 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalizing AI: Evaluating Open-Weight Language Models for Languages of Baltic States
Jan 07, 2025



Although large language models (LLMs) have transformed our expectations of modern language technologies, concerns over data privacy often restrict the use of commercially available LLMs hosted outside of EU jurisdictions. This limits their application in governmental, defence, and other data-sensitive sectors. In this work, we evaluate the extent to which locally deployable open-weight LLMs support lesser-spoken languages such as Lithuanian, Latvian, and Estonian. We examine various size and precision variants of the top-performing multilingual open-weight models, Llama~3, Gemma~2, Phi, and NeMo, on machine translation, multiple-choice question answering, and free-form text generation. The results indicate that while certain models like Gemma~2 perform close to the top commercially available models, many LLMs struggle with these languages. Most surprisingly, however, we find that these models, while showing close to state-of-the-art translation performance, are still prone to lexical hallucinations with errors in at least 1 in 20 words for all open-weight multilingual LLMs.
From Zero to Production: Baltic-Ukrainian Machine Translation Systems to Aid Refugees
Sep 28, 2022


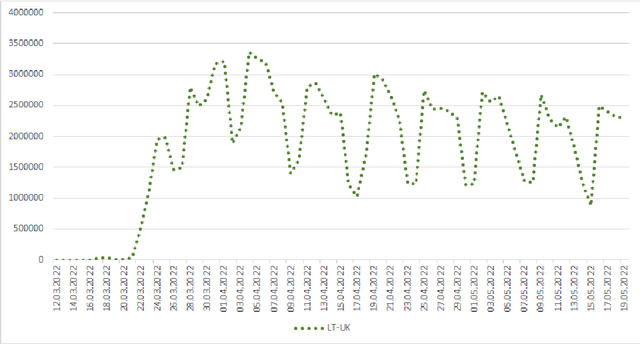
In this paper, we examine the development and usage of six low-resource machine translation systems translating between the Ukrainian language and each of the official languages of the Baltic states. We developed these systems in reaction to the escalating Ukrainian refugee crisis caused by the Russian military aggression in Ukraine in the hope that they might be helpful for refugees and public administrations. Now, two months after MT systems were made public, we analyze their usage patterns and statistics. Our findings show that the Latvian-Ukrainian and Lithuanian-Ukrainian systems are integrated into the public services of Baltic states, leading to more than 127 million translated sentences for the Lithuanian-Ukrainian system. Motivated by these findings, we further enhance our MT systems by better Ukrainian toponym translation and publish an improved version of the Lithuanian-Ukrainian system.
Open Terminology Management and Sharing Toolkit for Federation of Terminology Databases
Jul 14, 2022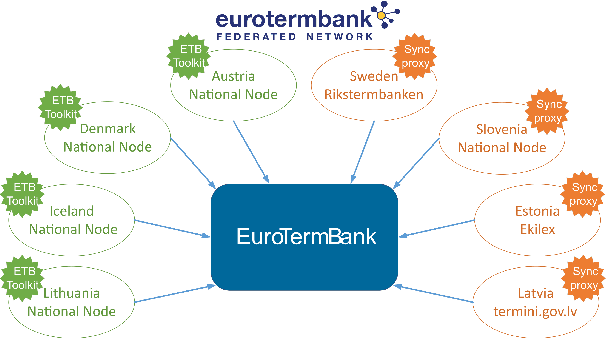
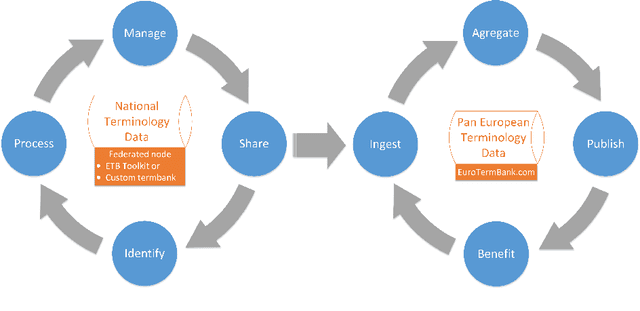
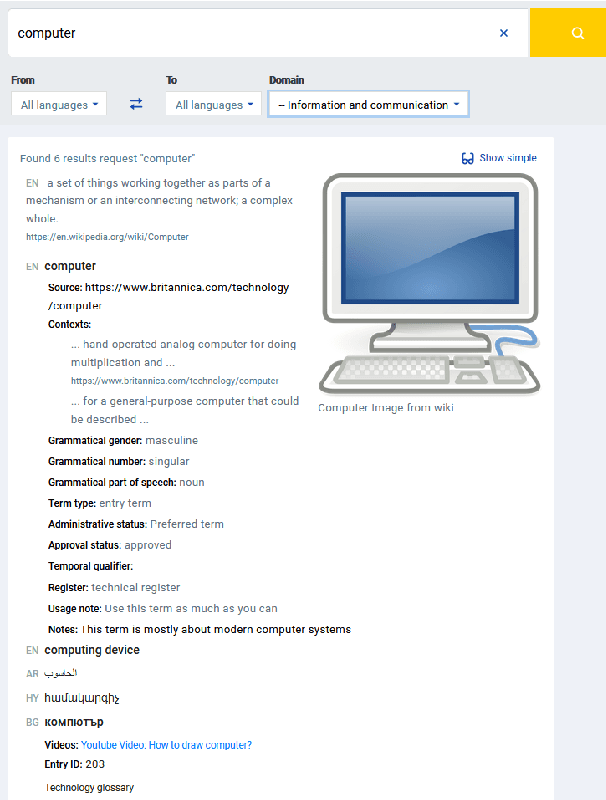
