 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalizing AI: Evaluating Open-Weight Language Models for Languages of Baltic States
Jan 07, 2025



Although large language models (LLMs) have transformed our expectations of modern language technologies, concerns over data privacy often restrict the use of commercially available LLMs hosted outside of EU jurisdictions. This limits their application in governmental, defence, and other data-sensitive sectors. In this work, we evaluate the extent to which locally deployable open-weight LLMs support lesser-spoken languages such as Lithuanian, Latvian, and Estonian. We examine various size and precision variants of the top-performing multilingual open-weight models, Llama~3, Gemma~2, Phi, and NeMo, on machine translation, multiple-choice question answering, and free-form text generation. The results indicate that while certain models like Gemma~2 perform close to the top commercially available models, many LLMs struggle with these languages. Most surprisingly, however, we find that these models, while showing close to state-of-the-art translation performance, are still prone to lexical hallucinations with errors in at least 1 in 20 words for all open-weight multilingual LLMs.
Correcting diacritics and typos with ByT5 transformer model
Jan 31, 2022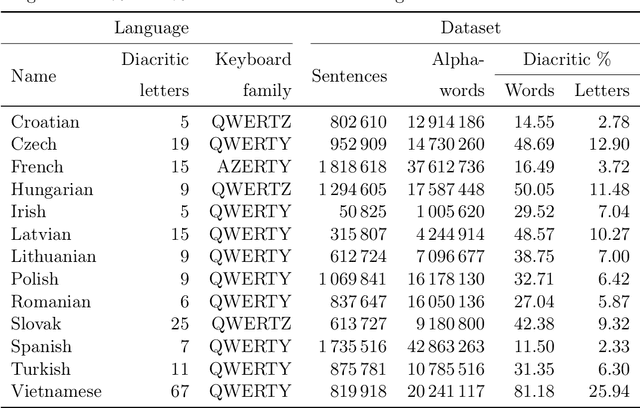
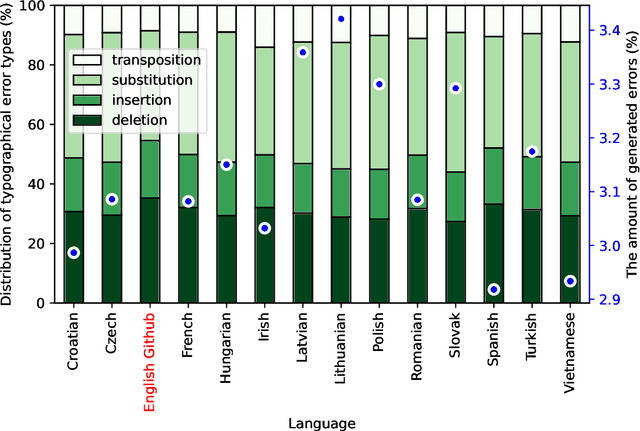

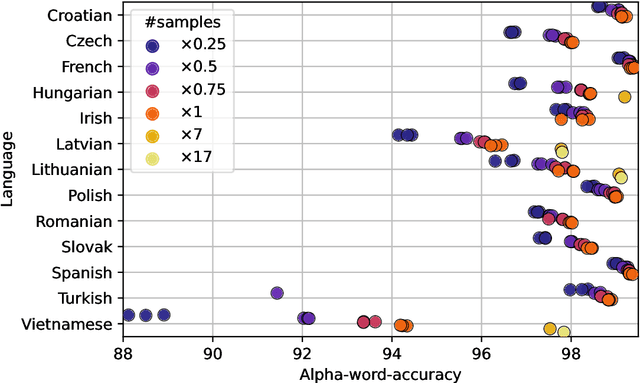
Due to the fast pace of life and online communications, the prevalence of English and the QWERTY keyboard, people tend to forgo using diacritics, make typographical errors (typos) when typing. Restoring diacritics and correcting spelling is important for proper language use and disambiguation of texts for both humans and downstream algorithms. However, both of these problems are typically addressed separately, i.e., state-of-the-art diacritics restoration methods do not tolerate other typos. In this work, we tackle both problems at once by employing newly-developed ByT5 byte-level transformer models. Our simultaneous diacritics restoration and typos correction approach demonstrates near state-of-the-art performance in 13 languages, reaching >96% of the alpha-word accuracy. We also perform diacritics restoration alone on 12 benchmark datasets with the additional one for the Lithuanian language. The experimental investigation proves that our approach is able to achieve comparable results (>98%) to previously reported despite being trained on fewer data. Our approach is also able to restore diacritics in words not seen during training with >76% accuracy. We also show the accuracies to further improve with longer training. All this shows a great real-world application potential of our suggested methods to more data, languages, and error classes.