 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning is Not Enough: A Parallel Framework for Collaborative Imitation and Reinforcement Learning in End-to-end Autonomous Driving
Mar 14, 2026End-to-end autonomous driving is typically built upon imitation learning (IL), yet its performance is constrained by the quality of human demonstrations. To overcome this limitation, recent methods incorporate reinforcement learning (RL) through sequential fine-tuning. However, such a paradigm remains suboptimal: sequential RL fine-tuning can introduce policy drift and often leads to a performance ceiling due to its dependence on the pretrained IL policy. To address these issues, we propose PaIR-Drive, a general Parallel framework for collaborative Imitation and Reinforcement learning in end-to-end autonomous driving. During training, PaIR-Drive separates IL and RL into two parallel branches with conflict-free training objectives, enabling fully collaborative optimization. This design eliminates the need to retrain RL when applying a new IL policy. During inference, RL leverages the IL policy to further optimize the final plan, allowing performance beyond prior knowledge of IL. Furthermore, we introduce a tree-structured trajectory neural sampler to group relative policy optimization (GRPO) in the RL branch, which enhances exploration capability. Extensive analysis on NAVSIMv1 and v2 benchmark demonstrates that PaIR-Drive achieves Competitive performance of 91.2 PDMS and 87.9 EPDMS, building upon Transfuser and DiffusionDrive IL baselines. PaIR-Drive consistently outperforms existing RL fine-tuning methods, and could even correct human experts' suboptimal behaviors. Qualitative results further confirm that PaIR-Drive can effectively explore and generate high-quality trajectories.
DeepFusion: Accelerating MoE Training via Federated Knowledge Distillation from Heterogeneous Edge Devices
Feb 15, 2026Recent Mixture-of-Experts (MoE)-based large language models (LLMs) such as Qwen-MoE and DeepSeek-MoE are transforming generative AI in natural language processing. However, these models require vast and diverse training data. Federated learning (FL) addresses this challenge by leveraging private data from heterogeneous edge devices for privacy-preserving MoE training. Nonetheless, traditional FL approaches require devices to host local MoE models, which is impractical for resource-constrained devices due to large model sizes. To address this, we propose DeepFusion, the first scalable federated MoE training framework that enables the fusion of heterogeneous on-device LLM knowledge via federated knowledge distillation, yielding a knowledge-abundant global MoE model. Specifically, DeepFusion features each device to independently configure and train an on-device LLM tailored to its own needs and hardware limitations. Furthermore, we propose a novel View-Aligned Attention (VAA) module that integrates multi-stage feature representations from the global MoE model to construct a predictive perspective aligned with on-device LLMs, thereby enabling effective cross-architecture knowledge distillation. By explicitly aligning predictive perspectives, VAA resolves the view-mismatch problem in traditional federated knowledge distillation, which arises from heterogeneity in model architectures and prediction behaviors between on-device LLMs and the global MoE model. Experiments with industry-level MoE models (Qwen-MoE and DeepSeek-MoE) and real-world datasets (medical and finance) demonstrate that DeepFusion achieves performance close to centralized MoE training. Compared with key federated MoE baselines, DeepFusion reduces communication costs by up to 71% and improves token perplexity by up to 5.28%.
Preventing Rank Collapse in Federated Low-Rank Adaptation with Client Heterogeneity
Feb 13, 2026Federated low-rank adaptation (FedLoRA) has facilitated communication-efficient and privacy-preserving fine-tuning of foundation models for downstream tasks. In practical federated learning scenarios, client heterogeneity in system resources and data distributions motivates heterogeneous LoRA ranks across clients. We identify a previously overlooked phenomenon in heterogeneous FedLoRA, termed rank collapse, where the energy of the global update concentrates on the minimum shared rank, resulting in suboptimal performance and high sensitivity to rank configurations. Through theoretical analysis, we reveal the root cause of rank collapse: a mismatch between rank-agnostic aggregation weights and rank-dependent client contributions, which systematically suppresses higher-rank updates at a geometric rate over rounds. Motivated by this insight, we propose raFLoRA, a rank-partitioned aggregation method that decomposes local updates into rank partitions and then aggregates each partition weighted by its effective client contributions. Extensive experiments across classification and reasoning tasks show that raFLoRA prevents rank collapse, improves model performance, and preserves communication efficiency compared to state-of-the-art FedLoRA baselines.
