 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaSER: Language-Specific Event Recommendation
Feb 24, 2023
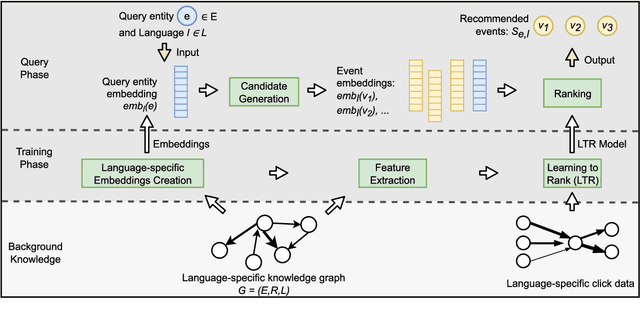
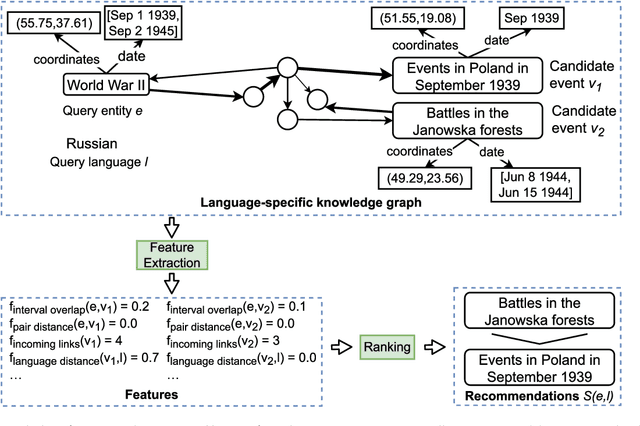

While societal events often impact people worldwide, a significant fraction of events has a local focus that primarily affects specific language communities. Examples include national elections, the development of the Coronavirus pandemic in different countries, and local film festivals such as the C\'esar Awards in France and the Moscow International Film Festival in Russia. However, existing entity recommendation approaches do not sufficiently address the language context of recommendation. This article introduces the novel task of language-specific event recommendation, which aims to recommend events relevant to the user query in the language-specific context. This task can support essential information retrieval activities, including web navigation and exploratory search, considering the language context of user information needs. We propose LaSER, a novel approach toward language-specific event recommendation. LaSER blends the language-specific latent representations (embeddings) of entities and events and spatio-temporal event features in a learning to rank model. This model is trained on publicly available Wikipedia Clickstream data. The results of our user study demonstrate that LaSER outperforms state-of-the-art recommendation baselines by up to 33 percentage points in MAP@5 concerning the language-specific relevance of recommended events.
Creating Knowledge Graphs for Geographic Data on the Web
Feb 17, 2023

Geographic data plays an essential role in various Web, Semantic Web and machine learning applications. OpenStreetMap and knowledge graphs are critical complementary sources of geographic data on the Web. However, data veracity, the lack of integration of geographic and semantic characteristics, and incomplete representations substantially limit the data utility. Verification, enrichment and semantic representation are essential for making geographic data accessible for the Semantic Web and machine learning. This article describes recent approaches we developed to tackle these challenges.
Tab2KG: Semantic Table Interpretation with Lightweight Semantic Profiles
Feb 02, 2023Tabular data plays an essential role in many data analytics and machine learning tasks. Typically, tabular data does not possess any machine-readable semantics. In this context, semantic table interpretation is crucial for making data analytics workflows more robust and explainable. This article proposes Tab2KG - a novel method that targets at the interpretation of tables with previously unseen data and automatically infers their semantics to transform them into semantic data graphs. We introduce original lightweight semantic profiles that enrich a domain ontology's concepts and relations and represent domain and table characteristics. We propose a one-shot learning approach that relies on these profiles to map a tabular dataset containing previously unseen instances to a domain ontology. In contrast to the existing semantic table interpretation approaches, Tab2KG relies on the semantic profiles only and does not require any instance lookup. This property makes Tab2KG particularly suitable in the data analytics context, in which data tables typically contain new instances. Our experimental evaluation on several real-world datasets from different application domains demonstrates that Tab2KG outperforms state-of-the-art semantic table interpretation baselines.
