 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating Knowledge Graphs for Geographic Data on the Web
Feb 17, 2023

Geographic data plays an essential role in various Web, Semantic Web and machine learning applications. OpenStreetMap and knowledge graphs are critical complementary sources of geographic data on the Web. However, data veracity, the lack of integration of geographic and semantic characteristics, and incomplete representations substantially limit the data utility. Verification, enrichment and semantic representation are essential for making geographic data accessible for the Semantic Web and machine learning. This article describes recent approaches we developed to tackle these challenges.
Reinforcement Learning-based Placement of Charging Stations in Urban Road Networks
Jun 13, 2022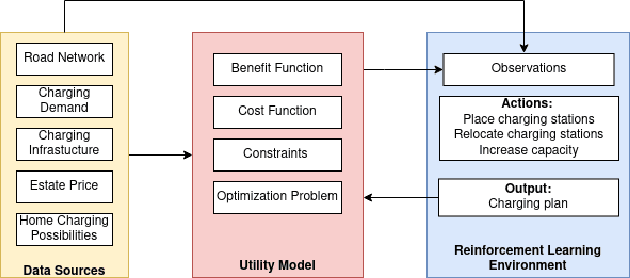

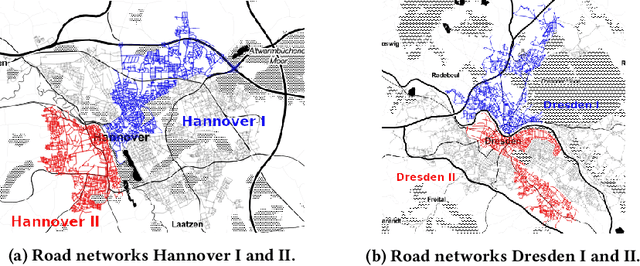
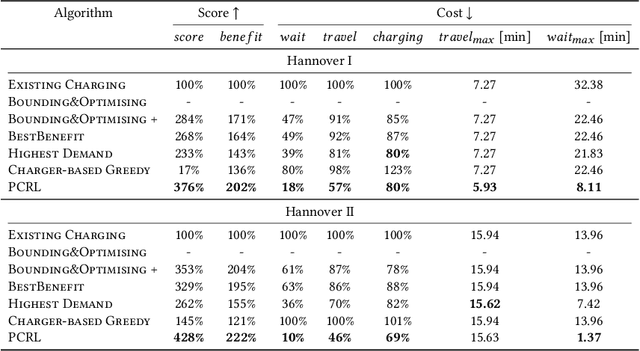
The transition from conventional mobility to electromobility largely depends on charging infrastructure availability and optimal placement.This paper examines the optimal placement of charging stations in urban areas. We maximise the charging infrastructure supply over the area and minimise waiting, travel, and charging times while setting budget constraints. Moreover, we include the possibility of charging vehicles at home to obtain a more refined estimation of the actual charging demand throughout the urban area. We formulate the Placement of Charging Stations problem as a non-linear integer optimisation problem that seeks the optimal positions for charging stations and the optimal number of charging piles of different charging types. We design a novel Deep Reinforcement Learning approach to solve the charging station placement problem (PCRL). Extensive experiments on real-world datasets show how the PCRL reduces the waiting and travel time while increasing the benefit of the charging plan compared to five baselines. Compared to the existing infrastructure, we can reduce the waiting time by up to 97% and increase the benefit up to 497%.
