 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Temporal Understanding in Video-LLMs through Stacked Temporal Attention in Vision Encoders
Oct 29, 2025Despite significant advances in Multimodal Large Language Models (MLLMs), understanding complex temporal dynamics in videos remains a major challenge. Our experiments show that current Video Large Language Model (Video-LLM) architectures have critical limitations in temporal understanding, struggling with tasks that require detailed comprehension of action sequences and temporal progression. In this work, we propose a Video-LLM architecture that introduces stacked temporal attention modules directly within the vision encoder. This design incorporates a temporal attention in vision encoder, enabling the model to better capture the progression of actions and the relationships between frames before passing visual tokens to the LLM. Our results show that this approach significantly improves temporal reasoning and outperforms existing models in video question answering tasks, specifically in action recognition. We improve on benchmarks including VITATECS, MVBench, and Video-MME by up to +5.5%. By enhancing the vision encoder with temporal structure, we address a critical gap in video understanding for Video-LLMs. Project page and code are available at: https://alirasekh.github.io/STAVEQ2/.
Reinforcement learning for online hyperparameter tuning in convex quadratic programming
Sep 09, 2025Quadratic programming is a workhorse of modern nonlinear optimization, control, and data science. Although regularized methods offer convergence guarantees under minimal assumptions on the problem data, they can exhibit the slow tail-convergence typical of first-order schemes, thus requiring many iterations to achieve high-accuracy solutions. Moreover, hyperparameter tuning significantly impacts on the solver performance but how to find an appropriate parameter configuration remains an elusive research question. To address these issues, we explore how data-driven approaches can accelerate the solution process. Aiming at high-accuracy solutions, we focus on a stabilized interior-point solver and carefully handle its two-loop flow and control parameters. We will show that reinforcement learning can make a significant contribution to facilitating the solver tuning and to speeding up the optimization process. Numerical experiments demonstrate that, after a lightweight training, the learned policy generalizes well to different problem classes with varying dimensions and to various solver configurations.
Multi-Rationale Explainable Object Recognition via Contrastive Conditional Inference
Aug 19, 2025Explainable object recognition using vision-language models such as CLIP involves predicting accurate category labels supported by rationales that justify the decision-making process. Existing methods typically rely on prompt-based conditioning, which suffers from limitations in CLIP's text encoder and provides weak conditioning on explanatory structures. Additionally, prior datasets are often restricted to single, and frequently noisy, rationales that fail to capture the full diversity of discriminative image features. In this work, we introduce a multi-rationale explainable object recognition benchmark comprising datasets in which each image is annotated with multiple ground-truth rationales, along with evaluation metrics designed to offer a more comprehensive representation of the task. To overcome the limitations of previous approaches, we propose a contrastive conditional inference (CCI) framework that explicitly models the probabilistic relationships among image embeddings, category labels, and rationales. Without requiring any training, our framework enables more effective conditioning on rationales to predict accurate object categories. Our approach achieves state-of-the-art results on the multi-rationale explainable object recognition benchmark, including strong zero-shot performance, and sets a new standard for both classification accuracy and rationale quality. Together with the benchmark, this work provides a more complete framework for evaluating future models in explainable object recognition. The code will be made available online.
Trajectory Representation Learning on Road Networks and Grids with Spatio-Temporal Dynamics
Nov 21, 2024

