 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large Language Models to Tackle Fundamental Challenges in Graph Learning: A Comprehensive Survey
May 24, 2025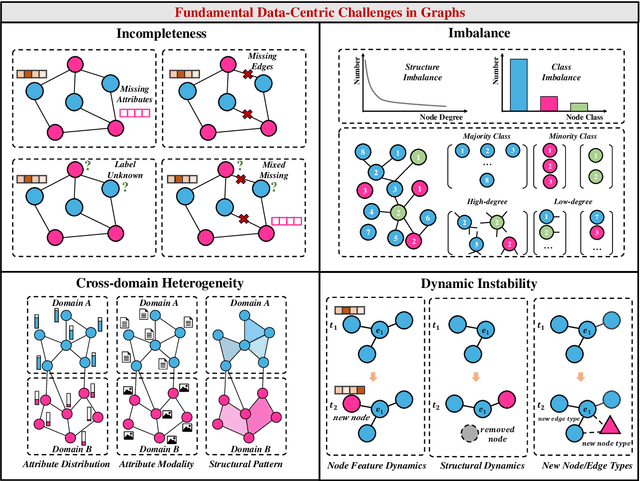
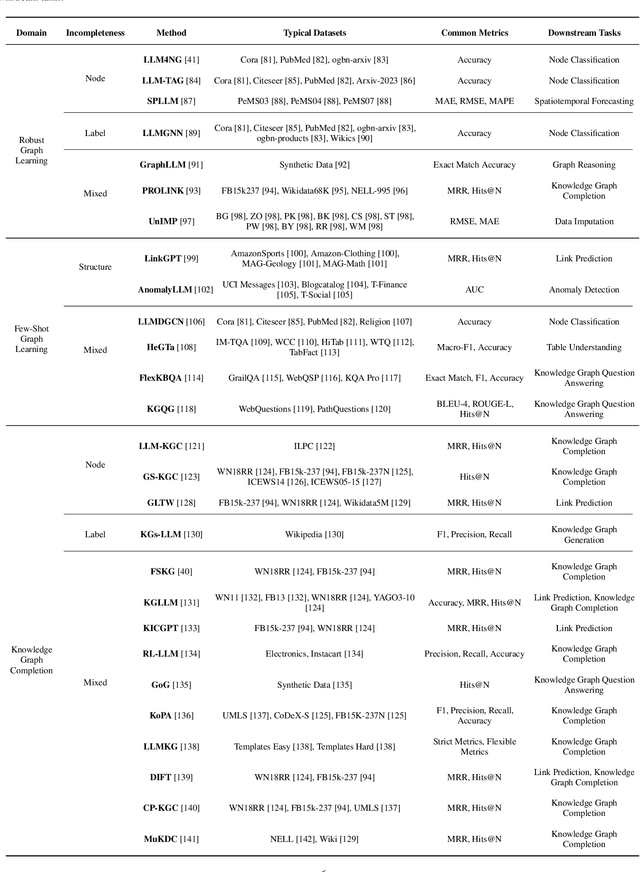
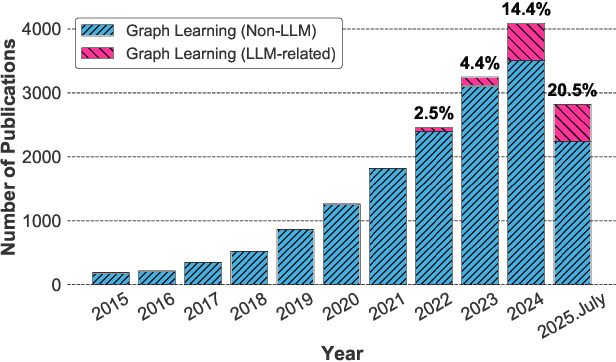
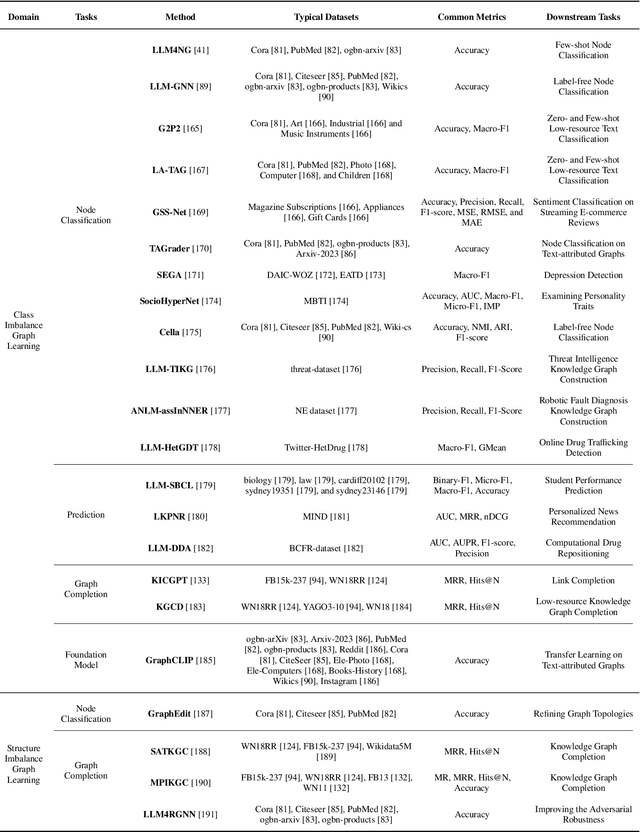
Graphs are a widely used paradigm for representing non-Euclidean data, with applications ranging from social network analysis to biomolecular prediction. Conventional graph learning approaches typically rely on fixed structural assumptions or fully observed data, limiting their effectiveness in more complex, noisy, or evolving settings. Consequently, real-world graph data often violates the assumptions of traditional graph learning methods, in particular, it leads to four fundamental challenges: (1) Incompleteness, real-world graphs have missing nodes, edges, or attributes; (2) Imbalance, the distribution of the labels of nodes or edges and their structures for real-world graphs are highly skewed; (3) Cross-domain Heterogeneity, graphs from different domains exhibit incompatible feature spaces or structural patterns; and (4) Dynamic Instability, graphs evolve over time in unpredictable ways. Recent advances in Large Language Models (LLMs) offer the potential to tackle these challenges by leveraging rich semantic reasoning and external knowledge. This survey provides a comprehensive review of how LLMs can be integrated with graph learning to address the aforementioned challenges. For each challenge, we review both traditional solutions and modern LLM-driven approaches, highlighting how LLMs contribute unique advantages. Finally, we discuss open research