Ovid: A Machine Learning Approach for Automated Vandalism Detection in OpenStreetMap
Mar 21, 2022
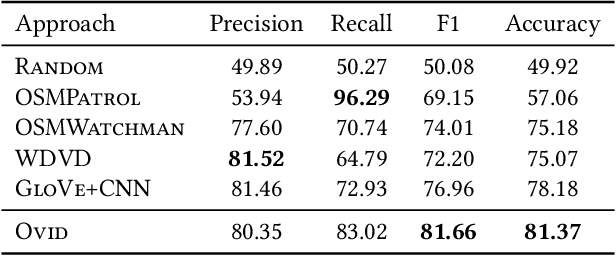
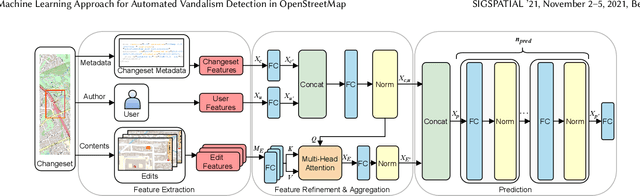
OpenStreetMap is a unique source of openly available worldwide map data, increasingly adopted in real-world applications. Vandalism detection in OpenStreetMap is critical and remarkably challenging due to the large scale of the dataset, the sheer number of contributors, various vandalism forms, and the lack of annotated data to train machine learning algorithms. This paper presents Ovid - a novel machine learning method for vandalism detection in OpenStreetMap. Ovid relies on a neural network architecture that adopts a multi-head attention mechanism to effectively summarize information indicating vandalism from OpenStreetMap changesets. To facilitate automated vandalism detection, we introduce a set of original features that capture changeset, user, and edit information. Our evaluation results on real-world vandalism data demonstrate that the proposed Ovid method outperforms the baselines by 4.7 percentage points in F1 score.
* arXiv admin note: substantial text overlap with arXiv:2201.10406
Attention-Based Vandalism Detection in OpenStreetMap
Jan 25, 2022
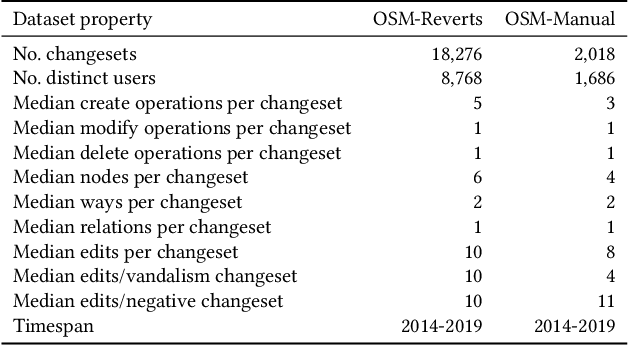
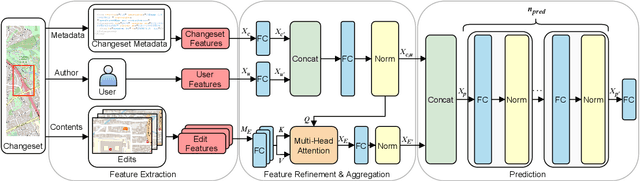
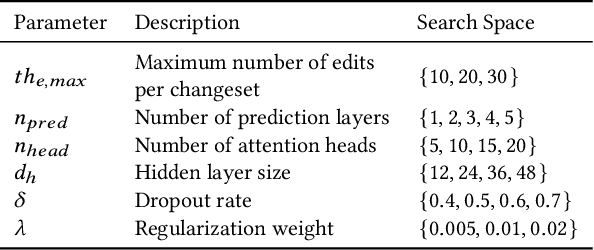
OpenStreetMap (OSM), a collaborative, crowdsourced Web map, is a unique source of openly available worldwide map data, increasingly adopted in Web applications. Vandalism detection is a critical task to support trust and maintain OSM transparency. This task is remarkably challenging due to the large scale of the dataset, the sheer number of contributors, various vandalism forms, and the lack of annotated data. This paper presents Ovid - a novel attention-based method for vandalism detection in OSM. Ovid relies on a novel neural architecture that adopts a multi-head attention mechanism to summarize information indicating vandalism from OSM changesets effectively. To facilitate automated vandalism detection, we introduce a set of original features that capture changeset, user, and edit information. Furthermore, we extract a dataset of real-world vandalism incidents from the OSM edit history for the first time and provide this dataset as open data. Our evaluation conducted on real-world vandalism data demonstrates the effectiveness of Ovid.
