 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Cross-Lingual Sentiment Classification under Distribution Shift: an Exploratory Study
Nov 11, 2023



The brittleness of finetuned language model performance on out-of-distribution (OOD) test samples in unseen domains has been well-studied for English, yet is unexplored for multi-lingual models. Therefore, we study generalization to OOD test data specifically in zero-shot cross-lingual transfer settings, analyzing performance impacts of both language and domain shifts between train and test data. We further assess the effectiveness of counterfactually augmented data (CAD) in improving OOD generalization for the cross-lingual setting, since CAD has been shown to benefit in a monolingual English setting. Finally, we propose two new approaches for OOD generalization that avoid the costly annotation process associated with CAD, by exploiting the power of recent large language models (LLMs). We experiment with 3 multilingual models, LaBSE, mBERT, and XLM-R trained on English IMDb movie reviews, and evaluate on OOD test sets in 13 languages: Amazon product reviews, Tweets, and Restaurant reviews. Results echo the OOD performance decline observed in the monolingual English setting. Further, (i) counterfactuals from the original high-resource language do improve OOD generalization in the low-resource language, and (ii) our newly proposed cost-effective approaches reach similar or up to +3.1% better accuracy than CAD for Amazon and Restaurant reviews.
Personality Style Recognition via Machine Learning: Identifying Anaclitic and Introjective Personality Styles from Patients' Speech
Nov 07, 2023



In disentangling the heterogeneity observed in psychopathology, personality of the patients is considered crucial. While it has been demonstrated that personality traits are reflected in the language used by a patient, we hypothesize that this enables automatic inference of the personality type directly from speech utterances, potentially more accurately than through a traditional questionnaire-based approach explicitly designed for personality classification. To validate this hypothesis, we adopt natural language processing (NLP) and standard machine learning tools for classification. We test this on a dataset of recorded clinical diagnostic interviews (CDI) on a sample of 79 patients diagnosed with major depressive disorder (MDD) -- a condition for which differentiated treatment based on personality styles has been advocated -- and classified into anaclitic and introjective personality styles. We start by analyzing the interviews to see which linguistic features are associated with each style, in order to gain a better understanding of the styles. Then, we develop automatic classifiers based on (a) standardized questionnaire responses; (b) basic text features, i.e., TF-IDF scores of words and word sequences; (c) more advanced text features, using LIWC (linguistic inquiry and word count) and context-aware features using BERT (bidirectional encoder representations from transformers); (d) audio features. We find that automated classification with language-derived features (i.e., based on LIWC) significantly outperforms questionnaire-based classification models. Furthermore, the best performance is achieved by combining LIWC with the questionnaire features. This suggests that more work should be put into developing linguistically based automated techniques for characterizing personality, however questionnaires still to some extent complement such methods.
CAW-coref: Conjunction-Aware Word-level Coreference Resolution
Oct 19, 2023


State-of-the-art coreference resolutions systems depend on multiple LLM calls per document and are thus prohibitively expensive for many use cases (e.g., information extraction with large corpora). The leading word-level coreference system (WL-coref) attains 96.6% of these SOTA systems' performance while being much more efficient. In this work, we identify a routine yet important failure case of WL-coref: dealing with conjoined mentions such as 'Tom and Mary'. We offer a simple yet effective solution that improves the performance on the OntoNotes test set by 0.9% F1, shrinking the gap between efficient word-level coreference resolution and expensive SOTA approaches by 34.6%. Our Conjunction-Aware Word-level coreference model (CAW-coref) and code is available at https://github.com/KarelDO/wl-coref.
Distractor generation for multiple-choice questions with predictive prompting and large language models
Jul 30, 2023


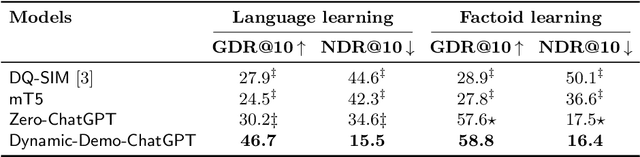
Large Language Models (LLMs) such as ChatGPT have demonstrated remarkable performance across various tasks and have garnered significant attention from both researchers and practitioners. However, in an educational context, we still observe a performance gap in generating distractors -- i.e., plausible yet incorrect answers -- with LLMs for multiple-choice questions (MCQs). In this study, we propose a strategy for guiding LLMs such as ChatGPT, in generating relevant distractors by prompting them with question items automatically retrieved from a question bank as well-chosen in-context examples. We evaluate our LLM-based solutions using a quantitative assessment on an existing test set, as well as through quality annotations by human experts, i.e., teachers. We found that on average 53% of the generated distractors presented to the teachers were rated as high-quality, i.e., suitable for immediate use as is, outperforming the state-of-the-art model. We also show the gains of our approach 1 in generating high-quality distractors by comparing it with a zero-shot ChatGPT and a few-shot ChatGPT prompted with static examples.
Learning from Partially Annotated Data: Example-aware Creation of Gap-filling Exercises for Language Learning
Jun 15, 2023Since performing exercises (including, e.g., practice tests) forms a crucial component of learning, and creating such exercises requires non-trivial effort from the teacher, there is a great value in automatic exercise generation in digital tools in education. In this paper, we particularly focus on automatic creation of gapfilling exercises for language learning, specifically grammar exercises. Since providing any annotation in this domain requires human expert effort, we aim to avoid it entirely and explore the task of converting existing texts into new gap-filling exercises, purely based on an example exercise, without explicit instruction or detailed annotation of the intended grammar topics. We contribute (i) a novel neural network architecture specifically designed for aforementioned gap-filling exercise generation task, and (ii) a real-world benchmark dataset for French grammar. We show that our model for this French grammar gap-filling exercise generation outperforms a competitive baseline classifier by 8% in F1 percentage points, achieving an average F1 score of 82%. Our model implementation and the dataset are made publicly available to foster future research, thus offering a standardized evaluation and baseline solution of the proposed partially annotated data prediction task in grammar exercise creation.
Learning to Reuse Distractors to support Multiple Choice Question Generation in Education
Oct 25, 2022