QuoteKG: A Multilingual Knowledge Graph of Quotes
Jul 19, 2022Quotes of public figures can mark turning points in history. A quote can explain its originator's actions, foreshadowing political or personal decisions and revealing character traits. Impactful quotes cross language barriers and influence the general population's reaction to specific stances, always facing the risk of being misattributed or taken out of context. The provision of a cross-lingual knowledge graph of quotes that establishes the authenticity of quotes and their contexts is of great importance to allow the exploration of the lives of important people as well as topics from the perspective of what was actually said. In this paper, we present QuoteKG, the first multilingual knowledge graph of quotes. We propose the QuoteKG creation pipeline that extracts quotes from Wikiquote, a free and collaboratively created collection of quotes in many languages, and aligns different mentions of the same quote. QuoteKG includes nearly one million quotes in $55$ languages, said by more than $69,000$ people of public interest across a wide range of topics. QuoteKG is publicly available and can be accessed via a SPARQL endpoint.
Reinforcement Learning-based Placement of Charging Stations in Urban Road Networks
Jun 13, 2022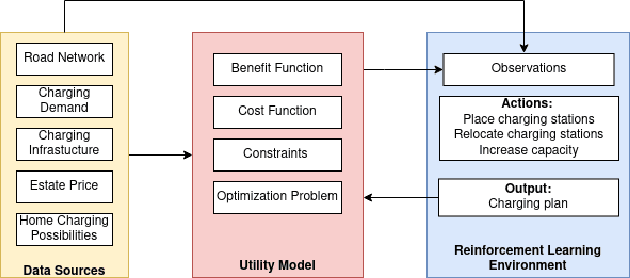

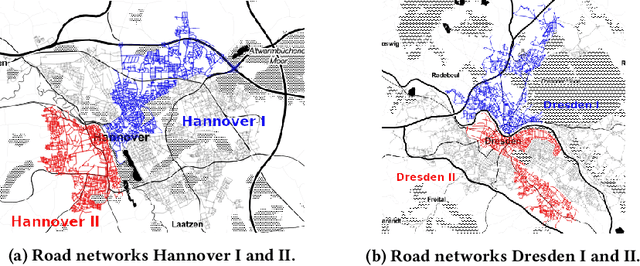
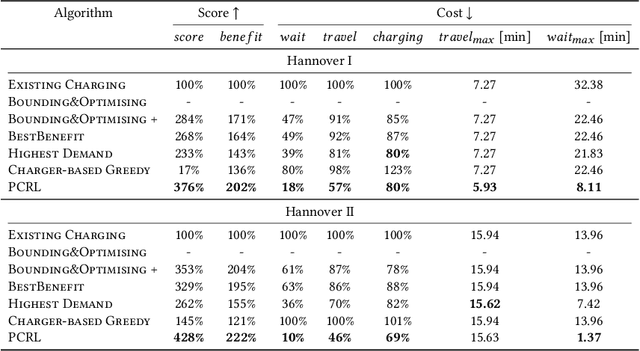
The transition from conventional mobility to electromobility largely depends on charging infrastructure availability and optimal placement.This paper examines the optimal placement of charging stations in urban areas. We maximise the charging infrastructure supply over the area and minimise waiting, travel, and charging times while setting budget constraints. Moreover, we include the possibility of charging vehicles at home to obtain a more refined estimation of the actual charging demand throughout the urban area. We formulate the Placement of Charging Stations problem as a non-linear integer optimisation problem that seeks the optimal positions for charging stations and the optimal number of charging piles of different charging types. We design a novel Deep Reinforcement Learning approach to solve the charging station placement problem (PCRL). Extensive experiments on real-world datasets show how the PCRL reduces the waiting and travel time while increasing the benefit of the charging plan compared to five baselines. Compared to the existing infrastructure, we can reduce the waiting time by up to 97% and increase the benefit up to 497%.