WorldKG: A World-Scale Geographic Knowledge Graph
Sep 21, 2021
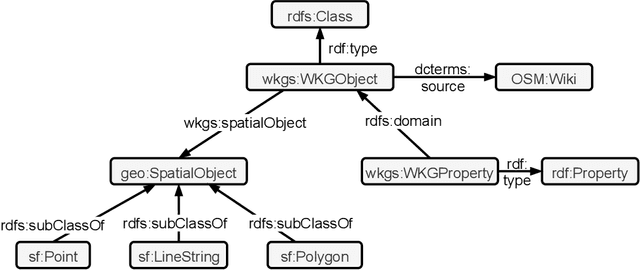
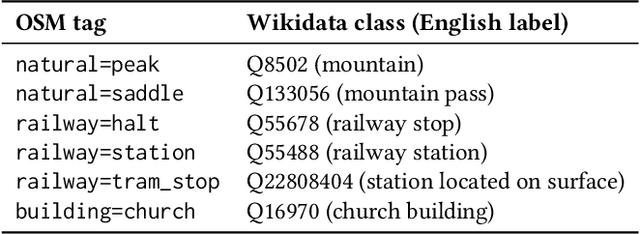
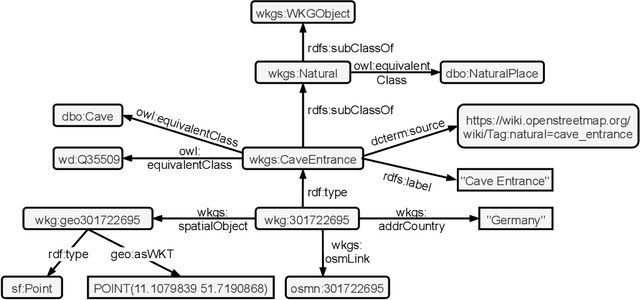
OpenStreetMap is a rich source of openly available geographic information. However, the representation of geographic entities, e.g., buildings, mountains, and cities, within OpenStreetMap is highly heterogeneous, diverse, and incomplete. As a result, this rich data source is hardly usable for real-world applications. This paper presents WorldKG -- a new geographic knowledge graph aiming to provide a comprehensive semantic representation of geographic entities in OpenStreetMap. We describe the WorldKG knowledge graph, including its ontology that builds the semantic dataset backbone, the extraction procedure of the ontology and geographic entities from OpenStreetMap, and the methods to enhance entity annotation. We perform statistical and qualitative dataset assessment, demonstrating the large scale and high precision of the semantic geographic information in WorldKG.
GeoVectors: A Linked Open Corpus of OpenStreetMap Embeddings on World Scale
Aug 30, 2021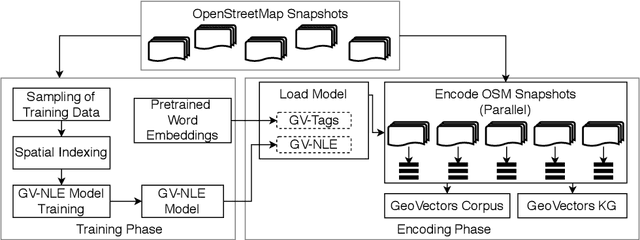
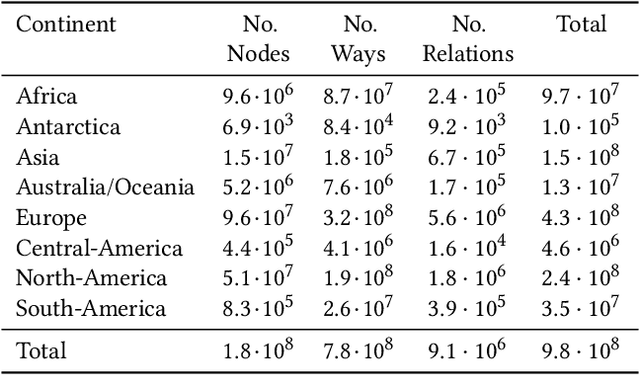
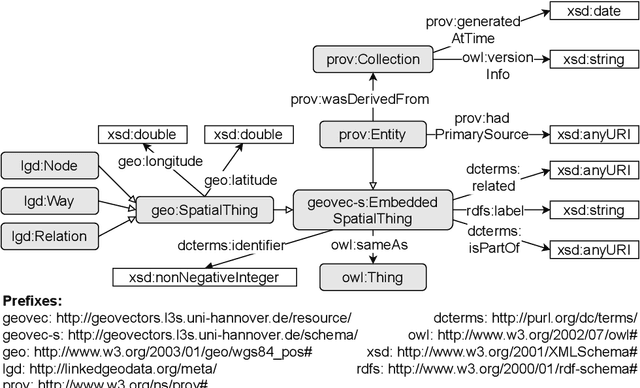

OpenStreetMap (OSM) is currently the richest publicly available information source on geographic entities (e.g., buildings and roads) worldwide. However, using OSM entities in machine learning models and other applications is challenging due to the large scale of OSM, the extreme heterogeneity of entity annotations, and a lack of a well-defined ontology to describe entity semantics and properties. This paper presents GeoVectors - a unique, comprehensive world-scale linked open corpus of OSM entity embeddings covering the entire OSM dataset and providing latent representations of over 980 million geographic entities in 180 countries. The GeoVectors corpus captures semantic and geographic dimensions of OSM entities and makes these entities directly accessible to machine learning algorithms and semantic applications. We create a semantic description of the GeoVectors corpus, including identity links to the Wikidata and DBpedia knowledge graphs to supply context information. Furthermore, we provide a SPARQL endpoint - a semantic interface that offers direct access to the semantic and latent representations of geographic entities in OSM.
