 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeywords are not always the key: A metadata field analysis for natural language search on open data portals
Sep 17, 2025Open data portals are essential for providing public access to open datasets. However, their search interfaces typically rely on keyword-based mechanisms and a narrow set of metadata fields. This design makes it difficult for users to find datasets using natural language queries. The problem is worsened by metadata that is often incomplete or inconsistent, especially when users lack familiarity with domain-specific terminology. In this paper, we examine how individual metadata fields affect the success of conversational dataset retrieval and whether LLMs can help bridge the gap between natural queries and structured metadata. We conduct a controlled ablation study using simulated natural language queries over real-world datasets to evaluate retrieval performance under various metadata configurations. We also compare existing content of the metadata field 'description' with LLM-generated content, exploring how different prompting strategies influence quality and impact on search outcomes. Our findings suggest that dataset descriptions play a central role in aligning with user intent, and that LLM-generated descriptions can support effective retrieval. These results highlight both the limitations of current metadata practices and the potential of generative models to improve dataset discoverability in open data portals.
Schema Generation for Large Knowledge Graphs Using Large Language Models
Jun 04, 2025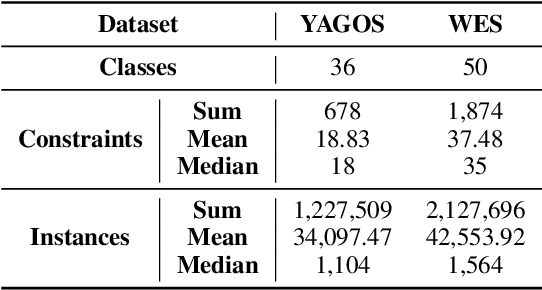
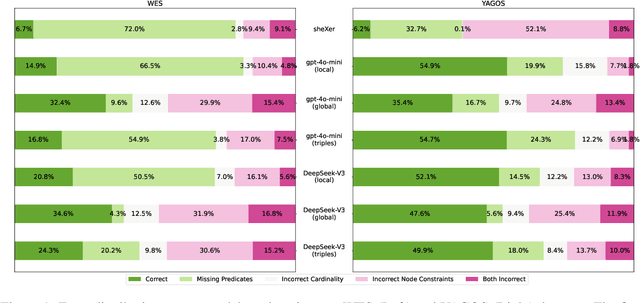
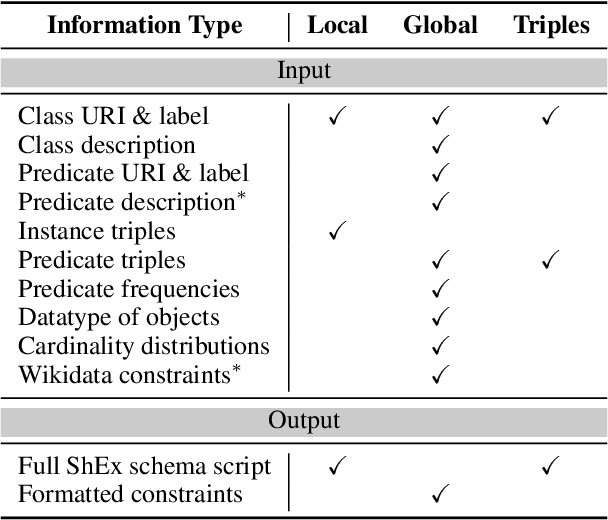

Schemas are vital for ensuring data quality in the Semantic Web and natural language processing. Traditionally, their creation demands substantial involvement from knowledge engineers and domain experts. Leveraging the impressive capabilities of large language models (LLMs) in related tasks like ontology engineering, we explore automatic schema generation using LLMs. To bridge the resource gap, we introduce two datasets: YAGO Schema and Wikidata EntitySchema, along with evaluation metrics. The LLM-based pipelines effectively utilize local and global information from knowledge graphs (KGs) to generate validating schemas in Shape Expressions (ShEx). Experiments demonstrate LLMs' strong potential in producing high-quality ShEx schemas, paving the way for scalable, automated schema generation for large KGs. Furthermore, our benchmark introduces a new challenge for structured generation, pushing the limits of LLMs on syntactically rich formalisms.
PathE: Leveraging Entity-Agnostic Paths for Parameter-Efficient Knowledge Graph Embeddings
Jan 31, 2025Knowledge Graphs (KGs) store human knowledge in the form of entities (nodes) and relations, and are used extensively in various applications. KG embeddings are an effective approach to addressing tasks like knowledge discovery, link prediction, and reasoning. This is often done by allocating and learning embedding tables for all or a subset of the entities. As this scales linearly with the number of entities, learning embedding models in real-world KGs with millions of nodes can be computationally intractable. To address this scalability problem, our model, PathE, only allocates embedding tables for relations (which are typically orders of magnitude fewer than the entities) and requires less than 25% of the parameters of previous parameter efficient methods. Rather than storing entity embeddings, we learn to compute them by leveraging multiple entity-relation paths to contextualise individual entities within triples. Evaluated on four benchmarks, PathE achieves state-of-the-art performance in relation prediction, and remains competitive in link prediction on path-rich KGs while training on consumer-grade hardware. We perform ablation experiments to test our design choices and analyse the sensitivity of the model to key hyper-parameters. PathE is efficient and cost-effective for relationally diverse and well-connected KGs commonly found in real-world applications.
Croissant: A Metadata Format for ML-Ready Datasets
Mar 28, 2024Data is a critical resource for Machine Learning (ML), yet working with data remains a key friction point. This paper introduces Croissant, a metadata format for datasets that simplifies how data is used by ML tools and frameworks. Croissant makes datasets more discoverable, portable and interoperable, thereby addressing significant challenges in ML data management and responsible AI. Croissant is already supported by several popular dataset repositories, spanning hundreds of thousands of datasets, ready to be loaded into the most popular ML frameworks.
