 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOEKG: The Open Event Knowledge Graph
Feb 28, 2023



Accessing and understanding contemporary and historical events of global impact such as the US elections and the Olympic Games is a major prerequisite for cross-lingual event analytics that investigate event causes, perception and consequences across country borders. In this paper, we present the Open Event Knowledge Graph (OEKG), a multilingual, event-centric, temporal knowledge graph composed of seven different data sets from multiple application domains, including question answering, entity recommendation and named entity recognition. These data sets are all integrated through an easy-to-use and robust pipeline and by linking to the event-centric knowledge graph EventKG. We describe their common schema and demonstrate the use of the OEKG at the example of three use cases: type-specific image retrieval, hybrid question answering over knowledge graphs and news articles, as well as language-specific event recommendation. The OEKG and its query endpoint are publicly available.
Building Multilingual Corpora for a Complex Named Entity Recognition and Classification Hierarchy using Wikipedia and DBpedia
Dec 14, 2022



With the ever-growing popularity of the field of NLP, the demand for datasets in low resourced-languages follows suit. Following a previously established framework, in this paper, we present the UNER dataset, a multilingual and hierarchical parallel corpus annotated for named-entities. We describe in detail the developed procedure necessary to create this type of dataset in any language available on Wikipedia with DBpedia information. The three-step procedure extracts entities from Wikipedia articles, links them to DBpedia, and maps the DBpedia sets of classes to the UNER labels. This is followed by a post-processing procedure that significantly increases the number of identified entities in the final results. The paper concludes with a statistical and qualitative analysis of the resulting dataset.
ProVe: A Pipeline for Automated Provenance Verification of Knowledge Graphs against Textual Sources
Oct 26, 2022



Knowledge Graphs are repositories of information that gather data from a multitude of domains and sources in the form of semantic triples, serving as a source of structured data for various crucial applications in the modern web landscape, from Wikipedia infoboxes to search engines. Such graphs mainly serve as secondary sources of information and depend on well-documented and verifiable provenance to ensure their trustworthiness and usability. However, their ability to systematically assess and assure the quality of this provenance, most crucially whether it properly supports the graph's information, relies mainly on manual processes that do not scale with size. ProVe aims at remedying this, consisting of a pipelined approach that automatically verifies whether a Knowledge Graph triple is supported by text extracted from its documented provenance. ProVe is intended to assist information curators and consists of four main steps involving rule-based methods and machine learning models: text extraction, triple verbalisation, sentence selection, and claim verification. ProVe is evaluated on a Wikidata dataset, achieving promising results overall and excellent performance on the binary classification task of detecting support from provenance, with 87.5% accuracy and 82.9% F1-macro on text-rich sources. The evaluation data and scripts used in this paper are available on GitHub and Figshare.
Statistical and Neural Methods for Cross-lingual Entity Label Mapping in Knowledge Graphs
Jun 17, 2022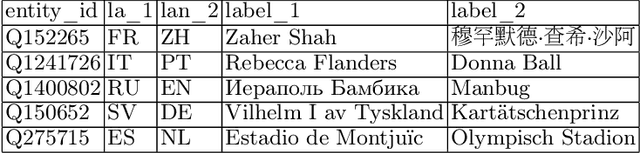
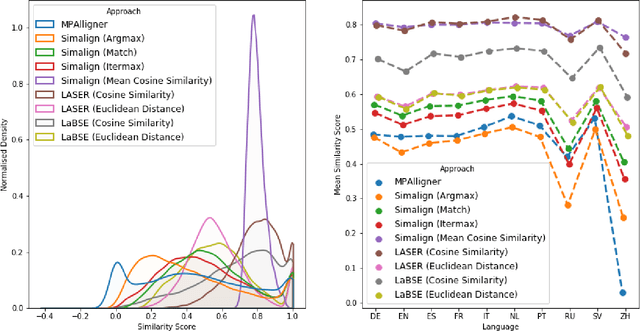
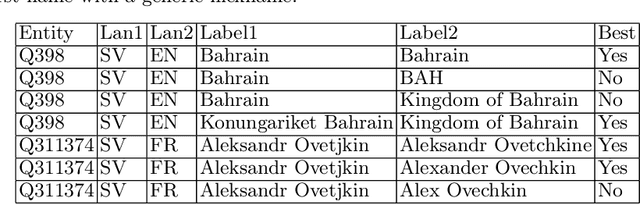
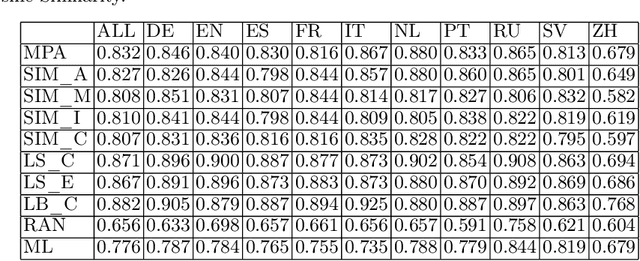
Knowledge bases such as Wikidata amass vast amounts of named entity information, such as multilingual labels, which can be extremely useful for various multilingual and cross-lingual applications. However, such labels are not guaranteed to match across languages from an information consistency standpoint, greatly compromising their usefulness for fields such as machine translation. In this work, we investigate the application of word and sentence alignment techniques coupled with a matching algorithm to align cross-lingual entity labels extracted from Wikidata in 10 languages. Our results indicate that mapping between Wikidata's main labels stands to be considerably improved (up to $20$ points in F1-score) by any of the employed methods. We show how methods relying on sentence embeddings outperform all others, even across different scripts. We believe the application of such techniques to measure the similarity of label pairs, coupled with a knowledge base rich in high-quality entity labels, to be an excellent asset to machine translation.
