 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Safety-Critical Decision and Control for Autonomous Vehicles at Unsignalized Intersections
May 26, 2025Reinforcement learning (RL) has demonstrated potential in autonomous driving (AD) decision tasks. However, applying RL to urban AD, particularly in intersection scenarios, still faces significant challenges. The lack of safety constraints makes RL vulnerable to risks. Additionally, cognitive limitations and environmental randomness can lead to unreliable decisions in safety-critical scenarios. Therefore, it is essential to quantify confidence in RL decisions to improve safety. This paper proposes an Uncertainty-aware Safety-Critical Decision and Control (USDC) framework, which generates a risk-averse policy by constructing a risk-aware ensemble distributional RL, while estimating uncertainty to quantify the policy's reliability. Subsequently, a high-order control barrier function (HOCBF) is employed as a safety filter to minimize intervention policy while dynamically enhancing constraints based on uncertainty. The ensemble critics evaluate both HOCBF and RL policies, embedding uncertainty to achieve dynamic switching between safe and flexible strategies, thereby balancing safety and efficiency. Simulation tests on unsignalized intersections in multiple tasks indicate that USDC can improve safety while maintaining traffic efficiency compared to baselines.
HCRMP: A LLM-Hinted Contextual Reinforcement Learning Framework for Autonomous Driving
May 21, 2025



Integrating Large Language Models (LLMs) with Reinforcement Learning (RL) can enhance autonomous driving (AD) performance in complex scenarios. However, current LLM-Dominated RL methods over-rely on LLM outputs, which are prone to hallucinations.Evaluations show that state-of-the-art LLM indicates a non-hallucination rate of only approximately 57.95% when assessed on essential driving-related tasks. Thus, in these methods, hallucinations from the LLM can directly jeopardize the performance of driving policies. This paper argues that maintaining relative independence between the LLM and the RL is vital for solving the hallucinations problem. Consequently, this paper is devoted to propose a novel LLM-Hinted RL paradigm. The LLM is used to generate semantic hints for state augmentation and policy optimization to assist RL agent in motion planning, while the RL agent counteracts potential erroneous semantic indications through policy learning to achieve excellent driving performance. Based on this paradigm, we propose the HCRMP (LLM-Hinted Contextual Reinforcement Learning Motion Planner) architecture, which is designed that includes Augmented Semantic Representation Module to extend state space. Contextual Stability Anchor Module enhances the reliability of multi-critic weight hints by utilizing information from the knowledge base. Semantic Cache Module is employed to seamlessly integrate LLM low-frequency guidance with RL high-frequency control. Extensive experiments in CARLA validate HCRMP's strong overall driving performance. HCRMP achieves a task success rate of up to 80.3% under diverse driving conditions with different traffic densities. Under safety-critical driving conditions, HCRMP significantly reduces the collision rate by 11.4%, which effectively improves the driving performance in complex scenarios.
