 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Gender Bias in Machine Translation with Target Gender Annotations
Oct 18, 2020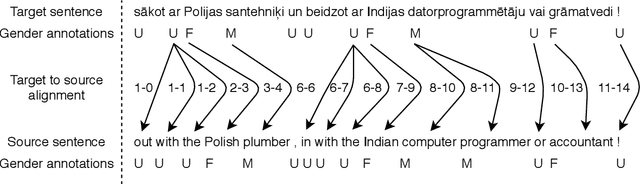
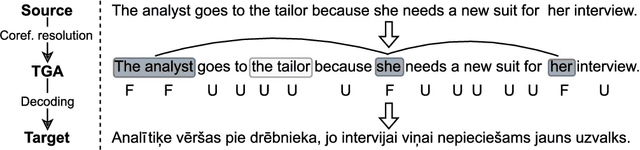
When translating "The secretary asked for details." to a language with grammatical gender, it might be necessary to determine the gender of the subject "secretary". If the sentence does not contain the necessary information, it is not always possible to disambiguate. In such cases, machine translation systems select the most common translation option, which often corresponds to the stereotypical translations, thus potentially exacerbating prejudice and marginalisation of certain groups and people. We argue that the information necessary for an adequate translation can not always be deduced from the sentence being translated or even might depend on external knowledge. Therefore, in this work, we propose to decouple the task of acquiring the necessary information from the task of learning to translate correctly when such information is available. To that end, we present a method for training machine translation systems to use word-level annotations containing information about subject's gender. To prepare training data, we annotate regular source language words with grammatical gender information of the corresponding target language words. Using such data to train machine translation systems reduces their reliance on gender stereotypes when information about the subject's gender is available. Our experiments on five language pairs show that this allows improving accuracy on the WinoMT test set by up to 25.8 percentage points.
Robust Neural Machine Translation: Modeling Orthographic and Interpunctual Variation
Sep 14, 2020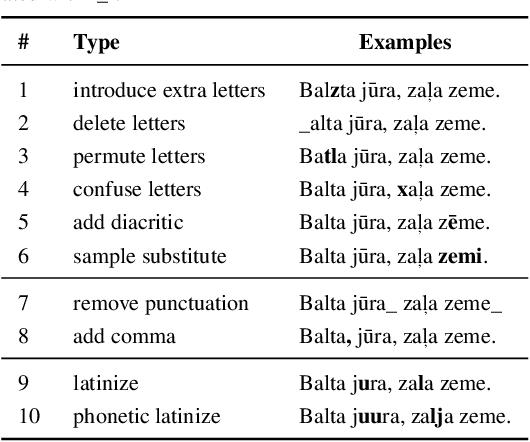


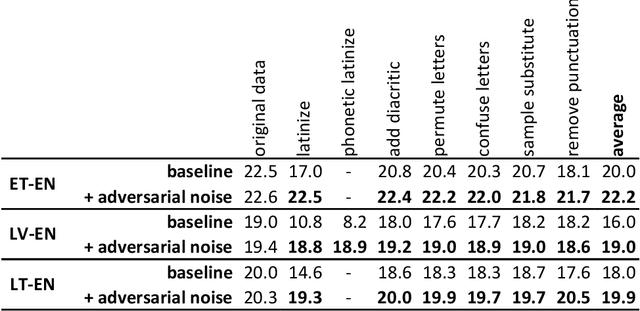
Neural machine translation systems typically are trained on curated corpora and break when faced with non-standard orthography or punctuation. Resilience to spelling mistakes and typos, however, is crucial as machine translation systems are used to translate texts of informal origins, such as chat conversations, social media posts and web pages. We propose a simple generative noise model to generate adversarial examples of ten different types. We use these to augment machine translation systems' training data and show that, when tested on noisy data, systems trained using adversarial examples perform almost as well as when translating clean data, while baseline systems' performance drops by 2-3 BLEU points. To measure the robustness and noise invariance of machine translation systems' outputs, we use the average translation edit rate between the translation of the original sentence and its noised variants. Using this measure, we show that systems trained on adversarial examples on average yield 50% consistency improvements when compared to baselines trained on clean data.