WDV: A Broad Data Verbalisation Dataset Built from Wikidata
May 05, 2022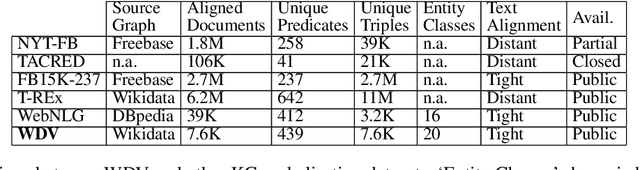
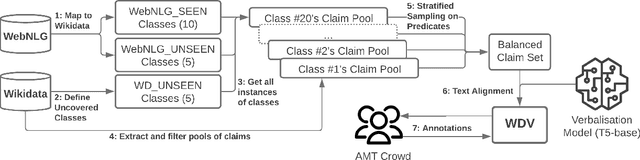
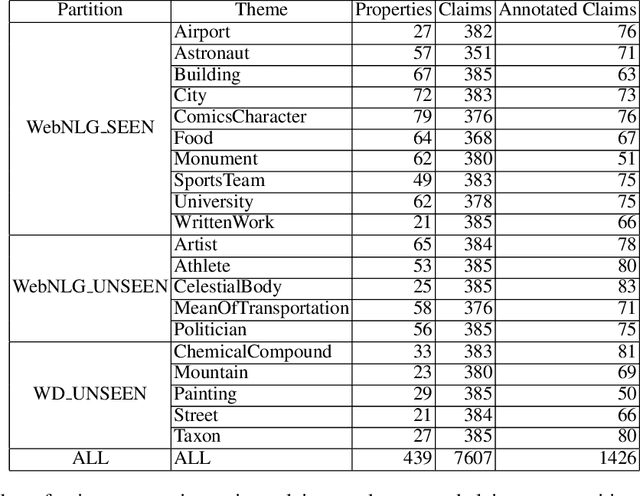
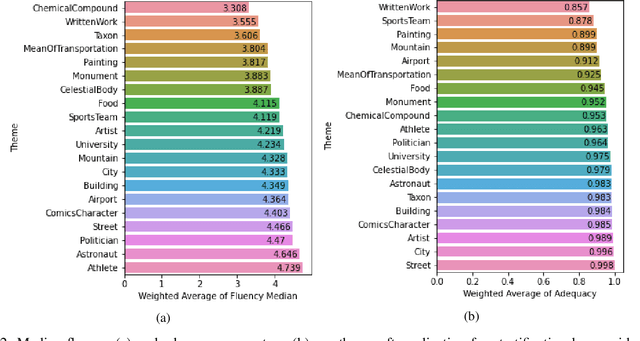
Data verbalisation is a task of great importance in the current field of natural language processing, as there is great benefit in the transformation of our abundant structured and semi-structured data into human-readable formats. Verbalising Knowledge Graph (KG) data focuses on converting interconnected triple-based claims, formed of subject, predicate, and object, into text. Although KG verbalisation datasets exist for some KGs, there are still gaps in their fitness for use in many scenarios. This is especially true for Wikidata, where available datasets either loosely couple claim sets with textual information or heavily focus on predicates around biographies, cities, and countries. To address these gaps, we propose WDV, a large KG claim verbalisation dataset built from Wikidata, with a tight coupling between triples and text, covering a wide variety of entities and predicates. We also evaluate the quality of our verbalisations through a reusable workflow for measuring human-centred fluency and adequacy scores. Our data and code are openly available in the hopes of furthering research towards KG verbalisation.