A Survey of Reinforcement Learning-Based Motion Planning for Autonomous Driving: Lessons Learned from a Driving Task Perspective
Mar 31, 2025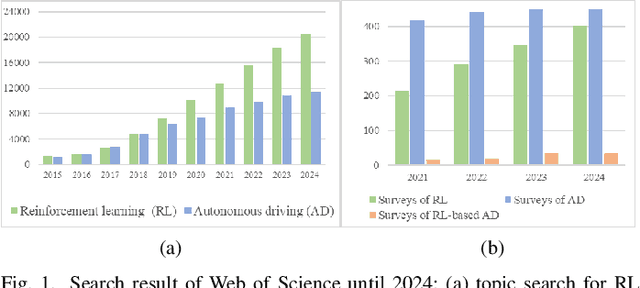
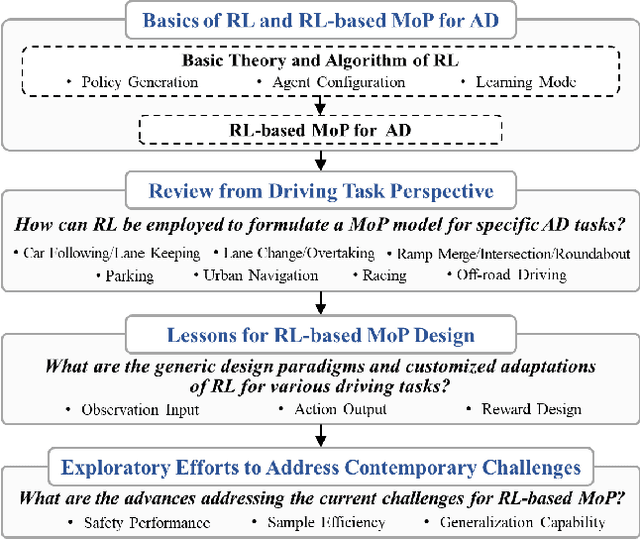
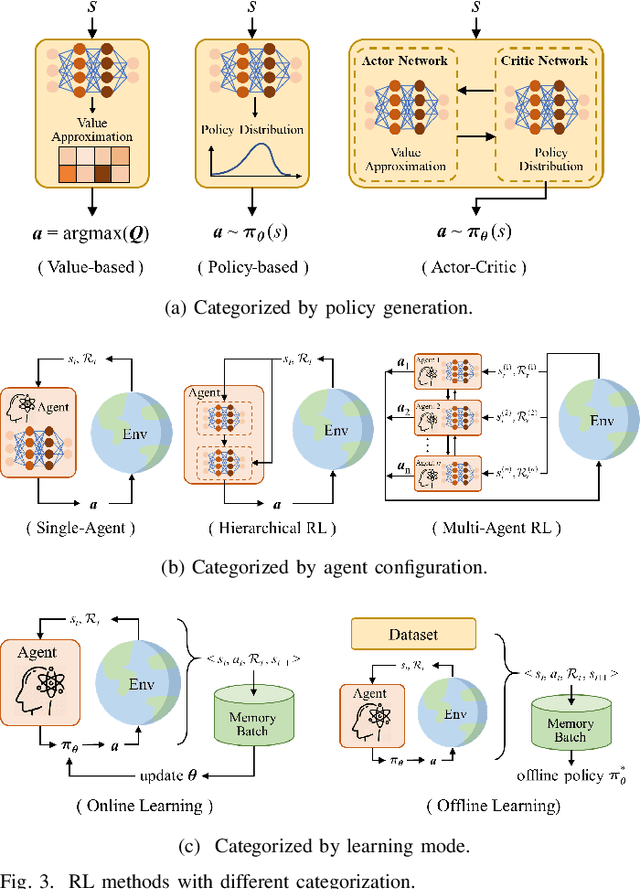
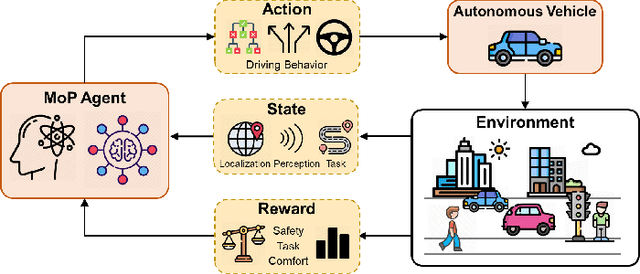
Reinforcement learning (RL), with its ability to explore and optimize policies in complex, dynamic decision-making tasks, has emerged as a promising approach to addressing motion planning (MoP) challenges in autonomous driving (AD). Despite rapid advancements in RL and AD, a systematic description and interpretation of the RL design process tailored to diverse driving tasks remains underdeveloped. This survey provides a comprehensive review of RL-based MoP for AD, focusing on lessons from task-specific perspectives. We first outline the fundamentals of RL methodologies, and then survey their applications in MoP, analyzing scenario-specific features and task requirements to shed light on their influence on RL design choices. Building on this analysis, we summarize key design experiences, extract insights from various driving task applications, and provide guidance for future implementations. Additionally, we examine the frontier challenges in RL-based MoP, review recent efforts to addresse these challenges, and propose strategies for overcoming unresolved issues.