Deep Information Fusion for Electric Vehicle Charging Station Occupancy Forecasting
Aug 27, 2021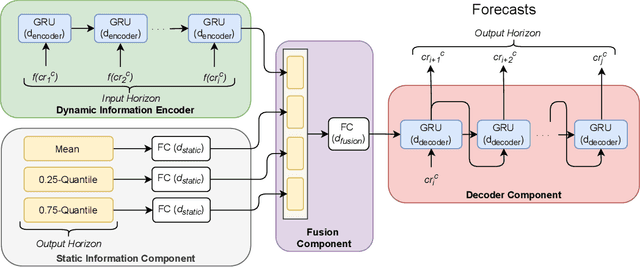
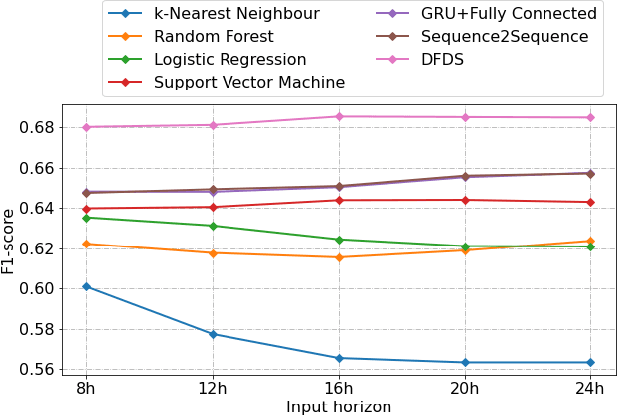
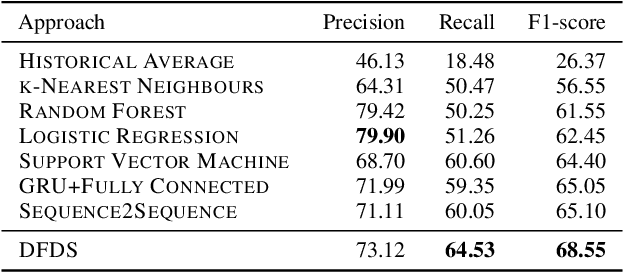
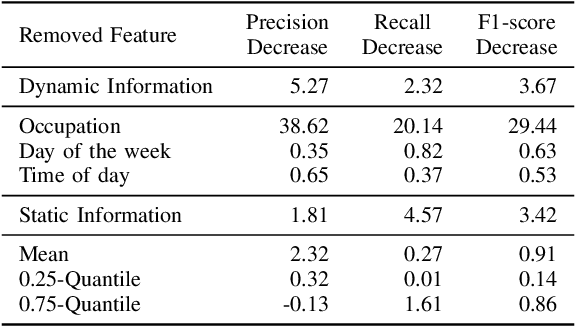
With an increasing number of electric vehicles, the accurate forecasting of charging station occupation is crucial to enable reliable vehicle charging. This paper introduces a novel Deep Fusion of Dynamic and Static Information model (DFDS) to effectively forecast the charging station occupation. We exploit static information, such as the mean occupation concerning the time of day, to learn the specific charging station patterns. We supplement such static data with dynamic information reflecting the preceding charging station occupation and temporal information such as daytime and weekday. Our model efficiently fuses dynamic and static information to facilitate accurate forecasting. We evaluate the proposed model on a real-world dataset containing 593 charging stations in Germany, covering August 2020 to December 2020. Our experiments demonstrate that DFDS outperforms the baselines by 3.45 percent points in F1-score on average.
