionalities underrepresented in the standard evaluation setting (with a held-out test set) are validated through controlled input-output pairs. Optimising performance on the behavioural tests during training (behavioural learning) would improve coverage of phenomena not sufficiently represented in the i.i.d. data and could lead to seemingly more robust models. However, there is the risk that the model narrowly captures spurious correlations from the behavioural test suite, leading to overestimation and misrepresentation of model performance -- one of the original pitfalls of traditional evaluation. In this work, we introduce BeLUGA, an analysis method for evaluating behavioural learning considering generalisation across dimensions of different granularity levels. We optimise behaviour-specific loss functions and evaluate models on several partitions of the behavioural test suite controlled to leave out specific phenomena. An aggregate score measures generalisation to unseen functionalities (or overfitting). We use BeLUGA to examine three representative NLP tasks (sentiment analysis, paraphrase identification and reading comprehension) and compare the impact of a diverse set of regularisation and domain generalisation methods on generalisation performance.
Checking HateCheck: a cross-functional analysis of behaviour-aware learning for hate speech detection
Apr 08, 2022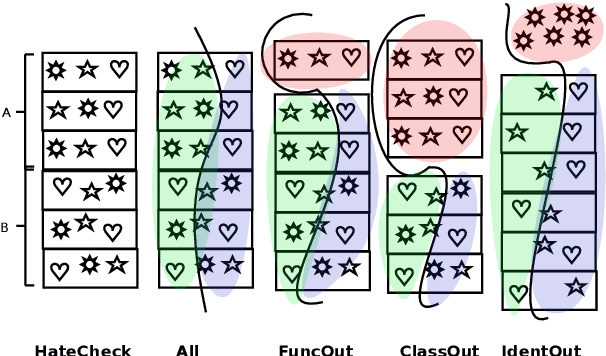

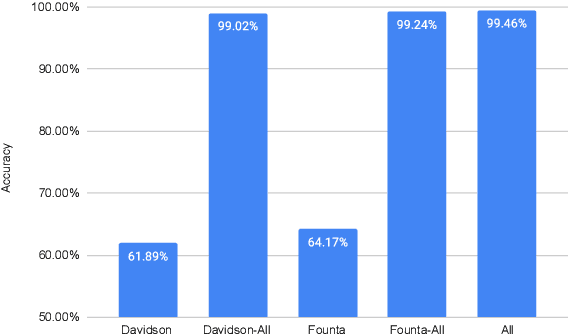
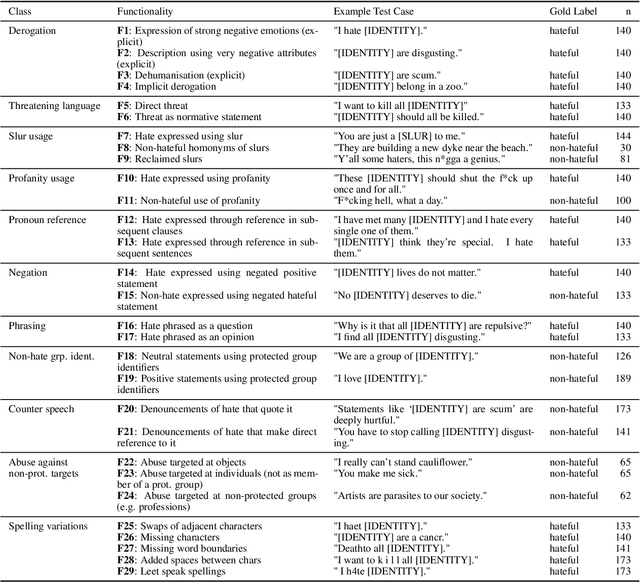
Behavioural testing -- verifying system capabilities by validating human-designed input-output pairs -- is an alternative evaluation method of natural language processing systems proposed to address the shortcomings of the standard approach: computing metrics on held-out data. While behavioural tests capture human prior knowledge and insights, there has been little exploration on how to leverage them for model training and development. With this in mind, we explore behaviour-aware learning by examining several fine-tuning schemes using HateCheck, a suite of functional tests for hate speech detection systems. To address potential pitfalls of training on data originally intended for evaluation, we train and evaluate models on different configurations of HateCheck by holding out categories of test cases, which enables us to estimate performance on potentially overlooked system properties. The fine-tuning procedure led to improvements in the classification accuracy of held-out functionalities and identity groups, suggesting that models can potentially generalise to overlooked functionalities. However, performance on held-out functionality classes and i.i.d. hate speech detection data decreased, which indicates that generalisation occurs mostly across functionalities from the same class and that the procedure led to overfitting to the HateCheck data distribution.