 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonality Style Recognition via Machine Learning: Identifying Anaclitic and Introjective Personality Styles from Patients' Speech
Nov 07, 2023



In disentangling the heterogeneity observed in psychopathology, personality of the patients is considered crucial. While it has been demonstrated that personality traits are reflected in the language used by a patient, we hypothesize that this enables automatic inference of the personality type directly from speech utterances, potentially more accurately than through a traditional questionnaire-based approach explicitly designed for personality classification. To validate this hypothesis, we adopt natural language processing (NLP) and standard machine learning tools for classification. We test this on a dataset of recorded clinical diagnostic interviews (CDI) on a sample of 79 patients diagnosed with major depressive disorder (MDD) -- a condition for which differentiated treatment based on personality styles has been advocated -- and classified into anaclitic and introjective personality styles. We start by analyzing the interviews to see which linguistic features are associated with each style, in order to gain a better understanding of the styles. Then, we develop automatic classifiers based on (a) standardized questionnaire responses; (b) basic text features, i.e., TF-IDF scores of words and word sequences; (c) more advanced text features, using LIWC (linguistic inquiry and word count) and context-aware features using BERT (bidirectional encoder representations from transformers); (d) audio features. We find that automated classification with language-derived features (i.e., based on LIWC) significantly outperforms questionnaire-based classification models. Furthermore, the best performance is achieved by combining LIWC with the questionnaire features. This suggests that more work should be put into developing linguistically based automated techniques for characterizing personality, however questionnaires still to some extent complement such methods.
Leveraging the Inherent Hierarchy of Vacancy Titles for Automated Job Ontology Expansion
Apr 06, 2020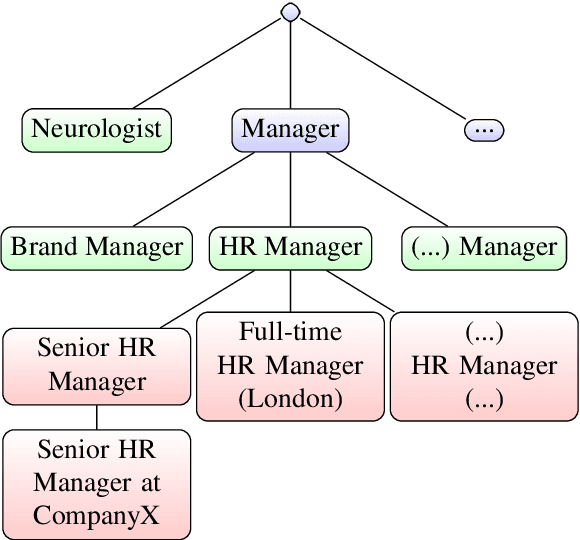
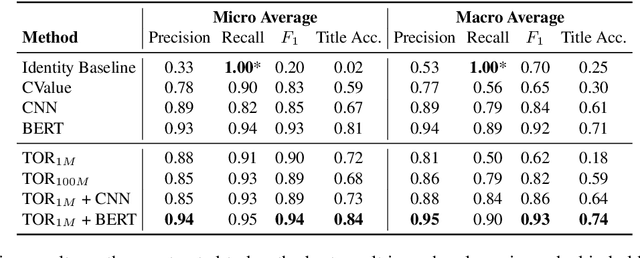

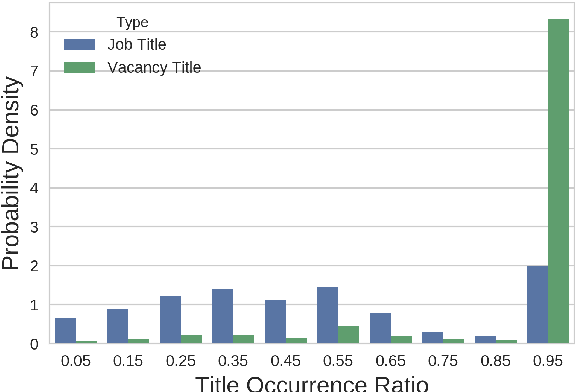
Machine learning plays an ever-bigger part in online recruitment, powering intelligent matchmaking and job recommendations across many of the world's largest job platforms. However, the main text is rarely enough to fully understand a job posting: more often than not, much of the required information is condensed into the job title. Several organised efforts have been made to map job titles onto a hand-made knowledge base as to provide this information, but these only cover around 60\% of online vacancies. We introduce a novel, purely data-driven approach towards the detection of new job titles. Our method is conceptually simple, extremely efficient and competitive with traditional NER-based approaches. Although the standalone application of our method does not outperform a finetuned BERT model, it can be applied as a preprocessing step as well, substantially boosting accuracy across several architectures.