Towards Neural Schema Alignment for OpenStreetMap and Knowledge Graphs
Jul 28, 2021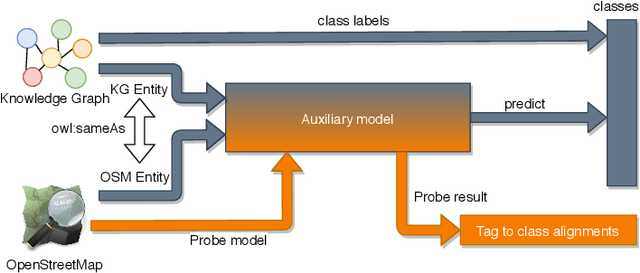
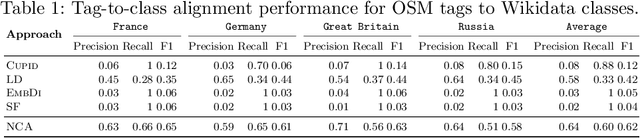


OpenStreetMap (OSM) is one of the richest openly available sources of volunteered geographic information. Although OSM includes various geographical entities, their descriptions are highly heterogeneous, incomplete, and do not follow any well-defined ontology. Knowledge graphs can potentially provide valuable semantic information to enrich OSM entities. However, interlinking OSM entities with knowledge graphs is inherently difficult due to the large, heterogeneous, ambiguous, and flat OSM schema and the annotation sparsity. This paper tackles the alignment of OSM tags with the corresponding knowledge graph classes holistically by jointly considering the schema and instance layers. We propose a novel neural architecture that capitalizes upon a shared latent space for tag-to-class alignment created using linked entities in OSM and knowledge graphs. Our experiments performed to align OSM datasets for several countries with two of the most prominent openly available knowledge graphs, namely, Wikidata and DBpedia, demonstrate that the proposed approach outperforms the state-of-the-art schema alignment baselines by up to 53 percentage points in terms of F1-score. The resulting alignment facilitates new semantic annotations for over 10 million OSM entities worldwide, which is more than a 400% increase compared to the existing semantic annotations in OSM.
Mining Topological Dependencies of Recurrent Congestion in Road Networks
Jul 20, 2021
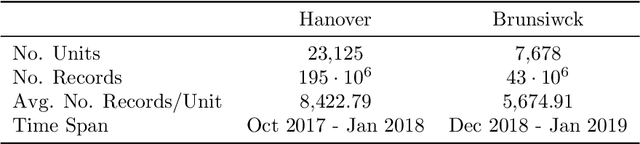
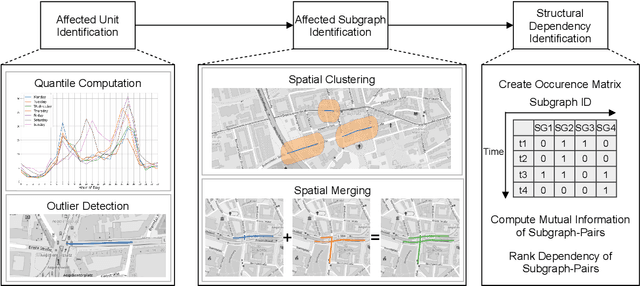
The discovery of spatio-temporal dependencies within urban road networks that cause Recurrent Congestion (RC) patterns is crucial for numerous real-world applications, including urban planning and scheduling of public transportation services. While most existing studies investigate temporal patterns of RC phenomena, the influence of the road network topology on RC is often overlooked. This article proposes the ST-Discovery algorithm, a novel unsupervised spatio-temporal data mining algorithm that facilitates the effective data-driven discovery of RC dependencies induced by the road network topology using real-world traffic data. We factor out regularly reoccurring traffic phenomena, such as rush hours, mainly induced by the daytime, by modelling and systematically exploiting temporal traffic load outliers. We present an algorithm that first constructs connected subgraphs of the road network based on the traffic speed outliers. Second, the algorithm identifies pairs of subgraphs that indicate spatio-temporal correlations in their traffic load behaviour to identify topological dependencies within the road network. Finally, we rank the identified subgraph pairs based on the dependency score determined by our algorithm. Our experimental results demonstrate that ST-Discovery can effectively reveal topological dependencies in urban road networks.
