 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Sentence Embeddings from Pretrained Transformer Models
Aug 15, 2024
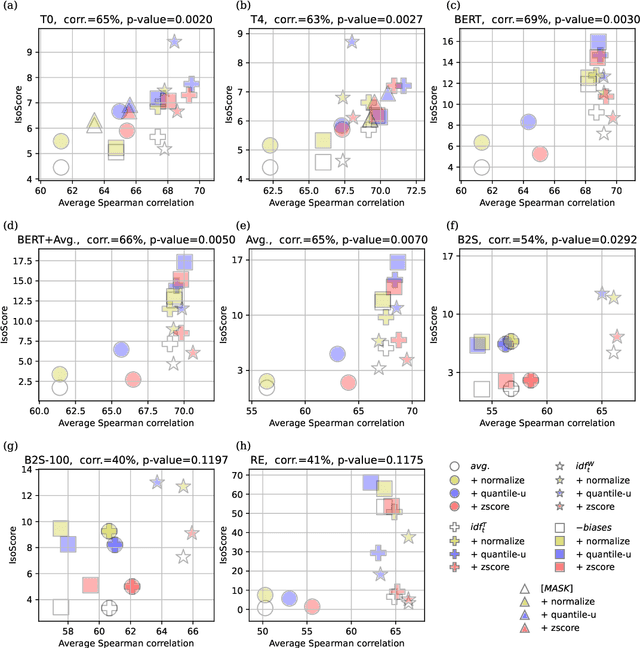


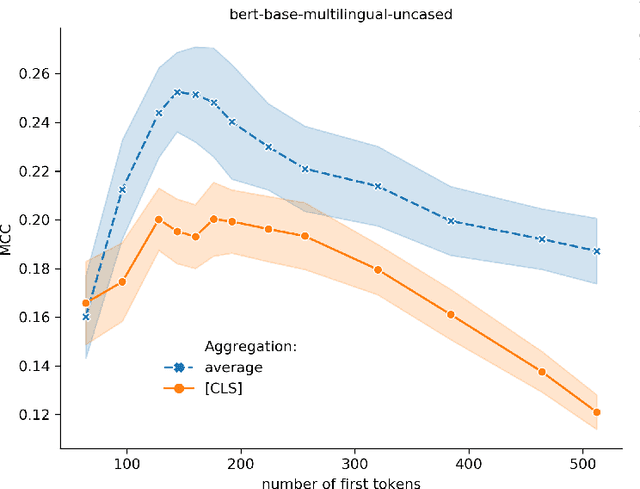
Background/introduction: Pre-trained transformer models shine in many natural language processing tasks and therefore are expected to bear the representation of the input sentence or text meaning. These sentence-level embeddings are also important in retrieval-augmented generation. But do commonly used plain averaging or prompt templates surface it enough? Methods: Given 110M parameters BERT's hidden representations from multiple layers and multiple tokens we tried various ways to extract optimal sentence representations. We tested various token aggregation and representation post-processing techniques. We also tested multiple ways of using a general Wikitext dataset to complement BERTs sentence representations. All methods were tested on 8 Semantic Textual Similarity (STS), 6 short text clustering, and 12 classification tasks. We also evaluated our representation-shaping techniques on other static models, including random token representations. Results: Proposed representation extraction methods improved the performance on STS and clustering tasks for all models considered. Very high improvements for static token-based models, especially random embeddings for STS tasks almost reach the performance of BERT-derived representations. Conclusions: Our work shows that for multiple tasks simple baselines with representation shaping techniques reach or even outperform more complex BERT-based models or are able to contribute to their performance.
Sentiment Analysis of Lithuanian Online Reviews Using Large Language Models
Jul 29, 2024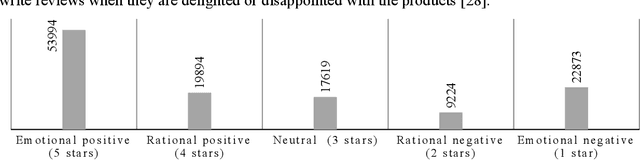



Sentiment analysis is a widely researched area within Natural Language Processing (NLP), attracting significant interest due to the advent of automated solutions. Despite this, the task remains challenging because of the inherent complexity of languages and the subjective nature of sentiments. It is even more challenging for less-studied and less-resourced languages such as Lithuanian. Our review of existing Lithuanian NLP research reveals that traditional machine learning methods and classification algorithms have limited effectiveness for the task. In this work, we address sentiment analysis of Lithuanian five-star-based online reviews from multiple domains that we collect and clean. We apply transformer models to this task for the first time, exploring the capabilities of pre-trained multilingual Large Language Models (LLMs), specifically focusing on fine-tuning BERT and T5 models. Given the inherent difficulty of the task, the fine-tuned models perform quite well, especially when the sentiments themselves are less ambiguous: 80.74% and 89.61% testing recognition accuracy of the most popular one- and five-star reviews respectively. They significantly outperform current commercial state-of-the-art general-purpose LLM GPT-4. We openly share our fine-tuned LLMs online.