Ovid: A Machine Learning Approach for Automated Vandalism Detection in OpenStreetMap
Mar 21, 2022
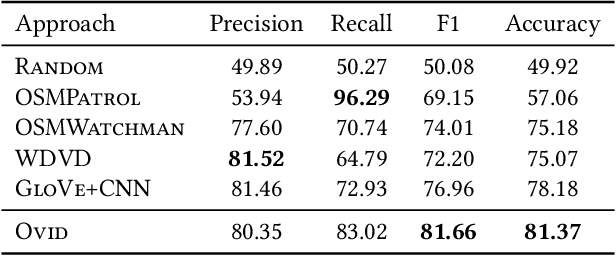
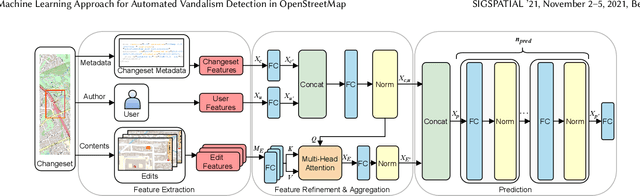
OpenStreetMap is a unique source of openly available worldwide map data, increasingly adopted in real-world applications. Vandalism detection in OpenStreetMap is critical and remarkably challenging due to the large scale of the dataset, the sheer number of contributors, various vandalism forms, and the lack of annotated data to train machine learning algorithms. This paper presents Ovid - a novel machine learning method for vandalism detection in OpenStreetMap. Ovid relies on a neural network architecture that adopts a multi-head attention mechanism to effectively summarize information indicating vandalism from OpenStreetMap changesets. To facilitate automated vandalism detection, we introduce a set of original features that capture changeset, user, and edit information. Our evaluation results on real-world vandalism data demonstrate that the proposed Ovid method outperforms the baselines by 4.7 percentage points in F1 score.
* arXiv admin note: substantial text overlap with arXiv:2201.10406
Attention-Based Vandalism Detection in OpenStreetMap
Jan 25, 2022
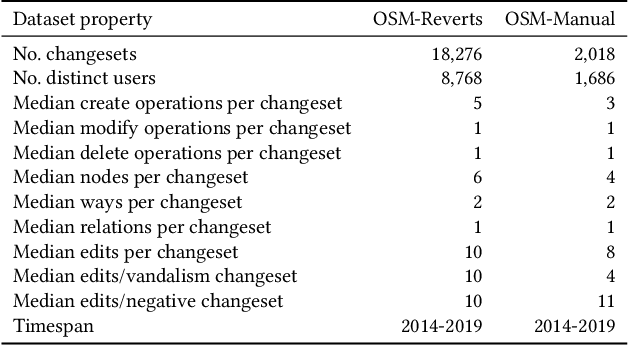
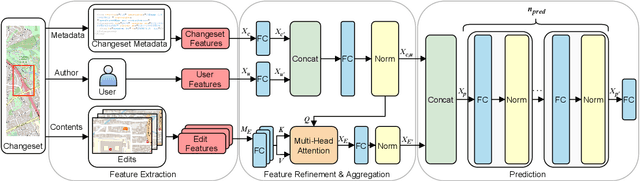
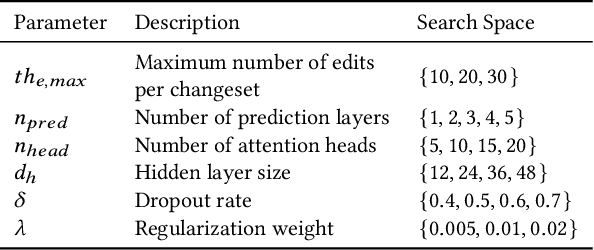
OpenStreetMap (OSM), a collaborative, crowdsourced Web map, is a unique source of openly available worldwide map data, increasingly adopted in Web applications. Vandalism detection is a critical task to support trust and maintain OSM transparency. This task is remarkably challenging due to the large scale of the dataset, the sheer number of contributors, various vandalism forms, and the lack of annotated data. This paper presents Ovid - a novel attention-based method for vandalism detection in OSM. Ovid relies on a novel neural architecture that adopts a multi-head attention mechanism to summarize information indicating vandalism from OSM changesets effectively. To facilitate automated vandalism detection, we introduce a set of original features that capture changeset, user, and edit information. Furthermore, we extract a dataset of real-world vandalism incidents from the OSM edit history for the first time and provide this dataset as open data. Our evaluation conducted on real-world vandalism data demonstrates the effectiveness of Ovid.