Risk-Aware Reinforcement Learning for Autonomous Driving: Improving Safety When Driving through Intersection
Mar 27, 2025Applying reinforcement learning to autonomous driving has garnered widespread attention. However, classical reinforcement learning methods optimize policies by maximizing expected rewards but lack sufficient safety considerations, often putting agents in hazardous situations. This paper proposes a risk-aware reinforcement learning approach for autonomous driving to improve the safety performance when crossing the intersection. Safe critics are constructed to evaluate driving risk and work in conjunction with the reward critic to update the actor. Based on this, a Lagrangian relaxation method and cyclic gradient iteration are combined to project actions into a feasible safe region. Furthermore, a Multi-hop and Multi-layer perception (MLP) mixed Attention Mechanism (MMAM) is incorporated into the actor-critic network, enabling the policy to adapt to dynamic traffic and overcome permutation sensitivity challenges. This allows the policy to focus more effectively on surrounding potential risks while enhancing the identification of passing opportunities. Simulation tests are conducted on different tasks at unsignalized intersections. The results show that the proposed approach effectively reduces collision rates and improves crossing efficiency in comparison to baseline algorithms. Additionally, our ablation experiments demonstrate the benefits of incorporating risk-awareness and MMAM into RL.
PUGS: Zero-shot Physical Understanding with Gaussian Splatting
Feb 17, 2025
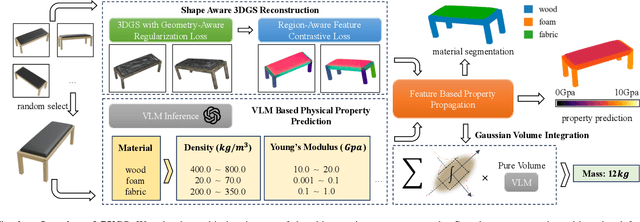


Current robotic systems can understand the categories and poses of objects well. But understanding physical properties like mass, friction, and hardness, in the wild, remains challenging. We propose a new method that reconstructs 3D objects using the Gaussian splatting representation and predicts various physical properties in a zero-shot manner. We propose two techniques during the reconstruction phase: a geometry-aware regularization loss function to improve the shape quality and a region-aware feature contrastive loss function to promote region affinity. Two other new techniques are designed during inference: a feature-based property propagation module and a volume integration module tailored for the Gaussian representation. Our framework is named as zero-shot physical understanding with Gaussian splatting, or PUGS. PUGS achieves new state-of-the-art results on the standard benchmark of ABO-500 mass prediction. We provide extensive quantitative ablations and qualitative visualization to demonstrate the mechanism of our designs. We show the proposed methodology can help address challenging real-world grasping tasks. Our codes, data, and models are available at https://github.com/EverNorif/PUGS
Depth Restoration of Hand-Held Transparent Objects for Human-to-Robot Handover
Aug 27, 2024



Transparent objects are common in daily life, while their unique optical properties pose challenges for RGB-D cameras, which struggle to capture accurate depth information. For assistant robots, accurately perceiving transparent objects held by humans is essential for effective human-robot interaction. This paper presents a Hand-Aware Depth Restoration (HADR) method for hand-held transparent objects based on creating an implicit neural representation function from a single RGB-D image. The proposed method introduces the hand posture as an important guidance to leverage semantic and geometric information. To train and evaluate the proposed method, we create a high-fidelity synthetic dataset called TransHand-14K with a real-to-sim data generation scheme. Experiments show that our method has a better performance and generalization ability compared with existing methods. We further develop a real-world human-to-robot handover system based on the proposed depth restoration method, demonstrating its application value in human-robot interaction.