Consolidated access to current and reliable terms from different subject fields and languages is necessary for content creators and translators. Terminology is also needed in AI applications such as machine translation, speech recognition, information extraction, and other natural language processing tools. In this work, we facilitate standards-based sharing and management of terminology resources by providing an open terminology management solution - the EuroTermBank Toolkit. It allows organisations to manage and search their terms, create term collections, and share them within and outside the organisation by participating in the network of federated databases. The data curated in the federated databases are automatically shared with EuroTermBank, the largest multilingual terminology resource in Europe, allowing translators and language service providers as well as researchers and students to access terminology resources in their most current version.
Statistical and Neural Methods for Cross-lingual Entity Label Mapping in Knowledge Graphs
Jun 17, 2022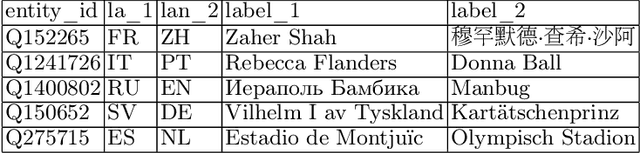
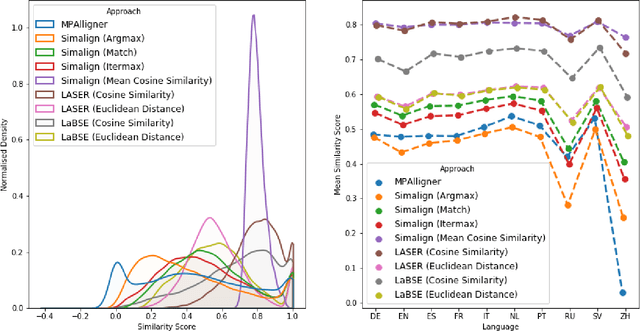
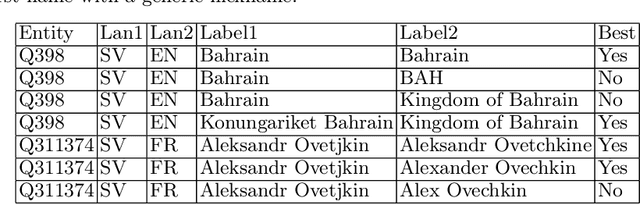
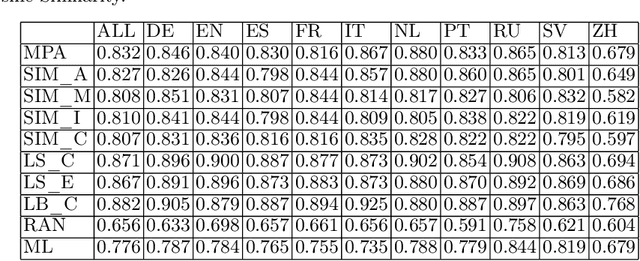
Knowledge bases such as Wikidata amass vast amounts of named entity information, such as multilingual labels, which can be extremely useful for various multilingual and cross-lingual applications. However, such labels are not guaranteed to match across languages from an information consistency standpoint, greatly compromising their usefulness for fields such as machine translation. In this work, we investigate the application of word and sentence alignment techniques coupled with a matching algorithm to align cross-lingual entity labels extracted from Wikidata in 10 languages. Our results indicate that mapping between Wikidata's main labels stands to be considerably improved (up to $20$ points in F1-score) by any of the employed methods. We show how methods relying on sentence embeddings outperform all others, even across different scripts. We believe the application of such techniques to measure the similarity of label pairs, coupled with a knowledge base rich in high-quality entity labels, to be an excellent asset to machine translation.
Dynamic Terminology Integration for COVID-19 and other Emerging Domains
Sep 10, 2021

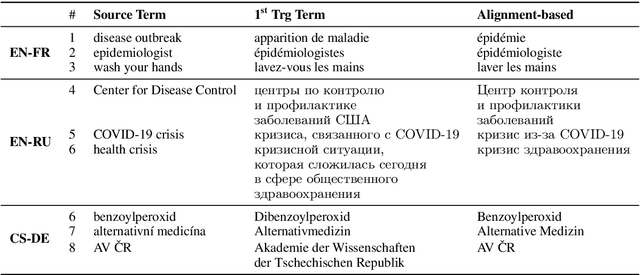