Unifying Ranking and Generation in Query Auto-Completion via Retrieval-Augmented Generation and Multi-Objective Alignment
Feb 03, 2026Query Auto-Completion (QAC) suggests query completions as users type, helping them articulate intent and reach results more efficiently. Existing approaches face fundamental challenges: traditional retrieve-and-rank pipelines have limited long-tail coverage and require extensive feature engineering, while recent generative methods suffer from hallucination and safety risks. We present a unified framework that reformulates QAC as end-to-end list generation through Retrieval-Augmented Generation (RAG) and multi-objective Direct Preference Optimization (DPO). Our approach combines three key innovations: (1) reformulating QAC as end-to-end list generation with multi-objective optimization; (2) defining and deploying a suite of rule-based, model-based, and LLM-as-judge verifiers for QAC, and using them in a comprehensive methodology that combines RAG, multi-objective DPO, and iterative critique-revision for high-quality synthetic data; (3) a hybrid serving architecture enabling efficient production deployment under strict latency constraints. Evaluation on a large-scale commercial search platform demonstrates substantial improvements: offline metrics show gains across all dimensions, human evaluation yields +0.40 to +0.69 preference scores, and a controlled online experiment achieves 5.44\% reduction in keystrokes and 3.46\% increase in suggestion adoption, validating that unified generation with RAG and multi-objective alignment provides an effective solution for production QAC. This work represents a paradigm shift to end-to-end generation powered by large language models, RAG, and multi-objective alignment, establishing a production-validated framework that can benefit the broader search and recommendation industry.
PlannerRFT: Reinforcing Diffusion Planners through Closed-Loop and Sample-Efficient Fine-Tuning
Jan 19, 2026Diffusion-based planners have emerged as a promising approach for human-like trajectory generation in autonomous driving. Recent works incorporate reinforcement fine-tuning to enhance the robustness of diffusion planners through reward-oriented optimization in a generation-evaluation loop. However, they struggle to generate multi-modal, scenario-adaptive trajectories, hindering the exploitation efficiency of informative rewards during fine-tuning. To resolve this, we propose PlannerRFT, a sample-efficient reinforcement fine-tuning framework for diffusion-based planners. PlannerRFT adopts a dual-branch optimization that simultaneously refines the trajectory distribution and adaptively guides the denoising process toward more promising exploration, without altering the original inference pipeline. To support parallel learning at scale, we develop nuMax, an optimized simulator that achieves 10 times faster rollout compared to native nuPlan. Extensive experiments shows that PlannerRFT yields state-of-the-art performance with distinct behaviors emerging during the learning process.
A simulation platform calibration method for automated vehicle evaluation: accurate on both vehicle level and traffic flow level
Dec 18, 2025Simulation testing is a fundamental approach for evaluating automated vehicles (AVs). To ensure its reliability, it is crucial to accurately replicate interactions between AVs and background traffic, which necessitates effective calibration. However, existing calibration methods often fall short in achieving this goal. To address this gap, this study introduces a simulation platform calibration method that ensures high accuracy at both the vehicle and traffic flow levels. The method offers several key features:(1) with the capability of calibration for vehicle-to-vehicle interaction; (2) with accuracy assurance; (3) with enhanced efficiency; (4) with pipeline calibration capability. The proposed method is benchmarked against a baseline with no calibration and a state-of-the-art calibration method. Results show that it enhances the accuracy of interaction replication by 83.53% and boosts calibration efficiency by 76.75%. Furthermore, it maintains accuracy across both vehicle-level and traffic flow-level metrics, with an improvement of 51.9%. Notably, the entire calibration process is fully automated, requiring no human intervention.