Utilizing Large Language Models for Named Entity Recognition in Traditional Chinese Medicine against COVID-19 Literature: Comparative Study
Aug 24, 2024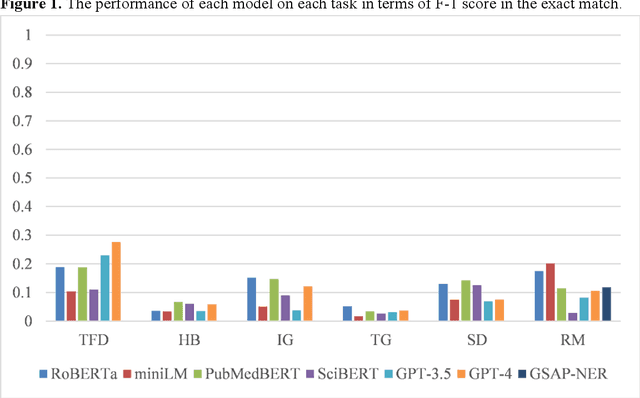
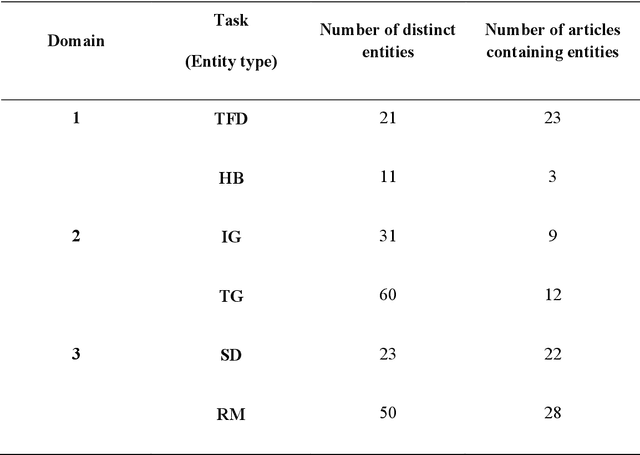
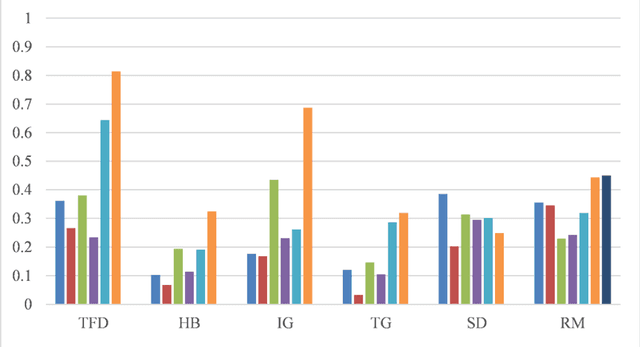
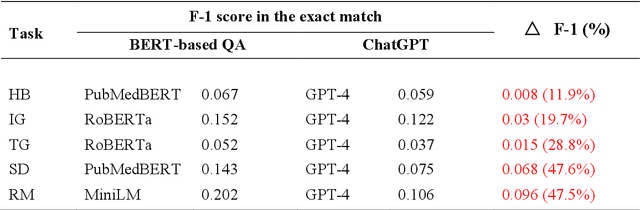
Objective: To explore and compare the performance of ChatGPT and other state-of-the-art LLMs on domain-specific NER tasks covering different entity types and domains in TCM against COVID-19 literature. Methods: We established a dataset of 389 articles on TCM against COVID-19, and manually annotated 48 of them with 6 types of entities belonging to 3 domains as the ground truth, against which the NER performance of LLMs can be assessed. We then performed NER tasks for the 6 entity types using ChatGPT (GPT-3.5 and GPT-4) and 4 state-of-the-art BERT-based question-answering (QA) models (RoBERTa, MiniLM, PubMedBERT and SciBERT) without prior training on the specific task. A domain fine-tuned model (GSAP-NER) was also applied for a comprehensive comparison. Results: The overall performance of LLMs varied significantly in exact match and fuzzy match. In the fuzzy match, ChatGPT surpassed BERT-based QA models in 5 out of 6 tasks, while in exact match, BERT-based QA models outperformed ChatGPT in 5 out of 6 tasks but with a smaller F-1 difference. GPT-4 showed a significant advantage over other models in fuzzy match, especially on the entity type of TCM formula and the Chinese patent drug (TFD) and ingredient (IG). Although GPT-4 outperformed BERT-based models on entity type of herb, target, and research method, none of the F-1 scores exceeded 0.5. GSAP-NER, outperformed GPT-4 in terms of F-1 by a slight margin on RM. ChatGPT achieved considerably higher recalls than precisions, particularly in the fuzzy match. Conclusions: The NER performance of LLMs is highly dependent on the entity type, and their performance varies across application scenarios. ChatGPT could be a good choice for scenarios where high recall is favored. However, for knowledge acquisition in rigorous scenarios, neither ChatGPT nor BERT-based QA models are off-the-shelf tools for professional practitioners.