questions and promising future directions in this emerging interdisciplinary field. To support further exploration, we have curated a repository of recent advances on graph learning challenges: https://github.com/limengran98/Awesome-Literature-Graph-Learning-Challenges.
Influences on LLM Calibration: A Study of Response Agreement, Loss Functions, and Prompt Styles
Jan 07, 2025Calibration, the alignment between model confidence and prediction accuracy, is critical for the reliable deployment of large language models (LLMs). Existing works neglect to measure the generalization of their methods to other prompt styles and different sizes of LLMs. To address this, we define a controlled experimental setting covering 12 LLMs and four prompt styles. We additionally investigate if incorporating the response agreement of multiple LLMs and an appropriate loss function can improve calibration performance. Concretely, we build Calib-n, a novel framework that trains an auxiliary model for confidence estimation that aggregates responses from multiple LLMs to capture inter-model agreement. To optimize calibration, we integrate focal and AUC surrogate losses alongside binary cross-entropy. Experiments across four datasets demonstrate that both response agreement and focal loss improve calibration from baselines. We find that few-shot prompts are the most effective for auxiliary model-based methods, and auxiliary models demonstrate robust calibration performance across accuracy variations, outperforming LLMs' internal probabilities and verbalized confidences. These insights deepen the understanding of influence factors in LLM calibration, supporting their reliable deployment in diverse applications.