PortAgent: LLM-driven Vehicle Dispatching Agent for Port Terminals
Dec 16, 2025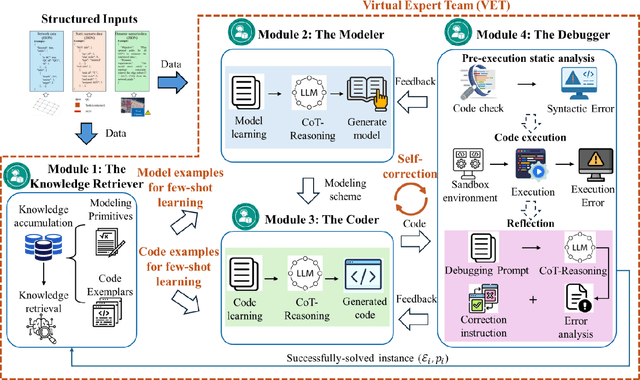
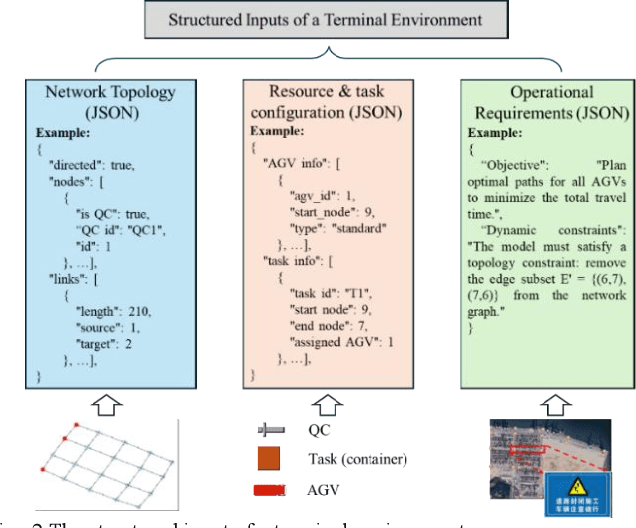
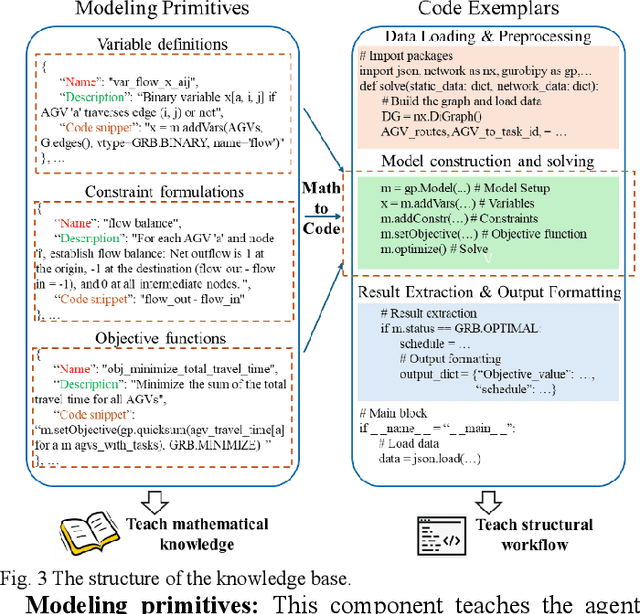
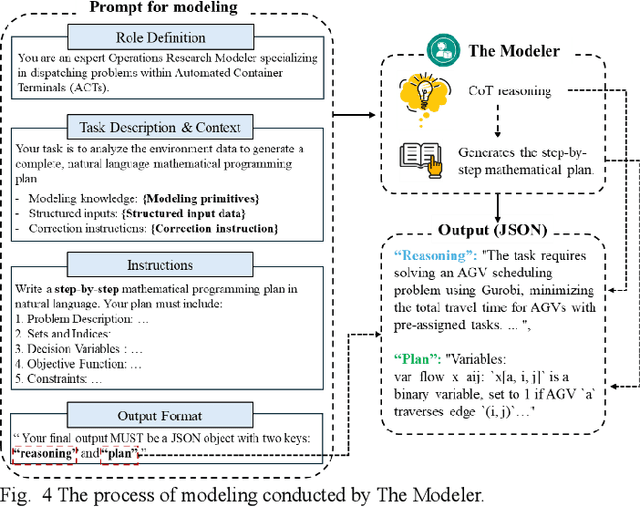
Vehicle Dispatching Systems (VDSs) are critical to the operational efficiency of Automated Container Terminals (ACTs). However, their widespread commercialization is hindered due to their low transferability across diverse terminals. This transferability challenge stems from three limitations: high reliance on port operational specialists, a high demand for terminal-specific data, and time-consuming manual deployment processes. Leveraging the emergence of Large Language Models (LLMs), this paper proposes PortAgent, an LLM-driven vehicle dispatching agent that fully automates the VDS transferring workflow. It bears three features: (1) no need for port operations specialists; (2) low need of data; and (3) fast deployment. Specifically, specialist dependency is eliminated by the Virtual Expert Team (VET). The VET collaborates with four virtual experts, including a Knowledge Retriever, Modeler, Coder, and Debugger, to emulate a human expert team for the VDS transferring workflow. These experts specialize in the domain of terminal VDS via a few-shot example learning approach. Through this approach, the experts are able to learn VDS-domain knowledge from a few VDS examples. These examples are retrieved via a Retrieval-Augmented Generation (RAG) mechanism, mitigating the high demand for terminal-specific data. Furthermore, an automatic VDS design workflow is established among these experts to avoid extra manual interventions. In this workflow, a self-correction loop inspired by the LLM Reflexion framework is created
A Review of Learning-Based Motion Planning: Toward a Data-Driven Optimal Control Approach
Dec 12, 2025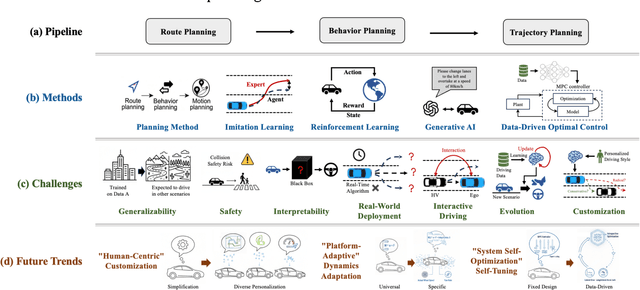
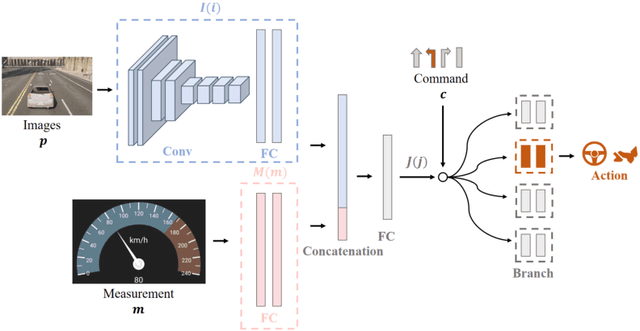
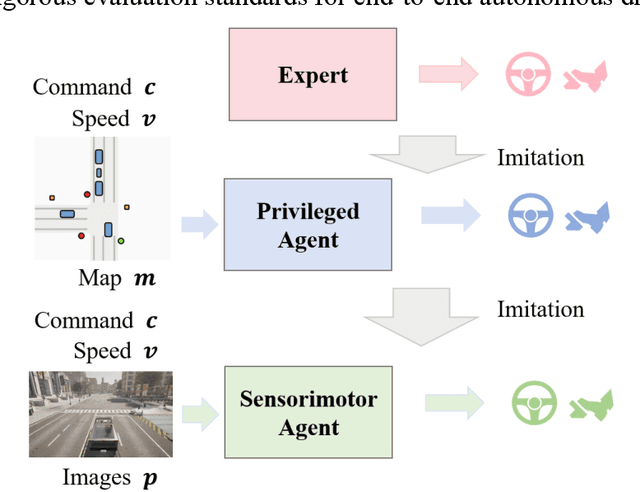