WorldKG: A World-Scale Geographic Knowledge Graph
Sep 21, 2021
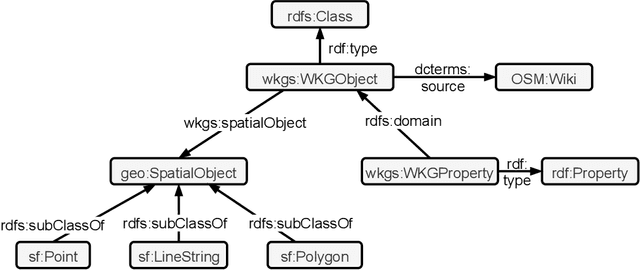
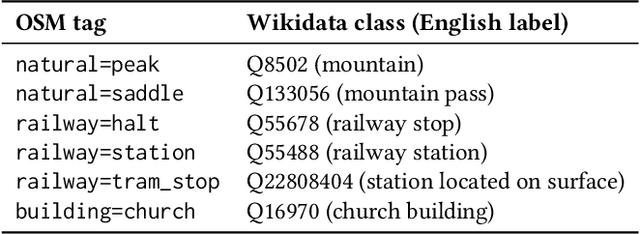
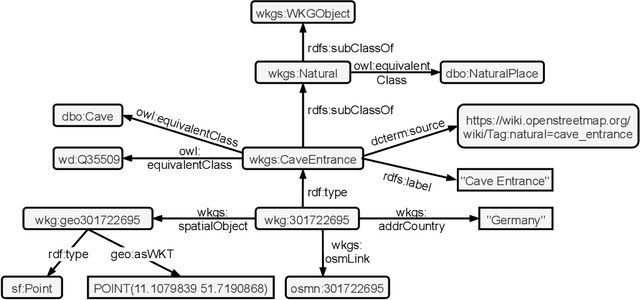
OpenStreetMap is a rich source of openly available geographic information. However, the representation of geographic entities, e.g., buildings, mountains, and cities, within OpenStreetMap is highly heterogeneous, diverse, and incomplete. As a result, this rich data source is hardly usable for real-world applications. This paper presents WorldKG -- a new geographic knowledge graph aiming to provide a comprehensive semantic representation of geographic entities in OpenStreetMap. We describe the WorldKG knowledge graph, including its ontology that builds the semantic dataset backbone, the extraction procedure of the ontology and geographic entities from OpenStreetMap, and the methods to enhance entity annotation. We perform statistical and qualitative dataset assessment, demonstrating the large scale and high precision of the semantic geographic information in WorldKG.
GeoVectors: A Linked Open Corpus of OpenStreetMap Embeddings on World Scale
Aug 30, 2021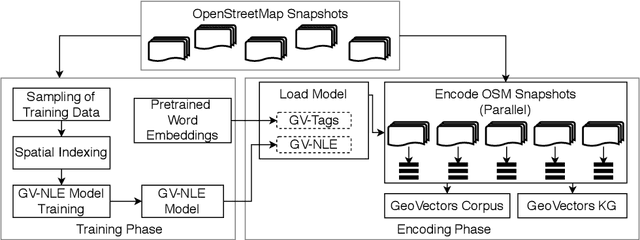
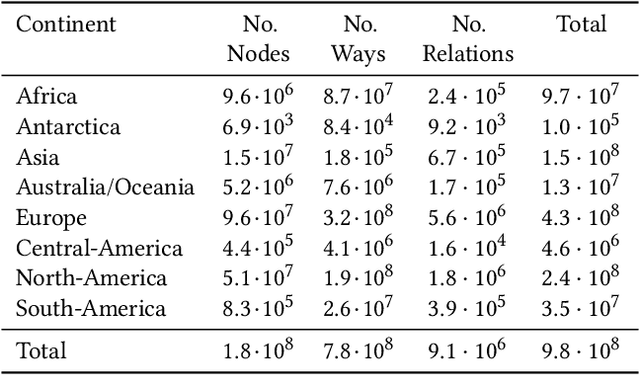
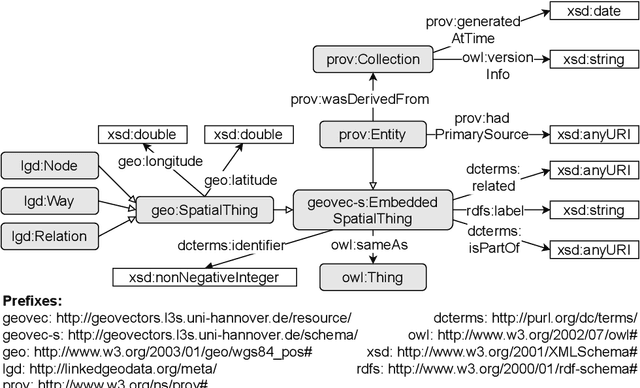

OpenStreetMap (OSM) is currently the richest publicly available information source on geographic entities (e.g., buildings and roads) worldwide. However, using OSM entities in machine learning models and other applications is challenging due to the large scale of OSM, the extreme heterogeneity of entity annotations, and a lack of a well-defined ontology to describe entity semantics and properties. This paper presents GeoVectors - a unique, comprehensive world-scale linked open corpus of OSM entity embeddings covering the entire OSM dataset and providing latent representations of over 980 million geographic entities in 180 countries. The GeoVectors corpus captures semantic and geographic dimensions of OSM entities and makes these entities directly accessible to machine learning algorithms and semantic applications. We create a semantic description of the GeoVectors corpus, including identity links to the Wikidata and DBpedia knowledge graphs to supply context information. Furthermore, we provide a SPARQL endpoint - a semantic interface that offers direct access to the semantic and latent representations of geographic entities in OSM.