Assessing the quality of sources in Wikidata across languages: a hybrid approach
Sep 20, 2021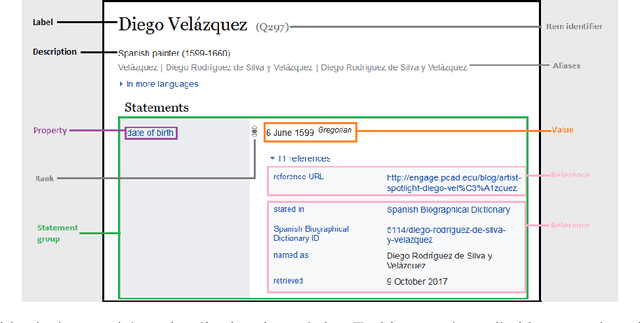
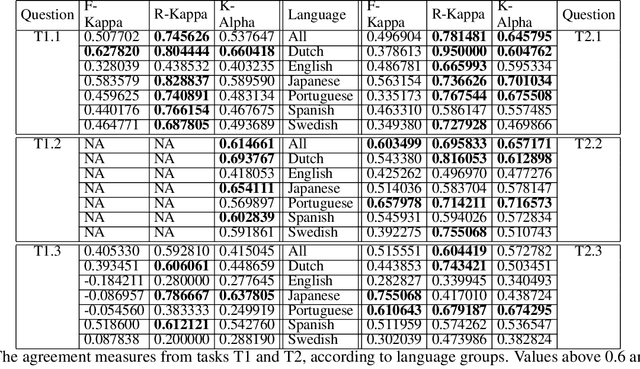
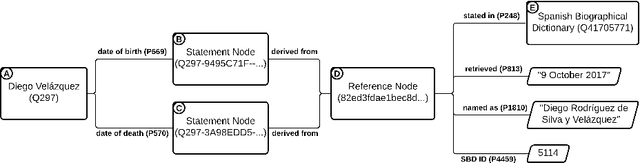
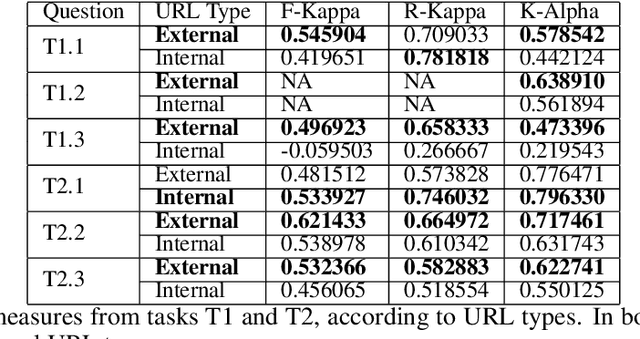
Wikidata is one of the most important sources of structured data on the web, built by a worldwide community of volunteers. As a secondary source, its contents must be backed by credible references; this is particularly important as Wikidata explicitly encourages editors to add claims for which there is no broad consensus, as long as they are corroborated by references. Nevertheless, despite this essential link between content and references, Wikidata's ability to systematically assess and assure the quality of its references remains limited. To this end, we carry out a mixed-methods study to determine the relevance, ease of access, and authoritativeness of Wikidata references, at scale and in different languages, using online crowdsourcing, descriptive statistics, and machine learning. Building on previous work of ours, we run a series of microtasks experiments to evaluate a large corpus of references, sampled from Wikidata triples with labels in several languages. We use a consolidated, curated version of the crowdsourced assessments to train several machine learning models to scale up the analysis to the whole of Wikidata. The findings help us ascertain the quality of references in Wikidata, and identify common challenges in defining and capturing the quality of user-generated multilingual structured data on the web. We also discuss ongoing editorial practices, which could encourage the use of higher-quality references in a more immediate way. All data and code used in the study are available on GitHub for feedback and further improvement and deployment by the research community.
UNER: Universal Named-Entity RecognitionFramework
Oct 23, 2020


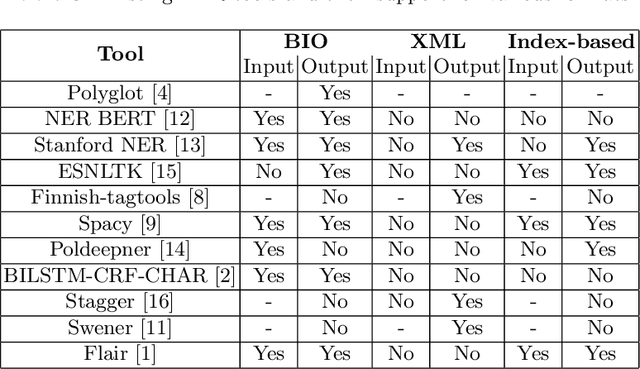
We introduce the Universal Named-Entity Recognition (UNER)framework, a 4-level classification hierarchy, and the methodology that isbeing adopted to create the first multilingual UNER corpus: the SETimesparallel corpus annotated for named-entities. First, the English SETimescorpus will be annotated using existing tools and knowledge bases. Afterevaluating the resulting annotations through crowdsourcing campaigns,they will be propagated automatically to other languages within the SE-Times corpora. Finally, as an extrinsic evaluation, the UNER multilin-gual dataset will be used to train and test available NER tools. As part offuture research directions, we aim to increase the number of languages inthe UNER corpus and to investigate possible ways of integrating UNERwith available knowledge graphs to improve named-entity recognition.