Multiple choice questions (MCQs) are widely used in digital learning systems, as they allow for automating the assessment process. However, due to the increased digital literacy of students and the advent of social media platforms, MCQ tests are widely shared online, and teachers are continuously challenged to create new questions, which is an expensive and time-consuming task. A particularly sensitive aspect of MCQ creation is to devise relevant distractors, i.e., wrong answers that are not easily identifiable as being wrong. This paper studies how a large existing set of manually created answers and distractors for questions over a variety of domains, subjects, and languages can be leveraged to help teachers in creating new MCQs, by the smart reuse of existing distractors. We built several data-driven models based on context-aware question and distractor representations, and compared them with static feature-based models. The proposed models are evaluated with automated metrics and in a realistic user test with teachers. Both automatic and human evaluations indicate that context-aware models consistently outperform a static feature-based approach. For our best-performing context-aware model, on average 3 distractors out of the 10 shown to teachers were rated as high-quality distractors. We create a performance benchmark, and make it public, to enable comparison between different approaches and to introduce a more standardized evaluation of the task. The benchmark contains a test of 298 educational questions covering multiple subjects & languages and a 77k multilingual pool of distractor vocabulary for future research.
EduQG: A Multi-format Multiple Choice Dataset for the Educational Domain
Oct 12, 2022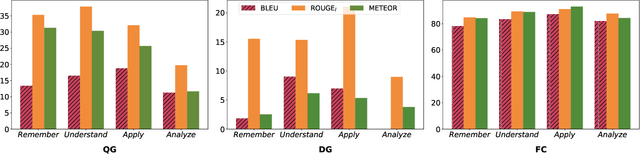
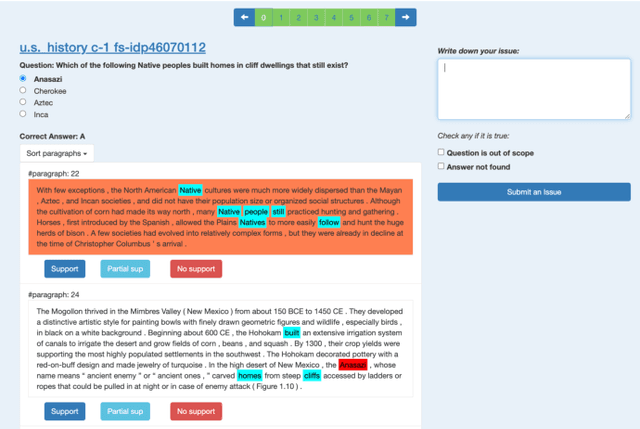
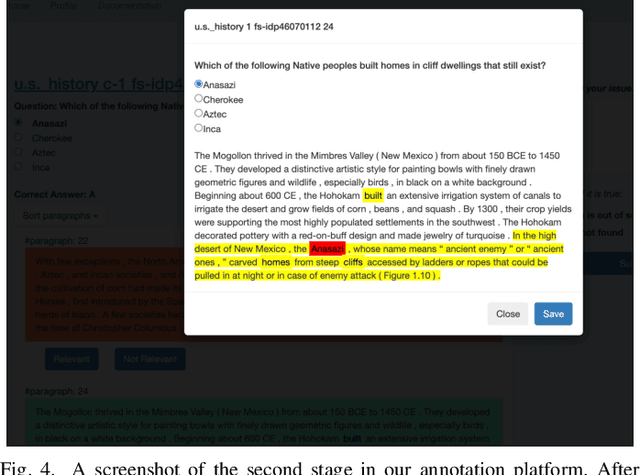
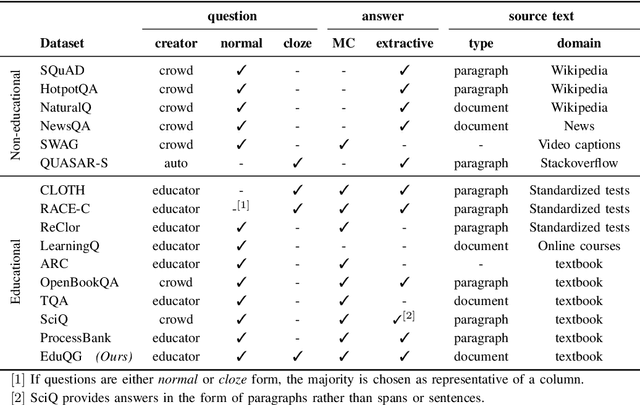
We introduce a high-quality dataset that contains 3,397 samples comprising (i) multiple choice questions, (ii) answers (including distractors), and (iii) their source documents, from the educational domain. Each question is phrased in two forms, normal and close. Correct answers are linked to source documents with sentence-level annotations. Thus, our versatile dataset can be used for both question and distractor generation, as well as to explore new challenges such as question format conversion. Furthermore, 903 questions are accompanied by their cognitive complexity level as per Bloom's taxonomy. All questions have been generated by educational experts rather than crowd workers to ensure they are maintaining educational and learning standards. Our analysis and experiments suggest distinguishable differences between our dataset and commonly used ones for question generation for educational purposes. We believe this new dataset can serve as a valuable resource for research and evaluation in the educational domain. The dataset and baselines will be released to support further research in question generation.