Deep Information Fusion for Electric Vehicle Charging Station Occupancy Forecasting
Aug 27, 2021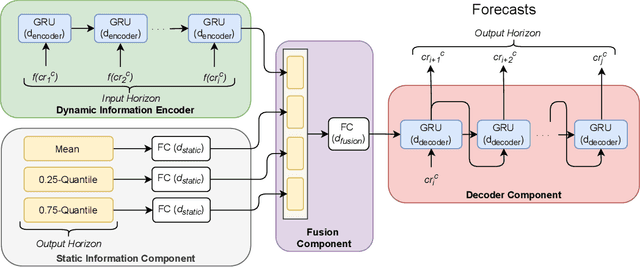
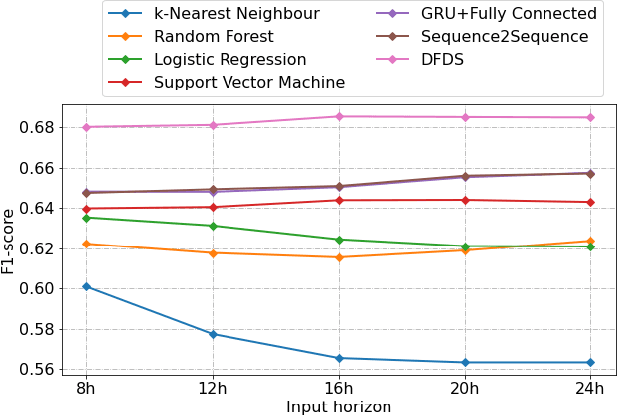
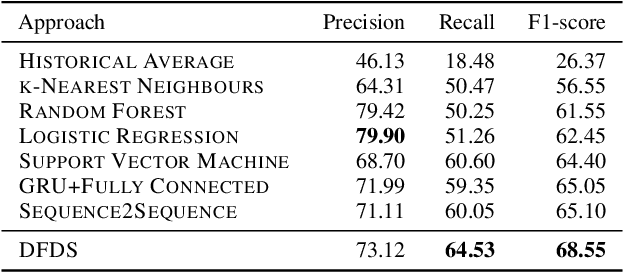
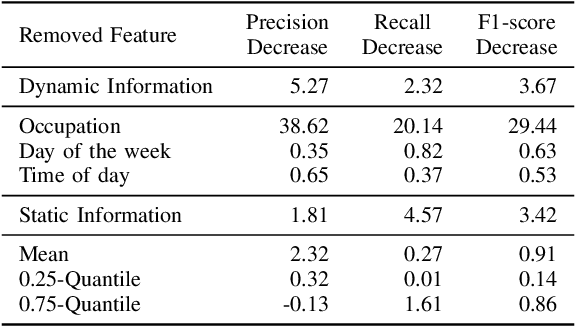
With an increasing number of electric vehicles, the accurate forecasting of charging station occupation is crucial to enable reliable vehicle charging. This paper introduces a novel Deep Fusion of Dynamic and Static Information model (DFDS) to effectively forecast the charging station occupation. We exploit static information, such as the mean occupation concerning the time of day, to learn the specific charging station patterns. We supplement such static data with dynamic information reflecting the preceding charging station occupation and temporal information such as daytime and weekday. Our model efficiently fuses dynamic and static information to facilitate accurate forecasting. We evaluate the proposed model on a real-world dataset containing 593 charging stations in Germany, covering August 2020 to December 2020. Our experiments demonstrate that DFDS outperforms the baselines by 3.45 percent points in F1-score on average.