The majority of language domains require prudent use of terminology to ensure clarity and adequacy of information conveyed. While the correct use of terminology for some languages and domains can be achieved by adapting general-purpose MT systems on large volumes of in-domain parallel data, such quantities of domain-specific data are seldom available for less-resourced languages and niche domains. Furthermore, as exemplified by COVID-19 recently, no domain-specific parallel data is readily available for emerging domains. However, the gravity of this recent calamity created a high demand for reliable translation of critical information regarding pandemic and infection prevention. This work is part of WMT2021 Shared Task: Machine Translation using Terminologies, where we describe Tilde MT systems that are capable of dynamic terminology integration at the time of translation. Our systems achieve up to 94% COVID-19 term use accuracy on the test set of the EN-FR language pair without having access to any form of in-domain information during system training. We conclude our work with a broader discussion considering the Shared Task itself and terminology translation in MT.
Facilitating Terminology Translation with Target Lemma Annotations
Jan 25, 2021

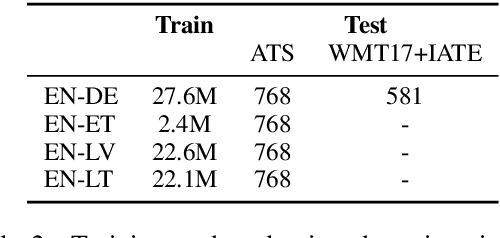

Most of the recent work on terminology integration in machine translation has assumed that terminology translations are given already inflected in forms that are suitable for the target language sentence. In day-to-day work of professional translators, however, it is seldom the case as translators work with bilingual glossaries where terms are given in their dictionary forms; finding the right target language form is part of the translation process. We argue that the requirement for apriori specified target language forms is unrealistic and impedes the practical applicability of previous work. In this work, we propose to train machine translation systems using a source-side data augmentation method that annotates randomly selected source language words with their target language lemmas. We show that systems trained on such augmented data are readily usable for terminology integration in real-life translation scenarios. Our experiments on terminology translation into the morphologically complex Baltic and Uralic languages show an improvement of up to 7 BLEU points over baseline systems with no means for terminology integration and an average improvement of 4 BLEU points over the previous work. Results of the human evaluation indicate a 47.7% absolute improvement over the previous work in term translation accuracy when translating into Latvian.