Towards Lithuanian grammatical error correction
Mar 18, 2022
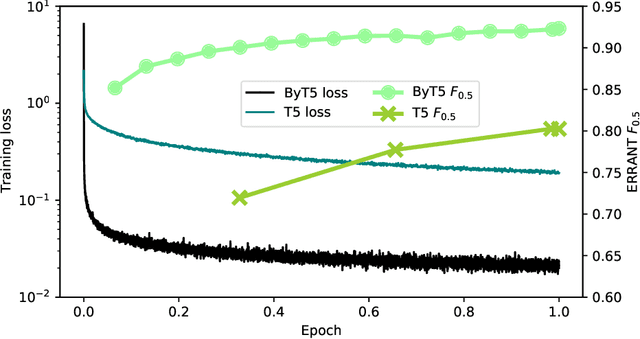
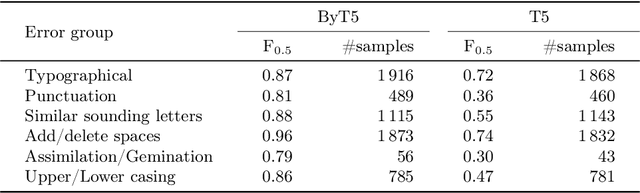
Everyone wants to write beautiful and correct text, yet the lack of language skills, experience, or hasty typing can result in errors. By employing the recent advances in transformer architectures, we construct a grammatical error correction model for Lithuanian, the language rich in archaic features. We compare subword and byte-level approaches and share our best trained model, achieving F$_{0.5}$=0.92, and accompanying code, in an online open-source repository.
Correcting diacritics and typos with ByT5 transformer model
Jan 31, 2022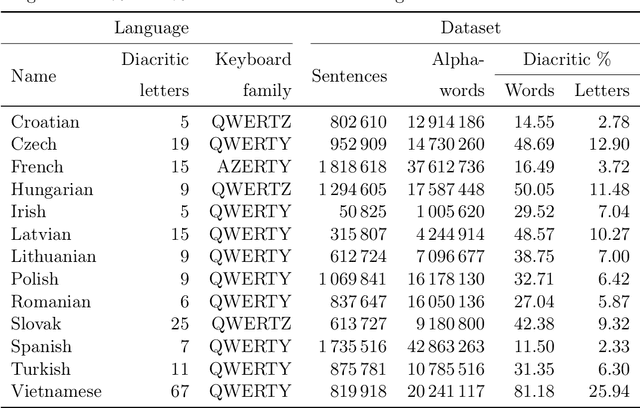
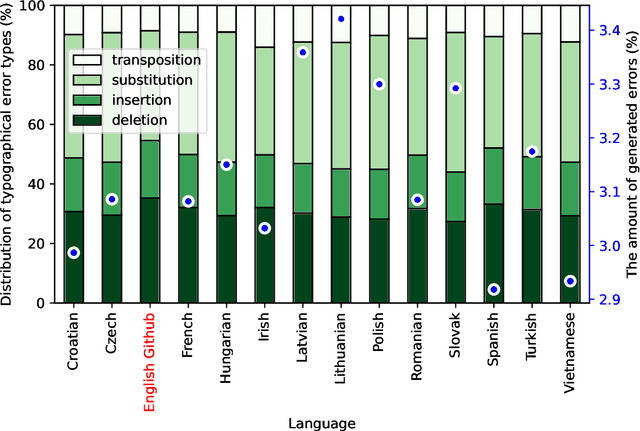

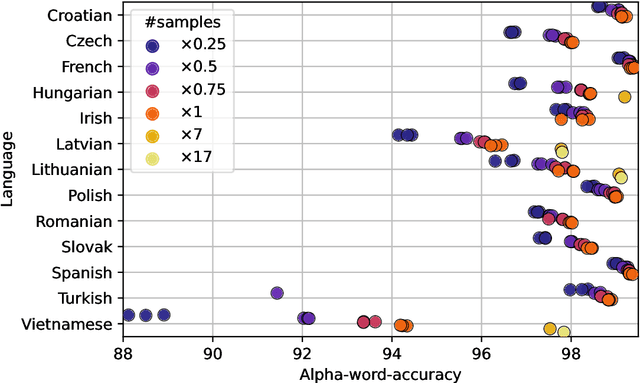
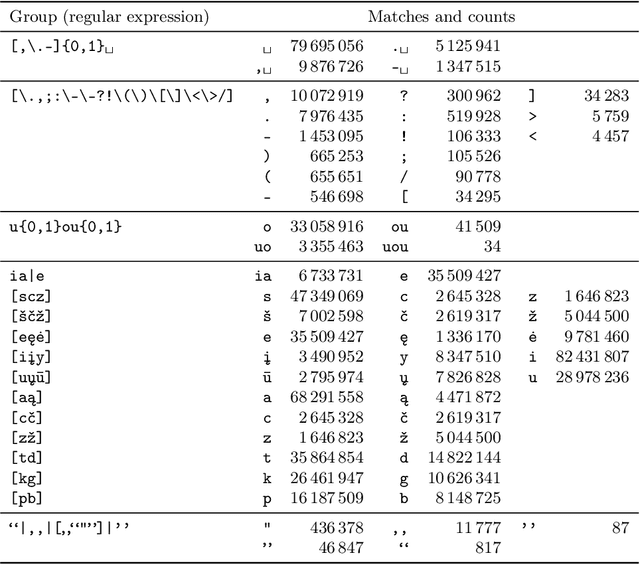
Due to the fast pace of life and online communications, the prevalence of English and the QWERTY keyboard, people tend to forgo using diacritics, make typographical errors (typos) when typing. Restoring diacritics and correcting spelling is important for proper language use and disambiguation of texts for both humans and downstream algorithms. However, both of these problems are typically addressed separately, i.e., state-of-the-art diacritics restoration methods do not tolerate other typos. In this work, we tackle both problems at once by employing newly-developed ByT5 byte-level transformer models. Our simultaneous diacritics restoration and typos correction approach demonstrates near state-of-the-art performance in 13 languages, reaching >96% of the alpha-word accuracy. We also perform diacritics restoration alone on 12 benchmark datasets with the additional one for the Lithuanian language. The experimental investigation proves that our approach is able to achieve comparable results (>98%) to previously reported despite being trained on fewer data. Our approach is also able to restore diacritics in words not seen during training with >76% accuracy. We also show the accuracies to further improve with longer training. All this shows a great real-world application potential of our suggested methods to more data, languages, and error classes.