CYCLE: Cross-Year Contrastive Learning in Entity-Linking
Oct 11, 2024



Knowledge graphs constantly evolve with new entities emerging, existing definitions being revised, and entity relationships changing. These changes lead to temporal degradation in entity linking models, characterized as a decline in model performance over time. To address this issue, we propose leveraging graph relationships to aggregate information from neighboring entities across different time periods. This approach enhances the ability to distinguish similar entities over time, thereby minimizing the impact of temporal degradation. We introduce \textbf{CYCLE}: \textbf{C}ross-\textbf{Y}ear \textbf{C}ontrastive \textbf{L}earning for \textbf{E}ntity-Linking. This model employs a novel graph contrastive learning method to tackle temporal performance degradation in entity linking tasks. Our contrastive learning method treats newly added graph relationships as \textit{positive} samples and newly removed ones as \textit{negative} samples. This approach helps our model effectively prevent temporal degradation, achieving a 13.90\% performance improvement over the state-of-the-art from 2023 when the time gap is one year, and a 17.79\% improvement as the gap expands to three years. Further analysis shows that CYCLE is particularly robust for low-degree entities, which are less resistant to temporal degradation due to their sparse connectivity, making them particularly suitable for our method. The code and data are made available at \url{https://github.com/pengyu-zhang/CYCLE-Cross-Year-Contrastive-Learning-in-Entity-Linking}.
Analysing zero-shot temporal relation extraction on clinical notes using temporal consistency
Jun 17, 2024
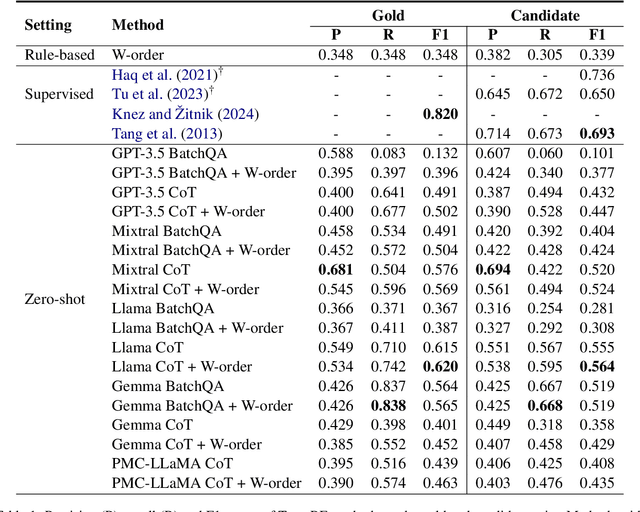
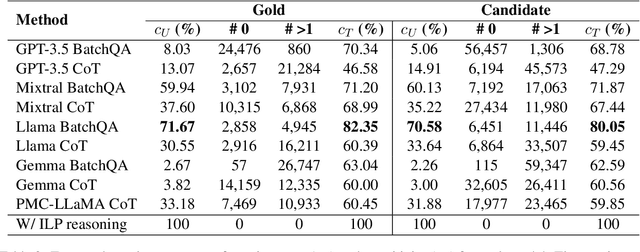
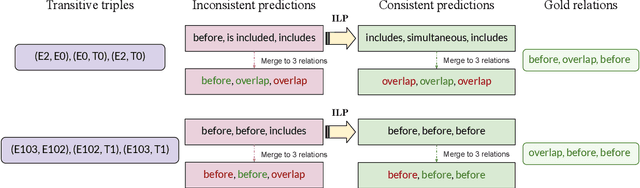
This paper presents the first study for temporal relation extraction in a zero-shot setting focusing on biomedical text. We employ two types of prompts and five LLMs (GPT-3.5, Mixtral, Llama 2, Gemma, and PMC-LLaMA) to obtain responses about the temporal relations between two events. Our experiments demonstrate that LLMs struggle in the zero-shot setting performing worse than fine-tuned specialized models in terms of F1 score, showing that this is a challenging task for LLMs. We further contribute a novel comprehensive temporal analysis by calculating consistency scores for each LLM. Our findings reveal that LLMs face challenges in providing responses consistent to the temporal properties of uniqueness and transitivity. Moreover, we study the relation between the temporal consistency of an LLM and its accuracy and whether the latter can be improved by solving temporal inconsistencies. Our analysis shows that even when temporal consistency is achieved, the predictions can remain inaccurate.