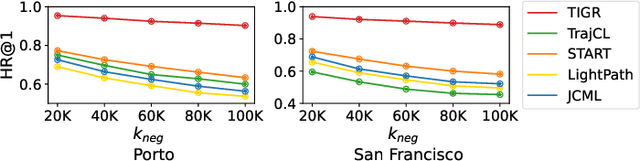

Trajectory representation learning is a fundamental task for applications in fields including smart city, and urban planning, as it facilitates the utilization of trajectory data (e.g., vehicle movements) for various downstream applications, such as trajectory similarity computation or travel time estimation. This is achieved by learning low-dimensional representations from high-dimensional and raw trajectory data. However, existing methods for trajectory representation learning either rely on grid-based or road-based representations, which are inherently different and thus, could lose information contained in the other modality. Moreover, these methods overlook the dynamic nature of urban traffic, relying on static road network features rather than time varying traffic patterns. In this paper, we propose TIGR, a novel model designed to integrate grid and road network modalities while incorporating spatio-temporal dynamics to learn rich, general-purpose representations of trajectories. We evaluate TIGR on two realworld datasets and demonstrate the effectiveness of combining both modalities by substantially outperforming state-of-the-art methods, i.e., up to 43.22% for trajectory similarity, up to 16.65% for travel time estimation, and up to 10.16% for destination prediction.
Aligning Visual Contrastive learning models via Preference Optimization
Nov 12, 2024Contrastive learning models have demonstrated impressive abilities to capture semantic similarities by aligning representations in the embedding space. However, their performance can be limited by the quality of the training data and its inherent biases. While Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) have been applied to generative models to align them with human preferences, their use in contrastive learning has yet to be explored. This paper introduces a novel method for training contrastive learning models using Preference Optimization (PO) to break down complex concepts. Our method systematically aligns model behavior with desired preferences, enhancing performance on the targeted task. In particular, we focus on enhancing model robustness against typographic attacks, commonly seen in contrastive models like CLIP. We further apply our method to disentangle gender understanding and mitigate gender biases, offering a more nuanced control over these sensitive attributes. Our experiments demonstrate that models trained using PO outperform standard contrastive learning techniques while retaining their ability to handle adversarial challenges and maintain accuracy on other downstream tasks. This makes our method well-suited for tasks requiring fairness, robustness, and alignment with specific preferences. We evaluate our method on several vision-language tasks, tackling challenges such as typographic attacks. Additionally, we explore the model's ability to disentangle gender concepts and mitigate gender bias, showcasing the versatility of our approach.
Spatially Constrained Transformer with Efficient Global Relation Modelling for Spatio-Temporal Prediction
Nov 11, 2024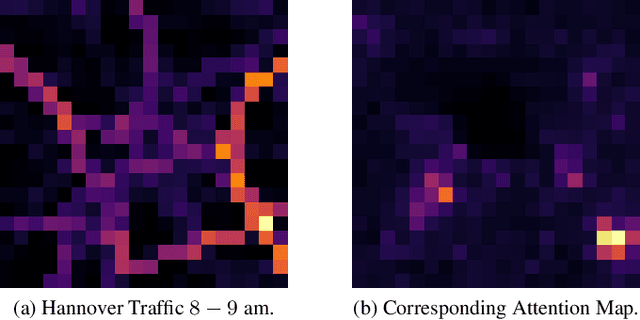
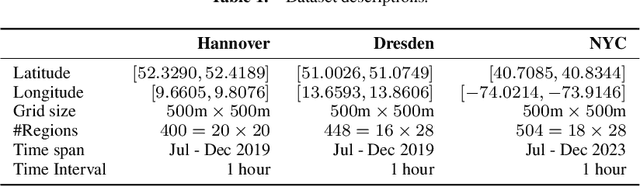
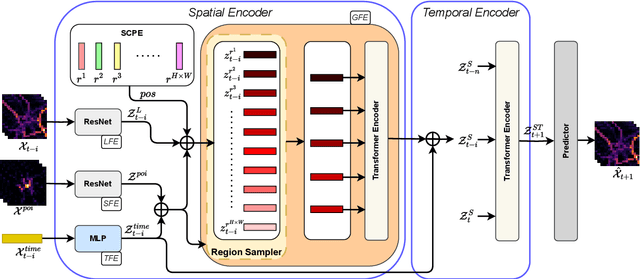

Accurate spatio-temporal prediction is crucial for the sustainable development of smart cities. However, current approaches often struggle to capture important spatio-temporal relationships, particularly overlooking global relations among distant city regions. Most existing techniques predominantly rely on Convolutional Neural Networks (CNNs) to capture global relations. However, CNNs exhibit neighbourhood bias, making them insufficient for capturing distant relations. To address this limitation, we propose ST-SampleNet, a novel transformer-based architecture that combines CNNs with self-attention mechanisms to capture both local and global relations effectively. Moreover, as the number of regions increases, the quadratic complexity of self-attention becomes a challenge. To tackle this issue, we introduce a lightweight region sampling strategy that prunes non-essential regions and enhances the efficiency of our approach. Furthermore, we introduce a spatially constrained position embedding that incorporates spatial neighbourhood information into the self-attention mechanism, aiding in semantic interpretation and improving the performance of ST-SampleNet. Our experimental evaluation on three real-world datasets demonstrates the effectiveness of ST-SampleNet. Additionally, our efficient variant achieves a 40% reduction in computational costs with only a marginal compromise in performance, approximately 1%.
FlexTSF: A Universal Forecasting Model for Time Series with Variable Regularities
Oct 30, 2024Developing a foundation model for time series forecasting across diverse domains has attracted significant attention in recent years. Existing works typically assume regularly sampled, well-structured data, limiting their applicability to more generalized scenarios where time series often contain missing values, unequal sequence lengths, and irregular time intervals between measurements. To cover diverse domains and handle variable regularities, we propose FlexTSF, a universal time series forecasting model that possesses better generalization and natively support both regular and irregular time series. FlexTSF produces forecasts in an autoregressive manner and incorporates three novel designs: VT-Norm, a normalization strategy to ablate data domain barriers, IVP Patcher, a patching module to learn representations from flexibly structured time series, and LED attention, an attention mechanism to seamlessly integrate these two and propagate forecasts with awareness of domain and time information. Experiments on 12 datasets show that FlexTSF outperforms state-of-the-art forecasting models respectively designed for regular and irregular time series. Furthermore, after self-supervised pre-training, FlexTSF shows exceptional performance in both zero-shot and few-show settings for time series forecasting.
OEKG: The Open Event Knowledge Graph
Feb 28, 2023