Generating abstractive summaries of Lithuanian news articles using a transformer model
Apr 23, 2021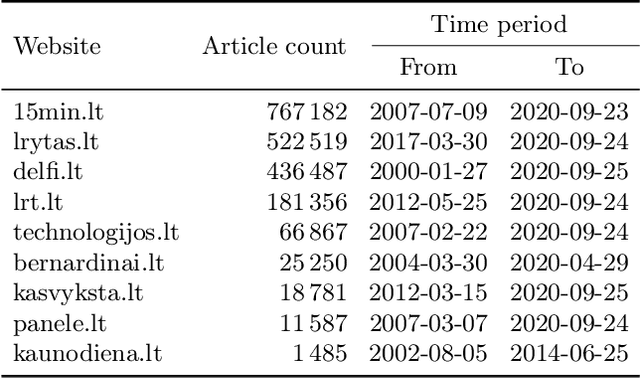
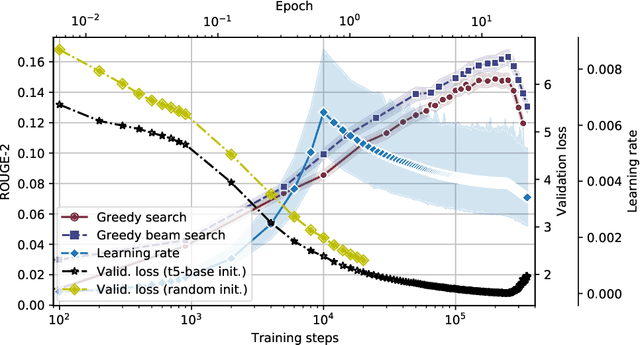
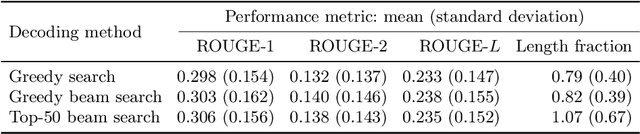
In this work, we train the first monolingual Lithuanian transformer model on a relatively large corpus of Lithuanian news articles and compare various output decoding algorithms for abstractive news summarization. Generated summaries are coherent and look impressive at the first glance. However, some of them contain misleading information that is not so easy to spot. We describe all the technical details and share our trained model and accompanying code in an online open-source repository, as well as some characteristic samples of the generated summaries.
Testing pre-trained Transformer models for Lithuanian news clustering
Apr 03, 2020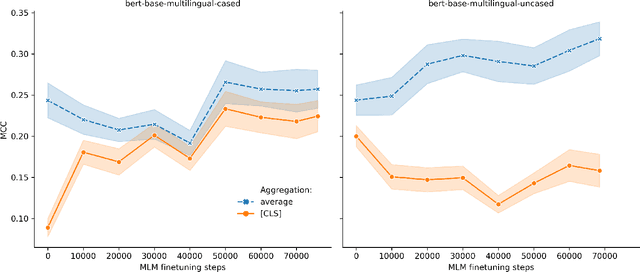

A recent introduction of Transformer deep learning architecture made breakthroughs in various natural language processing tasks. However, non-English languages could not leverage such new opportunities with the English text pre-trained models. This changed with research focusing on multilingual models, where less-spoken languages are the main beneficiaries. We compare pre-trained multilingual BERT, XLM-R, and older learned text representation methods as encodings for the task of Lithuanian news clustering. Our results indicate that publicly available pre-trained multilingual Transformer models can be fine-tuned to surpass word vectors but still score much lower than specially trained doc2vec embeddings.