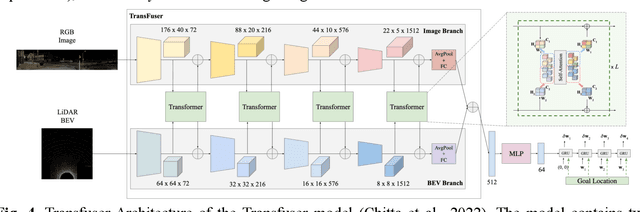
Motion planning for high-level autonomous driving is constrained by a fundamental trade-off between the transparent, yet brittle, nature of pipeline methods and the adaptive, yet opaque, "black-box" characteristics of modern learning-based systems. This paper critically synthesizes the evolution of the field -- from pipeline methods through imitation learning, reinforcement learning, and generative AI -- to demonstrate how this persistent dilemma has hindered the development of truly trustworthy systems. To resolve this impasse, we conduct a comprehensive review of learning-based motion planning methods. Based on this review, we outline a data-driven optimal control paradigm as a unifying framework that synergistically integrates the verifiable structure of classical control with the adaptive capacity of machine learning, leveraging real-world data to continuously refine key components such as system dynamics, cost functions, and safety constraints. We explore this framework's potential to enable three critical next-generation capabilities: "Human-Centric" customization, "Platform-Adaptive" dynamics adaptation, and "System Self-Optimization" via self-tuning. We conclude by proposing future research directions based on this paradigm, aimed at developing intelligent transportation systems that are simultaneously safe, interpretable, and capable of human-like autonomy.
Risk Map As Middleware: Towards Interpretable Cooperative End-to-end Autonomous Driving for Risk-Aware Planning
Aug 11, 2025End-to-end paradigm has emerged as a promising approach to autonomous driving. However, existing single-agent end-to-end pipelines are often constrained by occlusion and limited perception range, resulting in hazardous driving. Furthermore, their black-box nature prevents the interpretability of the driving behavior, leading to an untrustworthiness system. To address these limitations, we introduce Risk Map as Middleware (RiskMM) and propose an interpretable cooperative end-to-end driving framework. The risk map learns directly from the driving data and provides an interpretable spatiotemporal representation of the scenario from the upstream perception and the interactions between the ego vehicle and the surrounding environment for downstream planning. RiskMM first constructs a multi-agent spatiotemporal representation with unified Transformer-based architecture, then derives risk-aware representations by modeling interactions among surrounding environments with attention. These representations are subsequently fed into a learning-based Model Predictive Control (MPC) module. The MPC planner inherently accommodates physical constraints and different vehicle types and can provide interpretation by aligning learned parameters with explicit MPC elements. Evaluations conducted on the real-world V2XPnP-Seq dataset confirm that RiskMM achieves superior and robust performance in risk-aware trajectory planning, significantly enhancing the interpretability of the cooperative end-to-end driving framework. The codebase will be released to facilitate future research in this field.
Toward a Full-Stack Co-Simulation Platform for Testing of Automated Driving Systems
Jul 09, 2025Virtual testing has emerged as an effective approach to accelerate the deployment of automated driving systems. Nevertheless, existing simulation toolchains encounter difficulties in integrating rapid, automated scenario generation with simulation environments supporting advanced automated driving capabilities. To address this limitation, a full-stack toolchain is presented, enabling automatic scenario generation from real-world datasets and efficient validation through a co-simulation platform based on CarMaker, ROS, and Apollo. The simulation results demonstrate the effectiveness of the proposed toolchain. A demonstration video showcasing the toolchain is available at the provided link: https://youtu.be/taJw_-CmSiY.