SATac: A Thermoluminescence Enabled Tactile Sensor for Concurrent Perception of Temperature, Pressure, and Shear
Feb 01, 2024
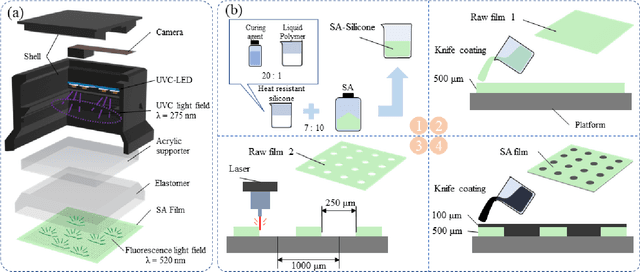


Most vision-based tactile sensors use elastomer deformation to infer tactile information, which can not sense some modalities, like temperature. As an important part of human tactile perception, temperature sensing can help robots better interact with the environment. In this work, we propose a novel multimodal vision-based tactile sensor, SATac, which can simultaneously perceive information of temperature, pressure, and shear. SATac utilizes thermoluminescence of strontium aluminate (SA) to sense a wide range of temperatures with exceptional resolution. Additionally, the pressure and shear can also be perceived by analyzing Voronoi diagram. A series of experiments are conducted to verify the performance of our proposed sensor. We also discuss the possible application scenarios and demonstrate how SATac could benefit robot perception capabilities.
Growing from Exploration: A self-exploring framework for robots based on foundation models
Jan 24, 2024



Intelligent robot is the ultimate goal in the robotics field. Existing works leverage learning-based or optimization-based methods to accomplish human-defined tasks. However, the challenge of enabling robots to explore various environments autonomously remains unresolved. In this work, we propose a framework named GExp, which enables robots to explore and learn autonomously without human intervention. To achieve this goal, we devise modules including self-exploration, knowledge-base-building, and close-loop feedback based on foundation models. Inspired by the way that infants interact with the world, GExp encourages robots to understand and explore the environment with a series of self-generated tasks. During the process of exploration, the robot will acquire skills from beneficial experiences that are useful in the future. GExp provides robots with the ability to solve complex tasks through self-exploration. GExp work is independent of prior interactive knowledge and human intervention, allowing it to adapt directly to different scenarios, unlike previous studies that provided in-context examples as few-shot learning. In addition, we propose a workflow of deploying the real-world robot system with self-learned skills as an embodied assistant.
Creating Knowledge Graphs for Geographic Data on the Web
Feb 17, 2023

Geographic data plays an essential role in various Web, Semantic Web and machine learning applications. OpenStreetMap and knowledge graphs are critical complementary sources of geographic data on the Web. However, data veracity, the lack of integration of geographic and semantic characteristics, and incomplete representations substantially limit the data utility. Verification, enrichment and semantic representation are essential for making geographic data accessible for the Semantic Web and machine learning. This article describes recent approaches we developed to tackle these challenges.