Linking OpenStreetMap with Knowledge Graphs -- Link Discovery for Schema-Agnostic Volunteered Geographic Information
Nov 06, 2020
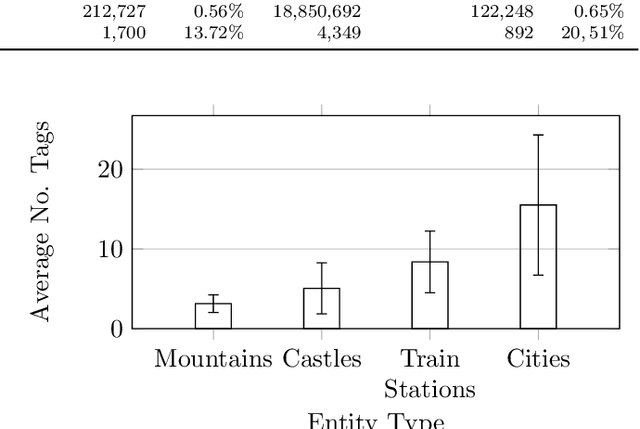
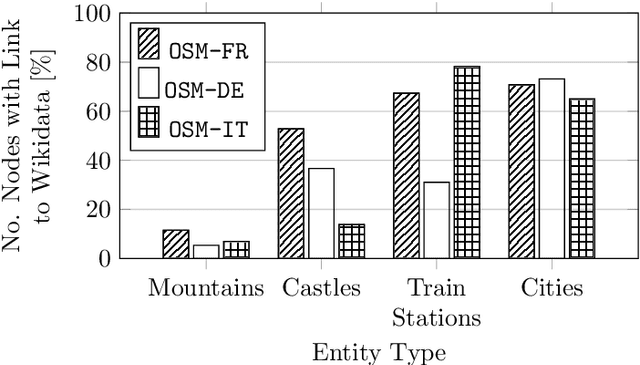
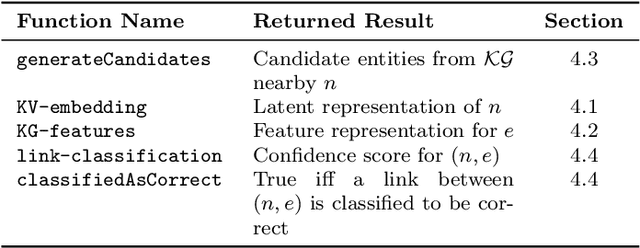
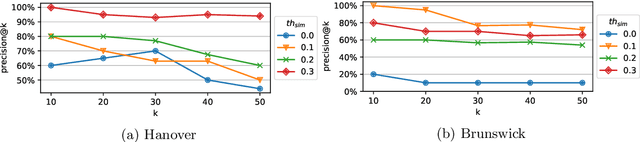
Representations of geographic entities captured in popular knowledge graphs such as Wikidata and DBpedia are often incomplete. OpenStreetMap (OSM) is a rich source of openly available volunteered geographic information that has a high potential to complement these representations. However, identity links between the knowledge graph entities and OSM nodes are still rare. The problem of link discovery in these settings is particularly challenging due to the lack of a strict schema and heterogeneity of the user-defined node representations in OSM. In this article, we propose OSM2KG -- a novel link discovery approach to predict identity links between OSM nodes and geographic entities in a knowledge graph. The core of the OSM2KG approach is a novel latent representation of OSM nodes that captures semantic node similarity in an embedding. OSM2KG adopts this latent representation to train a supervised model for link prediction and utilises existing links between OSM and knowledge graphs for training. Our experiments conducted on several OSM datasets as well as the Wikidata and DBpedia knowledge graphs demonstrate that OSM2KG can reliably discover identity links. OSM2KG significantly outperforms both na{\i}ve baselines and state-of-the-art link discovery approaches and achieves up to 22.45 percent points increase in F1 score compared to the best performing baselines.