 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistractor generation for multiple-choice questions with predictive prompting and large language models
Paper and Code



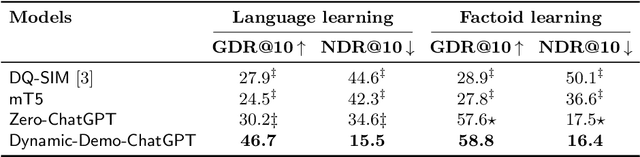
Large Language Models (LLMs) such as ChatGPT have demonstrated remarkable performance across various tasks and have garnered significant attention from both researchers and practitioners. However, in an educational context, we still observe a performance gap in generating distractors -- i.e., plausible yet incorrect answers -- with LLMs for multiple-choice questions (MCQs). In this study, we propose a strategy for guiding LLMs such as ChatGPT, in generating relevant distractors by prompting them with question items automatically retrieved from a question bank as well-chosen in-context examples. We evaluate our LLM-based solutions using a quantitative assessment on an existing test set, as well as through quality annotations by human experts, i.e., teachers. We found that on average 53% of the generated distractors presented to the teachers were rated as high-quality, i.e., suitable for immediate use as is, outperforming the state-of-the-art model. We also show the gains of our approach 1 in generating high-quality distractors by comparing it with a zero-shot ChatGPT and a few-shot ChatGPT prompted with static examples.