Accessing and understanding contemporary and historical events of global impact such as the US elections and the Olympic Games is a major prerequisite for cross-lingual event analytics that investigate event causes, perception and consequences across country borders. In this paper, we present the Open Event Knowledge Graph (OEKG), a multilingual, event-centric, temporal knowledge graph composed of seven different data sets from multiple application domains, including question answering, entity recommendation and named entity recognition. These data sets are all integrated through an easy-to-use and robust pipeline and by linking to the event-centric knowledge graph EventKG. We describe their common schema and demonstrate the use of the OEKG at the example of three use cases: type-specific image retrieval, hybrid question answering over knowledge graphs and news articles, as well as language-specific event recommendation. The OEKG and its query endpoint are publicly available.
LaSER: Language-Specific Event Recommendation
Feb 24, 2023
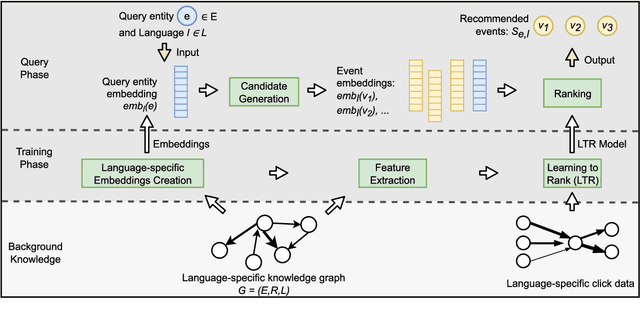
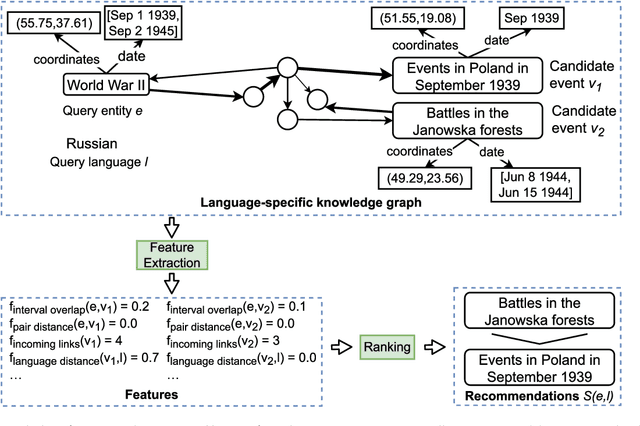

While societal events often impact people worldwide, a significant fraction of events has a local focus that primarily affects specific language communities. Examples include national elections, the development of the Coronavirus pandemic in different countries, and local film festivals such as the C\'esar Awards in France and the Moscow International Film Festival in Russia. However, existing entity recommendation approaches do not sufficiently address the language context of recommendation. This article introduces the novel task of language-specific event recommendation, which aims to recommend events relevant to the user query in the language-specific context. This task can support essential information retrieval activities, including web navigation and exploratory search, considering the language context of user information needs. We propose LaSER, a novel approach toward language-specific event recommendation. LaSER blends the language-specific latent representations (embeddings) of entities and events and spatio-temporal event features in a learning to rank model. This model is trained on publicly available Wikipedia Clickstream data. The results of our user study demonstrate that LaSER outperforms state-of-the-art recommendation baselines by up to 33 percentage points in MAP@5 concerning the language-specific relevance of recommended events.
Linking Streets in OpenStreetMap to Persons in Wikidata
Feb 24, 2023


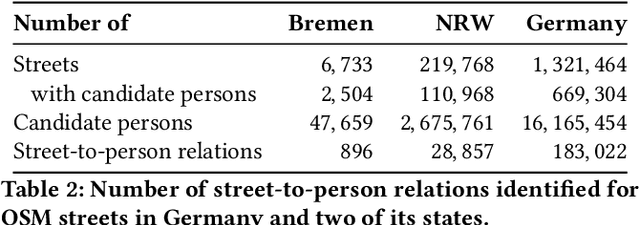
Geographic web sources such as OpenStreetMap (OSM) and knowledge graphs such as Wikidata are often unconnected. An example connection that can be established between these sources are links between streets in OSM to the persons in Wikidata they were named after. This paper presents StreetToPerson, an approach for connecting streets in OSM to persons in a knowledge graph based on relations in the knowledge graph and spatial dependencies. Our evaluation shows that we outperform existing approaches by 26 percentage points. In addition, we apply StreetToPerson on all OSM streets in Germany, for which we identify more than 180,000 links between streets and persons.