Tilde at WMT 2020: News Task Systems
Oct 29, 2020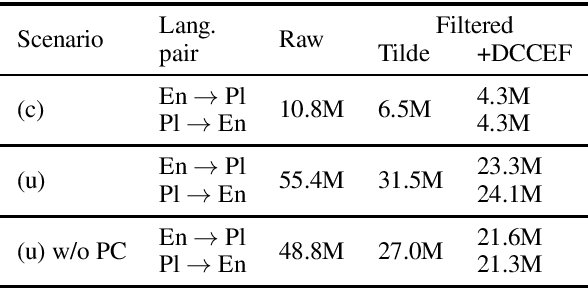
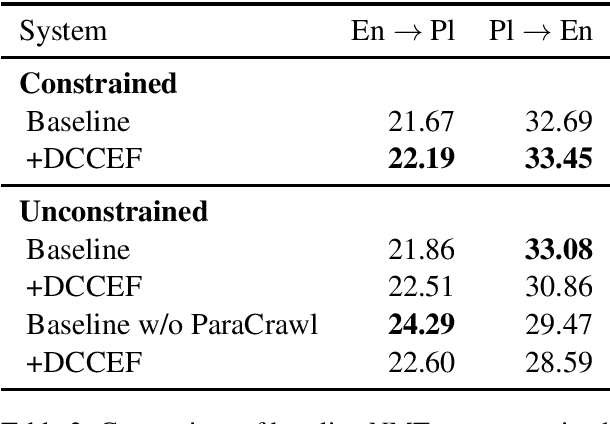
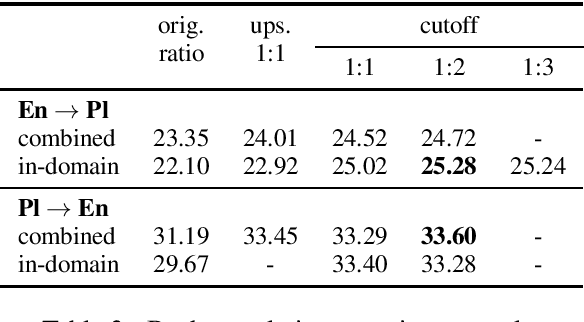
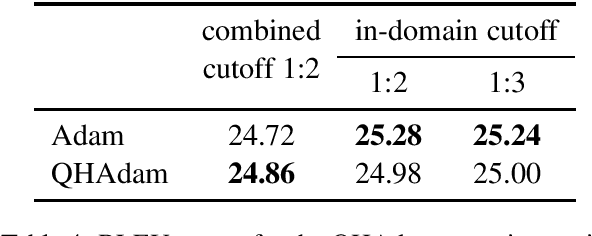
This paper describes Tilde's submission to the WMT2020 shared task on news translation for both directions of the English-Polish language pair in both the constrained and the unconstrained tracks. We follow our submissions from the previous years and build our baseline systems to be morphologically motivated sub-word unit-based Transformer base models that we train using the Marian machine translation toolkit. Additionally, we experiment with different parallel and monolingual data selection schemes, as well as sampled back-translation. Our final models are ensembles of Transformer base and Transformer big models that feature right-to-left re-ranking.