Wiki Entity Summarization Benchmark
Jun 12, 2024



Entity summarization aims to compute concise summaries for entities in knowledge graphs. Existing datasets and benchmarks are often limited to a few hundred entities and discard graph structure in source knowledge graphs. This limitation is particularly pronounced when it comes to ground-truth summaries, where there exist only a few labeled summaries for evaluation and training. We propose WikES, a comprehensive benchmark comprising of entities, their summaries, and their connections. Additionally, WikES features a dataset generator to test entity summarization algorithms in different areas of the knowledge graph. Importantly, our approach combines graph algorithms and NLP models as well as different data sources such that WikES does not require human annotation, rendering the approach cost-effective and generalizable to multiple domains. Finally, WikES is scalable and capable of capturing the complexities of knowledge graphs in terms of topology and semantics. WikES features existing datasets for comparison. Empirical studies of entity summarization methods confirm the usefulness of our benchmark. Data, code, and models are available at: https://github.com/msorkhpar/wiki-entity-summarization.
Personality Style Recognition via Machine Learning: Identifying Anaclitic and Introjective Personality Styles from Patients' Speech
Nov 07, 2023



In disentangling the heterogeneity observed in psychopathology, personality of the patients is considered crucial. While it has been demonstrated that personality traits are reflected in the language used by a patient, we hypothesize that this enables automatic inference of the personality type directly from speech utterances, potentially more accurately than through a traditional questionnaire-based approach explicitly designed for personality classification. To validate this hypothesis, we adopt natural language processing (NLP) and standard machine learning tools for classification. We test this on a dataset of recorded clinical diagnostic interviews (CDI) on a sample of 79 patients diagnosed with major depressive disorder (MDD) -- a condition for which differentiated treatment based on personality styles has been advocated -- and classified into anaclitic and introjective personality styles. We start by analyzing the interviews to see which linguistic features are associated with each style, in order to gain a better understanding of the styles. Then, we develop automatic classifiers based on (a) standardized questionnaire responses; (b) basic text features, i.e., TF-IDF scores of words and word sequences; (c) more advanced text features, using LIWC (linguistic inquiry and word count) and context-aware features using BERT (bidirectional encoder representations from transformers); (d) audio features. We find that automated classification with language-derived features (i.e., based on LIWC) significantly outperforms questionnaire-based classification models. Furthermore, the best performance is achieved by combining LIWC with the questionnaire features. This suggests that more work should be put into developing linguistically based automated techniques for characterizing personality, however questionnaires still to some extent complement such methods.
BioDEX: Large-Scale Biomedical Adverse Drug Event Extraction for Real-World Pharmacovigilance
May 22, 2023



Timely and accurate extraction of Adverse Drug Events (ADE) from biomedical literature is paramount for public safety, but involves slow and costly manual labor. We set out to improve drug safety monitoring (pharmacovigilance, PV) through the use of Natural Language Processing (NLP). We introduce BioDEX, a large-scale resource for Biomedical adverse Drug Event Extraction, rooted in the historical output of drug safety reporting in the U.S. BioDEX consists of 65k abstracts and 19k full-text biomedical papers with 256k associated document-level safety reports created by medical experts. The core features of these reports include the reported weight, age, and biological sex of a patient, a set of drugs taken by the patient, the drug dosages, the reactions experienced, and whether the reaction was life threatening. In this work, we consider the task of predicting the core information of the report given its originating paper. We estimate human performance to be 72.0% F1, whereas our best model achieves 62.3% F1, indicating significant headroom on this task. We also begin to explore ways in which these models could help professional PV reviewers. Our code and data are available: https://github.com/KarelDO/BioDEX.