A Comparative Analysis of Conversational Large Language Models in Knowledge-Based Text Generation
Feb 02, 2024Generating natural language text from graph-structured data is essential for conversational information seeking. Semantic triples derived from knowledge graphs can serve as a valuable source for grounding responses from conversational agents by providing a factual basis for the information they communicate. This is especially relevant in the context of large language models, which offer great potential for conversational interaction but are prone to hallucinating, omitting, or producing conflicting information. In this study, we conduct an empirical analysis of conversational large language models in generating natural language text from semantic triples. We compare four large language models of varying sizes with different prompting techniques. Through a series of benchmark experiments on the WebNLG dataset, we analyze the models' performance and identify the most common issues in the generated predictions. Our findings show that the capabilities of large language models in triple verbalization can be significantly improved through few-shot prompting, post-processing, and efficient fine-tuning techniques, particularly for smaller models that exhibit lower zero-shot performance.
Evaluating Large Language Models in Semantic Parsing for Conversational Question Answering over Knowledge Graphs
Jan 03, 2024Conversational question answering systems often rely on semantic parsing to enable interactive information retrieval, which involves the generation of structured database queries from a natural language input. For information-seeking conversations about facts stored within a knowledge graph, dialogue utterances are transformed into graph queries in a process that is called knowledge-based conversational question answering. This paper evaluates the performance of large language models that have not been explicitly pre-trained on this task. Through a series of experiments on an extensive benchmark dataset, we compare models of varying sizes with different prompting techniques and identify common issue types in the generated output. Our results demonstrate that large language models are capable of generating graph queries from dialogues, with significant improvements achievable through few-shot prompting and fine-tuning techniques, especially for smaller models that exhibit lower zero-shot performance.
ChartCheck: An Evidence-Based Fact-Checking Dataset over Real-World Chart Images
Nov 13, 2023Data visualizations are common in the real-world. We often use them in data sources such as scientific documents, news articles, textbooks, and social media to summarize key information in a visual form. Charts can also mislead its audience by communicating false information or biasing them towards a specific agenda. Verifying claims against charts is not a straightforward process. It requires analyzing both the text and visual components of the chart, considering characteristics such as colors, positions, and orientations. Moreover, to determine if a claim is supported by the chart content often requires different types of reasoning. To address this challenge, we introduce ChartCheck, a novel dataset for fact-checking against chart images. ChartCheck is the first large-scale dataset with 1.7k real-world charts and 10.5k human-written claims and explanations. We evaluated the dataset on state-of-the-art models and achieved an accuracy of 73.9 in the finetuned setting. Additionally, we identified chart characteristics and reasoning types that challenge the models.
Exploring the Numerical Reasoning Capabilities of Language Models: A Comprehensive Analysis on Tabular Data
Nov 03, 2023Numbers are crucial for various real-world domains such as finance, economics, and science. Thus, understanding and reasoning with numbers are essential skills for language models to solve different tasks. While different numerical benchmarks have been introduced in recent years, they are limited to specific numerical aspects mostly. In this paper, we propose a hierarchical taxonomy for numerical reasoning skills with more than ten reasoning types across four levels: representation, number sense, manipulation, and complex reasoning. We conduct a comprehensive evaluation of state-of-the-art models to identify reasoning challenges specific to them. Henceforth, we develop a diverse set of numerical probes employing a semi-automated approach. We focus on the tabular Natural Language Inference (TNLI) task as a case study and measure models' performance shifts. Our results show that no model consistently excels across all numerical reasoning types. Among the probed models, FlanT5 (few-/zero-shot) and GPT-3.5 (few-shot) demonstrate strong overall numerical reasoning skills compared to other models. Label-flipping probes indicate that models often exploit dataset artifacts to predict the correct labels.
Using Large Language Models for Knowledge Engineering (LLMKE): A Case Study on Wikidata
Sep 15, 2023In this work, we explore the use of Large Language Models (LLMs) for knowledge engineering tasks in the context of the ISWC 2023 LM-KBC Challenge. For this task, given subject and relation pairs sourced from Wikidata, we utilize pre-trained LLMs to produce the relevant objects in string format and link them to their respective Wikidata QIDs. We developed a pipeline using LLMs for Knowledge Engineering (LLMKE), combining knowledge probing and Wikidata entity mapping. The method achieved a macro-averaged F1-score of 0.701 across the properties, with the scores varying from 1.00 to 0.328. These results demonstrate that the knowledge of LLMs varies significantly depending on the domain and that further experimentation is required to determine the circumstances under which LLMs can be used for automatic Knowledge Base (e.g., Wikidata) completion and correction. The investigation of the results also suggests the promising contribution of LLMs in collaborative knowledge engineering. LLMKE won Track 2 of the challenge. The implementation is available at https://github.com/bohuizhang/LLMKE.
Reading and Reasoning over Chart Images for Evidence-based Automated Fact-Checking
Jan 27, 2023Evidence data for automated fact-checking (AFC) can be in multiple modalities such as text, tables, images, audio, or video. While there is increasing interest in using images for AFC, previous works mostly focus on detecting manipulated or fake images. We propose a novel task, chart-based fact-checking, and introduce ChartBERT as the first model for AFC against chart evidence. ChartBERT leverages textual, structural and visual information of charts to determine the veracity of textual claims. For evaluation, we create ChartFC, a new dataset of 15, 886 charts. We systematically evaluate 75 different vision-language (VL) baselines and show that ChartBERT outperforms VL models, achieving 63.8% accuracy. Our results suggest that the task is complex yet feasible, with many challenges ahead.