Mitigating Gender Bias in Machine Translation with Target Gender Annotations
Oct 18, 2020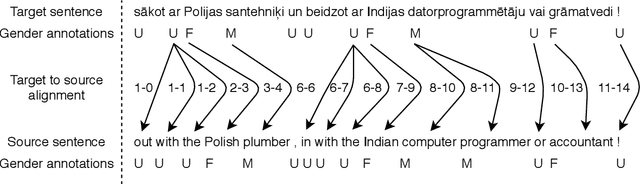
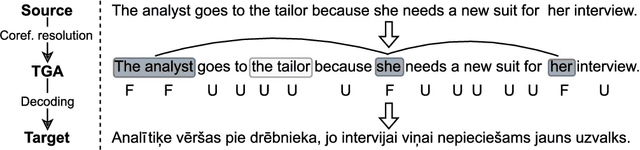
When translating "The secretary asked for details." to a language with grammatical gender, it might be necessary to determine the gender of the subject "secretary". If the sentence does not contain the necessary information, it is not always possible to disambiguate. In such cases, machine translation systems select the most common translation option, which often corresponds to the stereotypical translations, thus potentially exacerbating prejudice and marginalisation of certain groups and people. We argue that the information necessary for an adequate translation can not always be deduced from the sentence being translated or even might depend on external knowledge. Therefore, in this work, we propose to decouple the task of acquiring the necessary information from the task of learning to translate correctly when such information is available. To that end, we present a method for training machine translation systems to use word-level annotations containing information about subject's gender. To prepare training data, we annotate regular source language words with grammatical gender information of the corresponding target language words. Using such data to train machine translation systems reduces their reliance on gender stereotypes when information about the subject's gender is available. Our experiments on five language pairs show that this allows improving accuracy on the WinoMT test set by up to 25.8 percentage points.
Robust Neural Machine Translation: Modeling Orthographic and Interpunctual Variation
Sep 14, 2020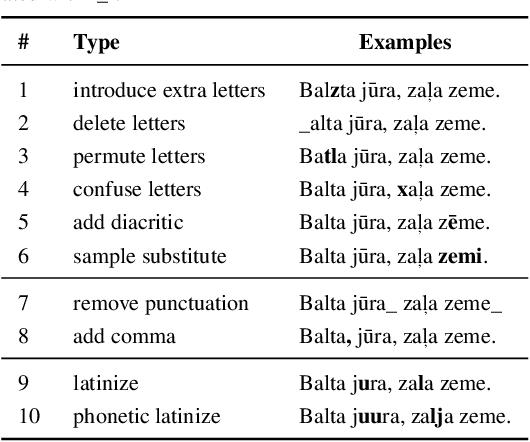


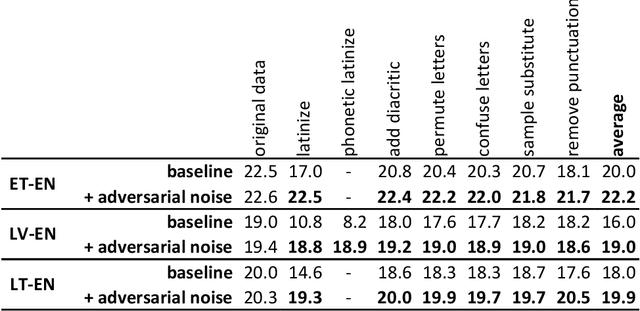
Neural machine translation systems typically are trained on curated corpora and break when faced with non-standard orthography or punctuation. Resilience to spelling mistakes and typos, however, is crucial as machine translation systems are used to translate texts of informal origins, such as chat conversations, social media posts and web pages. We propose a simple generative noise model to generate adversarial examples of ten different types. We use these to augment machine translation systems' training data and show that, when tested on noisy data, systems trained using adversarial examples perform almost as well as when translating clean data, while baseline systems' performance drops by 2-3 BLEU points. To measure the robustness and noise invariance of machine translation systems' outputs, we use the average translation edit rate between the translation of the original sentence and its noised variants. Using this measure, we show that systems trained on adversarial examples on average yield 50% consistency improvements when compared to baselines trained on clean data.