Neural Approaches to Entity-Centric Information Extraction
Apr 15, 2023

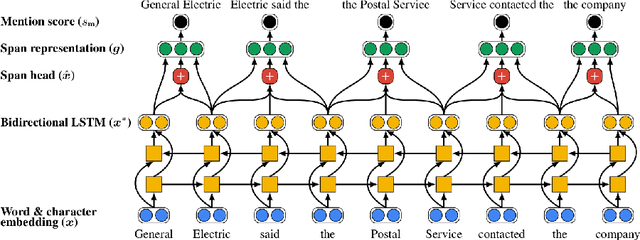
Artificial Intelligence (AI) has huge impact on our daily lives with applications such as voice assistants, facial recognition, chatbots, autonomously driving cars, etc. Natural Language Processing (NLP) is a cross-discipline of AI and Linguistics, dedicated to study the understanding of the text. This is a very challenging area due to unstructured nature of the language, with many ambiguous and corner cases. In this thesis we address a very specific area of NLP that involves the understanding of entities (e.g., names of people, organizations, locations) in text. First, we introduce a radically different, entity-centric view of the information in text. We argue that instead of using individual mentions in text to understand their meaning, we should build applications that would work in terms of entity concepts. Next, we present a more detailed model on how the entity-centric approach can be used for the entity linking task. In our work, we show that this task can be improved by considering performing entity linking at the coreference cluster level rather than each of the mentions individually. In our next work, we further study how information from Knowledge Base entities can be integrated into text. Finally, we analyze the evolution of the entities from the evolving temporal perspective.
TempEL: Linking Dynamically Evolving and Newly Emerging Entities
Feb 05, 2023



In our continuously evolving world, entities change over time and new, previously non-existing or unknown, entities appear. We study how this evolutionary scenario impacts the performance on a well established entity linking (EL) task. For that study, we introduce TempEL, an entity linking dataset that consists of time-stratified English Wikipedia snapshots from 2013 to 2022, from which we collect both anchor mentions of entities, and these target entities' descriptions. By capturing such temporal aspects, our newly introduced TempEL resource contrasts with currently existing entity linking datasets, which are composed of fixed mentions linked to a single static version of a target Knowledge Base (e.g., Wikipedia 2010 for CoNLL-AIDA). Indeed, for each of our collected temporal snapshots, TempEL contains links to entities that are continual, i.e., occur in all of the years, as well as completely new entities that appear for the first time at some point. Thus, we enable to quantify the performance of current state-of-the-art EL models for: (i) entities that are subject to changes over time in their Knowledge Base descriptions as well as their mentions' contexts, and (ii) newly created entities that were previously non-existing (e.g., at the time the EL model was trained). Our experimental results show that in terms of temporal performance degradation, (i) continual entities suffer a decrease of up to 3.1% EL accuracy, while (ii) for new entities this accuracy drop is up to 17.9%. This highlights the challenge of the introduced TempEL dataset and opens new research prospects in the area of time-evolving entity disambiguation.
CookDial: A dataset for task-oriented dialogs grounded in procedural documents
Jun 17, 2022This work presents a new dialog dataset, CookDial, that facilitates research on task-oriented dialog systems with procedural knowledge understanding. The corpus contains 260 human-to-human task-oriented dialogs in which an agent, given a recipe document, guides the user to cook a dish. Dialogs in CookDial exhibit two unique features: (i) procedural alignment between the dialog flow and supporting document; (ii) complex agent decision-making that involves segmenting long sentences, paraphrasing hard instructions and resolving coreference in the dialog context. In addition, we identify three challenging (sub)tasks in the assumed task-oriented dialog system: (1) User Question Understanding, (2) Agent Action Frame Prediction, and (3) Agent Response Generation. For each of these tasks, we develop a neural baseline model, which we evaluate on the CookDial dataset. We publicly release the CookDial dataset, comprising rich annotations of both dialogs and recipe documents, to stimulate further research on domain-specific document-grounded dialog systems.
* The dataset and codes are available at https://github.com/YiweiJiang2015/CookDial